Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
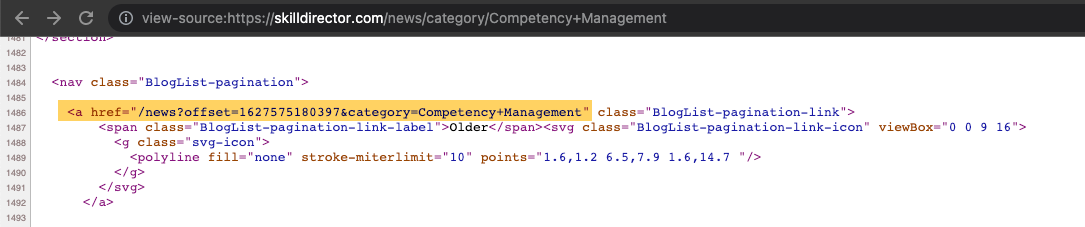
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Crawler was not able to access the robots.txt
I'm trying to setup a campaign for jessicamoraninteriors.com and I keep getting messages that Moz can't crawl the site because it can't access the robots.txt. Not sure why, other crawlers don't seem to have a problem and I can access the robots.txt file from my browser. For some additional info, it's a SquareSpace site and my DNS is handled through Cloudflare. Here's the contents of my robots.txt file: # Squarespace Robots Txt User-agent: GPTBot User-agent: ChatGPT-User User-agent: CCBot User-agent: anthropic-ai User-agent: Google-Extended User-agent: FacebookBot User-agent: Claude-Web User-agent: cohere-ai User-agent: PerplexityBot User-agent: Applebot-Extended User-agent: AdsBot-Google User-agent: AdsBot-Google-Mobile User-agent: AdsBot-Google-Mobile-Apps User-agent: * Disallow: /config Disallow: /search Disallow: /account$ Disallow: /account/ Disallow: /commerce/digital-download/ Disallow: /api/ Allow: /api/ui-extensions/ Disallow: /static/ Disallow:/*?author=* Disallow:/*&author=* Disallow:/*?tag=* Disallow:/*&tag=* Disallow:/*?month=* Disallow:/*&month=* Disallow:/*?view=* Disallow:/*&view=* Disallow:/*?format=json Disallow:/*&format=json Disallow:/*?format=page-context Disallow:/*&format=page-context Disallow:/*?format=main-content Disallow:/*&format=main-content Disallow:/*?format=json-pretty Disallow:/*&format=json-pretty Disallow:/*?format=ical Disallow:/*&format=ical Disallow:/*?reversePaginate=* Disallow:/*&reversePaginate=* Any ideas?
Getting Started | | andrewrench0 -

Added a canonical ref tag and SERPs tanked, should we change it back?
My client's CMS uses an internal linking structure that includes index.php at the end of the URLs. The site also works using SEO-friendly URLs without index.php, so the SEO tool identified a duplicate content issue. Their marketing team thought the pages with index.php would have better link equity and rank higher, so they added a canonical ref tag, making the index.php version of the pages the canonical page. As a result, the site dropped in the rankings by a LOT and has not recovered in the last 3-months. It appears that Google had automatically selected the SEO-friendly URLs as the canonical page, and by switching, it re-indexed the entire site. The question we have is, should they change it back? Or will this cause the site to be reindexed again, resulting in an even lower ranking?
Technical SEO | | TienB240 -

Unsolved Moz can't crawl my site
Moz is being blocked from crawling the following site - https://www.cleanchain.com. When looking at Robot.txt, the following is disallowing access but don't know whether this is preventing Moz from crawling too? User-agent: *
Moz Pro | | danhart2020
Disallow: /adeci/
Disallow: /core/
Disallow: /connectors/
Disallow: /assets/components/ Could something else be preventing the crawl?0 -

Unsolved Performance Metrics crawl error
I am getting an error:
Product Support | | bhsiao 0
Crawl Error for mobile & desktop page crawl - The page returned a 4xx; Lighthouse could not analyze this page.
I have Lighthouse whitelisted, is there any other site I need to whitelist? Anything else I need to do in Cloudflare or Datadome to allow this tool to work?1 -

Site Crawl 4xx Errors?
Hello! When I check our website's critical crawler issues with Moz Site Crawler, I'm seeing over 1000 pages with a 4xx error. All of the pages that are showing to have a 4xx error appear to be the brand and product pages we have on our website, but with /URL at the end of each permalink. For example, we have a page on our site for a brand called Davinci. The URL is https://kannakart.com/davinci/. In the site crawler, I'm seeing the 4xx for this URL: https://kannakart.com/davinci/URL. Could this be a plugin on our site that is generating these URLs? If they're going to be an issue, I'd like to remove them. However, I'm not sure exactly where to begin. Thanks in advance for the help, -Andrew
Moz Pro | | mostcg0 -

WWW used in research URL, or not to WWW
Long time user, infrequent poster.... thanks for taking my question... When I go to gather a series of data elements on a company's URL, the data changes (sometime dramatically) depending on whether the 'www.' is added to the URL & it seems related more to Page data than Domain. My question is about which data I should be using to assess the real strength of the site / page? Is there a 'best practice' question here, a personal preference or is there an actual difference in the performance of the www vs the non-www version? aquGYdz
Moz Pro | | SWGroves0 -

Do we get "Removal of "nofollow" from first custom URL on profile" when we cross 200 Moz Points? I have not received it yet, anything I can do?
Though I have only recently subscribed to Moz Pro, I have been using Moz Blog for quite some time. I recently crossed 200 Moz Points. As per Moz Points, it says "Removal of "nofollow" from first custom URL on profile" for crossing 200 points. I still dont see any links from Moz when I am using OSE. Can anyone suggest what i need to do?
Moz Pro | | vinodh-spintadigital2 -

How do I get the Page Authority of individual URLs in my exported (CSV) crawl reports?
I need to prioritize fixes somehow. It seems the best way to do this would be to filter my exported crawl report by the Page Authority of each URL with an error/issue. However, Page Authority doesn't seem to be included in the crawl report's CSV file. Am I missing something?
Moz Pro | | Twilio0