After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Unsolved Rogerbot blocked by cloudflare and not display full user agent string.
-
Hi,
We're trying to get MOZ to crawl our site, but when we Create Your Campaign we get the error:
Ooops. Our crawlers are unable to access that URL - please check to make sure it is correct. If the issue persists, check out this article for further help.robot.txt is fine and we actually see cloudflare is blocking it with block fight mode. We've added in some rules to allow rogerbot but these seem to be getting ignored. If we use a robot.txt test tool (https://technicalseo.com/tools/robots-txt/) with rogerbot as the user agent this get through fine and we can see our rule has allowed it.
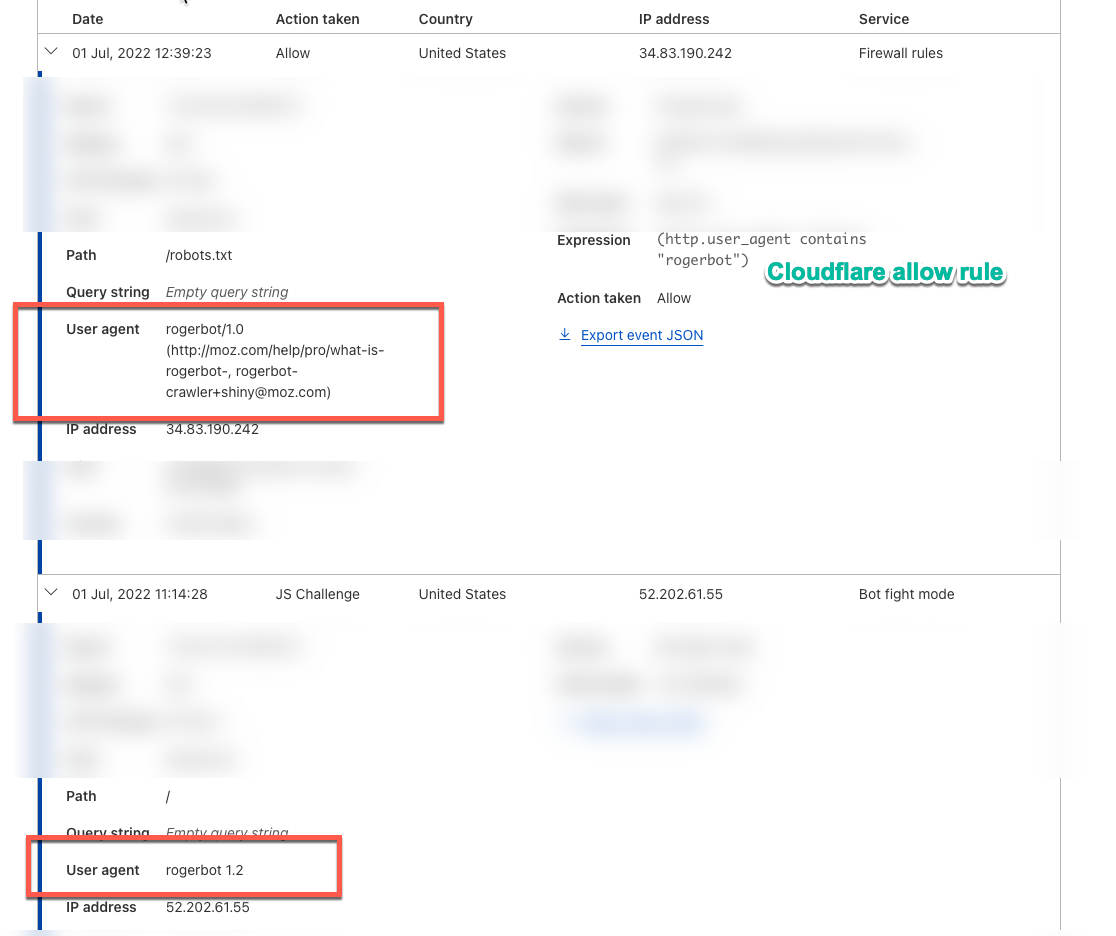
When viewing the cloudflare activity log (attached) it seems the Create Your Campaign is trying to crawl the site with the user agent as simply set as rogerbot 1.2 but the robot.txt testing tool uses the full user agent string rogerbot/1.0 (http://moz.com/help/pro/what-is-rogerbot-, rogerbot-crawler+shiny@moz.com) albeit it's version 1.0. So seems as if cloudflare doesn't like the simple user agent. So is it correct the when MOZ is trying to crawl the site it uses the simple string of just rogerbot 1.2 now ?
Thanks
BenCloudflare activity log, showing differences in user agent strings
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-