Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
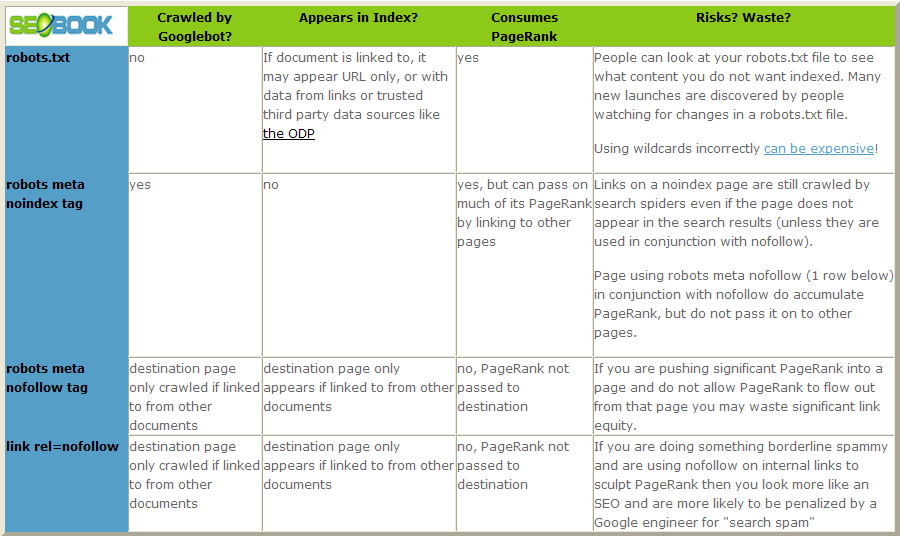
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

I need an XML sitemap expert for 5 minutes!
Hi all! I'm hoping that someone with a lot of experience with XML sitemaps can help me out here... When submitting my sitemap in Google Webmaster Tools, these are the results:
Technical SEO | | IcanAgency
2,414,714 Submitted
34,721 Indexed And there's also tonnes of warnings. Would anyone be able to take a quick look at these sitemaps to perhaps advise me on what's going wrong there? These do not load without the www, not sure if this is an issue? http://www.eumom.ie/sitemap.xml
http://www.eumom.ie/sitemap.xml.gz Thanks everyone in advance!! Gavin0 -

Need Urgent Help
I have found one mistake that my place page address is little different than address on all local directories like on place page address is: 10010 S Tryon St #122 Charlotte, NC 28273 and on directories : 10010 South Tryon St 122 Charlotte, NC 28273 so on place page it is just "S" instead of South and "#" is before 122 but on all directories # is missing So what do you suggest ? Should i change address and re verify place page ? Re verify will put down place page value ???
Technical SEO | | mnkpso0 -

Changing title tags, do we need 301 redirects
I found many duplicate title tags and I'm in the process of changing it Do I need 301 redirects in place when I switch it? I am only changing the title tag. Also, we are switching over to a new site very soon, I am worried that we might be using too many 301 redirect "hops" because we are doing a lot of optimization as well. (video from matt cutts describing 301 redirects and hops: http://www.youtube.com/watch?v=r1lVPrYoBkA. Does anyone have any experience in doing too many redirect hops that it affected your rankings? Any good ideas to avoid this?
Technical SEO | | EcomLkwd0 -

Blocked by robots
my client GWT has a number of notices for "blocked by meta-robots" - these are all either blog posts/categories/or tags his former seo told him this: "We've activated following settings: Use noindex for Categories Use noindex for Archives Use noindex for Tag Archives to reduce keyword stuffing & duplicate post tags
Technical SEO | | Ezpro9
Disabling all 3 noindex settings above may remove google blocks but also will send too many similar tags, post archives/category. " is this guy correct? what would be the problem with indexing these? am i correct in thinking they should be indexed? thanks0 -

No indexing url including query string with Robots txt
Dear all, how can I block url/pages with query strings like page.html?dir=asc&order=name with robots txt? Thanks!
Technical SEO | | HMK-NL0 -

Best META Fields to Include on New Site
I am in the process of transitioning sites to a Drupal CMS and am curious to know what META information to provide on each of the new site pages. Currently, this is the set-up I plan on using: My questions to the community are: whether or not I've added all pertinent information, and if there's anything I'm overlooking
Technical SEO | | NiallSmith0 -

Ajax #! URLs, Linking & Meta Refresh
Hi, We recently underwent a platform change and unfortunately our updated ecom site was coded using java script. The top navigation is uncrawlable, the pertinent product copy is undetectable and duplicated throughout the code, etc - it needs a lot of work to make it (even somewhat) seo-friendly. We're in the process of implementing ajax #! to our site and I've been tasked with creating a document of items that I will test to see if this solution will help our rankings, indexing, etc (on Google, I've read the issues w/ Bing). I have 2 questions: 1. Do I need to notify our content team who works on our linking strategy about the new urls? Would we use the #! url (for seo) or would we continue to use the clean url (without the #!) for inbound links? 2. When our site transferred over, we used meta refresh on all of the pages instead of 301s for some reason. Instead of going to a clean url, our meta refresh says this: . Would I update it to have the #! in the url? Should I try and clean up the meta refresh so it goes to an actual www. url and not this browsererrorview page? Or just push for the 301? I have read a ton of articles, including GWT docs, but I can't seem to find any solid information on these specific questions so any help I can get would be greatly appreciated. Thanks!
Technical SEO | | Improvements0 -
Which one is best? Parameters or Meta
I have issue regarding duplicate pages on website as follow. http://www.vistastores.com/review.html?pr_page_id=90344 http://www.vistastores.com/review.html?pr_page_id=90345 I checked my Google webmaster tools and found that Google have already set Parameter with pr_page_id. So, what is this? Will Google index all that pages? Can I use following Meta tag to block indexing? Which one is best?
Technical SEO | | CommercePundit0