After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Crawling Problem : No-data Of My Site
-
Hey, Folks!!
So It's Been More than a Month.And Moz is not crawling my website http://www.trickypedia.com/.I have seen Moz Last update I thought they will crawl my site but No results Disappointing. My Sites Domain Authority and Page Authority is still 1. But In other Seo Tools, they are Perfectly Crawling My Website. What Would Be the reason? Can anyone Please Explain.
-
If your website is experiencing a "no-data" issue during crawling by search engines, several factors may be at play. Check your robots.txt file, ensure proper HTTP status codes, examine your meta tags, confirm content accessibility, and investigate for technical errors. cloaking facebook ads consider the quality of your content, the efficiency of your crawl budget, mobile compatibility, and overall site security. Additionally, use webmaster tools for insights and, if needed, consult web development or SEO professionals for a comprehensive audit and solutions.
-
If your website is experiencing a "no-data" issue during crawling by search engines, several factors may be at play. Check your
robots.txtfile, ensure proper HTTP status codes, examine your meta tags, confirm content accessibility, and investigate for technical errors. Consider the quality of your content, the efficiency of your crawl budget, mobile compatibility, and overall site security. Additionally, use webmaster tools for insights and, if needed, consult web development or SEO professionals for a comprehensive audit and solutions. -
<h2>why my site not get verified from moz??</h2>
I created a website and I have ranked 1 in most of my keywords. and my site's traffic is normal and I have a fine domain authority but Moz still doesn't show any data on my website
could you guys check it and fix that problem for me??
my website (https://دندانپزشک.net/)
this is the address of my website
thank you<3
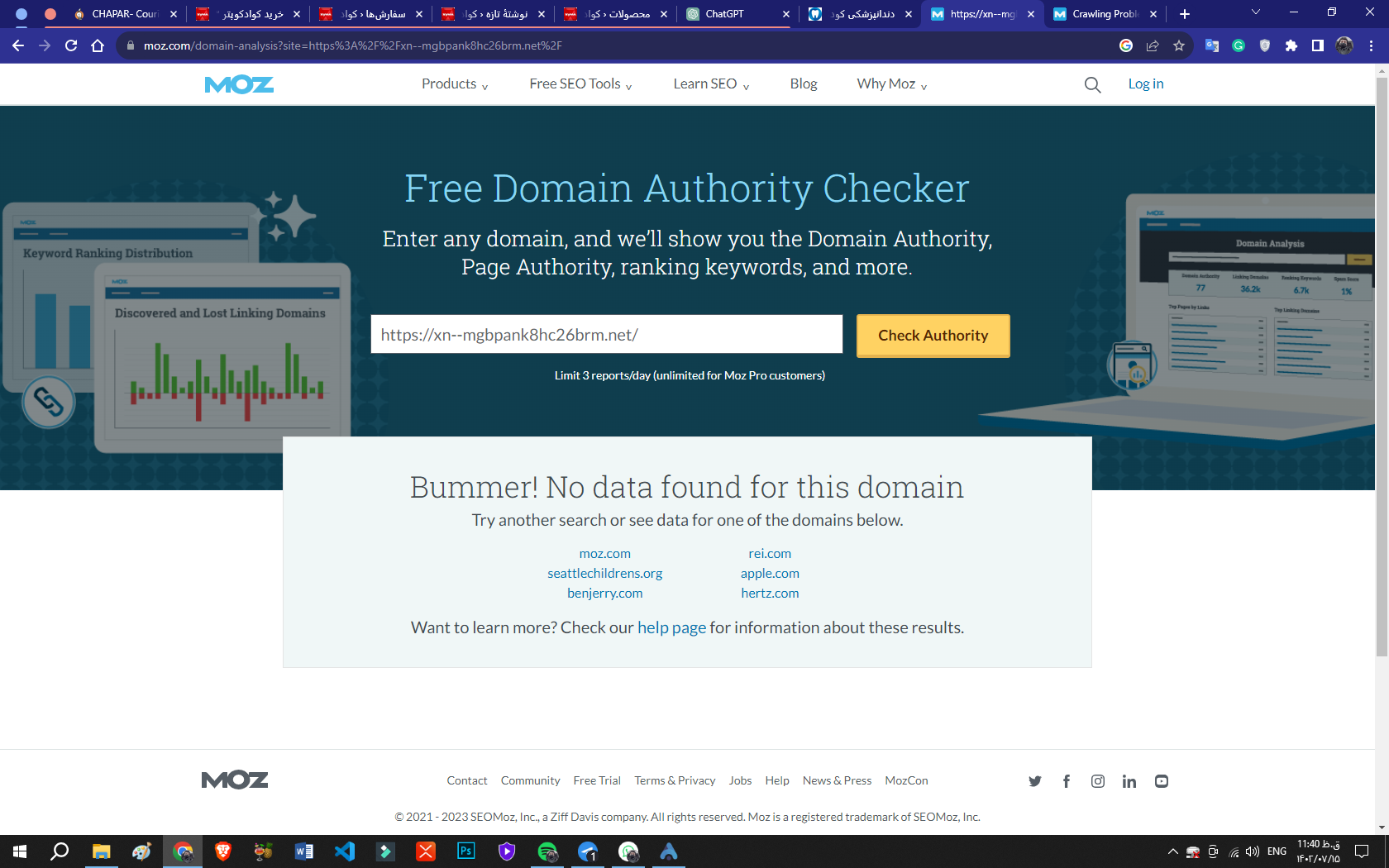
-
-
Hi there!
It sounds like you're wondering why we haven't got link data for you in OSE. There are a few possible reasons why your site might not be indexed.
The first thing to check is if your site uses a custom Top Level Domain (TLD), like .agency or .london. If so, then you won't see data for your site in our index, as we don't currently support custom TLDs. Unfortunately there isn't a good workaround for this—it's a technical limitation of the tool. I can see you site http://www.trickypedia.com/ doesn't use a custom TLD, so you're good.
If your site isn't linked to by one of the seed URLs used to build our index, then our bot won't be able to find it and add it to our map. Learn more about how we index the web.
In addition to this, Mozscape focuses on a breadth-first approach. Therefore we almost always have content from the homepage of websites, externally linked-to pages, and pages higher up in a site's information hierarchy. However, deep pages that are buried beneath many layers of navigation are sometimes missed, and it may be several index updates before we catch all of these.
If our crawlers or data sources are blocked from reaching those URLs, they may not be included in our index (though links that point to those pages will still be available).
Finally, the URLs seen by Mozscape must be linked-to by other documents on the web or our index will not include them.
If links to your pages have not been indexed and you have links from high Authority pages, you might want to check to see if we have indexed the pages linking to your site. Enter the URL that you know if linking you into Open Site Explorer and see if we've got those in our index. You'll also want to make sure that we aren't blocked from crawling the site. If our web crawlers are blocked from crawling certain pages (i.e., with "noindex" or a Robots.txt exclusion), they may not be included in the index.
I hope this helps, please do let me know if you would like more clarification or have any other queries.
Jo
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 043.2k
043.2k