How do i fix temporary redirects from Volusion?
-
I have around 20 temporary redirects that i can not really change. they look like this:
See attached
As you can see they are from LOGIN.ASP. This are system calls. I think the last thing I tried was blocking them in my robottxt file. but it doesn't seem to make a difference. Am I being effected by these redirects? How will Google look at them?
-
I actually got rid of The articles.asp links because they were not descriptive in the urls. I chose to create pages as opposed to these article snap-ins. They are still in my article menu i suppose, but there should be no links or menus items pointing directly to the article.asp(s). did you see that there were?
Yes i will have duplicate content. My blog www.bestbybrazil.com similar name without "fit" is set to auto post to several sites at once. If my website www.bestfitbybrazil.com is showing some of the same content, then again this must be pulling from the pages that were set up before. I think Volusion will still show stuff that you have in the background even if you dont have it on your website. So i will try deleting them i guess. kind of a pack rat with data. Always think i might be able to use it again.
by the way it looks like MOZ is only showing one other fix for me "Overly Dynamic Url"
http://www.bestfitbybrazil.com/NEW-ARRIVALS-s/1931.htm?searching=Y&sort=4&cat=1931&show=300&page=1
How do i get rid of this? Its not even a page. its a search. the page is as follows
http://www.bestfitbybrazil.com/NEW-ARRIVALS-s/1931.htm. Everything after is some kind of query. Do I need to enter the entire link as a dissallow in robot text or contact volusion. Not sure how much help they would be since MOZ is showing this.
Seems to work when i added the disallow in robot.text
-
Hi Robert,
Weird, you are right - the canonical tag appears on the majority of pages, but not on a select few, like https://www.bestfitbybrazil.com/Articles.asp?ID=282, which is indexed with its https URL. Is there something different you can see about this URL structure or where it sits in the site that might cause this? Could be worth pointing this one out to the Volusion team too. It appears that no URL with the Articles.asp?ID= structure has a canonical tag.
The other thing I see about this URL by just having a play around is that just changing the query string at the end to 283 as opposed to 282 is bring up the same page: http://www.bestfitbybrazil.com/Articles.asp?ID=283
Unrelated to the initial issue but a lot of the site's content is also duplicated on http://bestfitbybrazil.blogspot.co.uk/, a Google plus page and Tumblr e.g. https://www.google.co.uk/search?q=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&oq=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&aqs=chrome..69i57.1069j0j9&sourceid=chrome&es_sm=91&ie=UTF-8#filter=0&q=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&safe=off
-
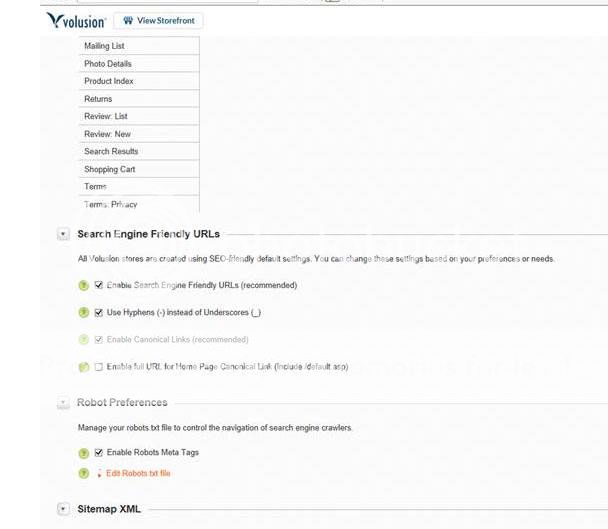
Thanks for you help Travis. Jane, I'm a little confused about this http vs https. I know they mean, but not whats happiening. I use Volusion. This a snap shot of my settings. Doesn't this take care of the Canonical concern or do i need to check something else on? Volusion support claims this is fine. Are you seeing something that might reflect its not. There setting is supposed to handle the default.asp vs. other dupe issues. My settings
-
Hi Robert,
Disallowing these in robots.txt is the correct thing to do here - this takes away any potential Google problem regarding the login pages. Google MIGHT still index them (but it's not - see here) because blocking via robots.txt says "don't crawl this" rather than "don't index this URL". Subtle difference, but you do sometimes see URLs that are blocked in robots.txt showing up in the index as JUST a URL (no title tag or meta description, since Google was not allowed to crawl the page). An example from your own site is the affiliate sign up page, which is blocked but indexed (see screenshot here).
Moz obeys robots.txt but it's showing these errors, likely because it has seen the links to those redirecting pages somewhere. But Google should not be a problem.
Regarding the HTTPS issue Travis pointed out, check out this search. This shows that you have pages with HTTPS URLs indexed - the top result for me is this page.
You need to implement the canonical tag to point to the preferred version of each URL (HTTP or HTTPS), or implement 301 redirects from one to the other, so URLs like this one are not indexed as they are now.
Cheers,
Jane
-
If the URLs were indexed, found and bookmarked, then visited at a later date - possibly - you're missing some sales. I doubt it, but that's something to keep in mind for the future.
The Moz forum is the place to ask about further questions. I may not have the time to get back to you, or not in the time frame you need.
Sending away soon-ish.
-
seems like MOZ is not finding the redirects since I disallowed them in robot txt using **"Disallow: /reviewhelpful.asp" **. The only way a live person would try to find these links in search is if they were just entered something like the "product name + rating" google finds it. I guess that means it doesn't need to be indexed to be found??
Anyhow my email is support@bestfitbybrazil.com
thx.
-
Google won't index what it can't crawl. You should be alright, from a duplicate content perspective. If people, real live ones, are trying to reach the site via this link, then you might have problems. If they can't reach it, you can't sell. You'll have to check your server log files to figure that out.
If actual 'hoomans' are trying to reach that URL (Not me bro, you don't want to see me in leggings. I'm in Grapevine TX. You can discount that traffic.)
Otherwise, I like to do a little more than the standard here's a blog link response. This is especially the case when I have an actual site to work with, not a vague question. A portion of the secure version of the site can be crawled, while obeying robots/nofollow which can lead to duplicate content concerns.
Send me a message with your email and I can send you the crawl. At least you'll be able sort out that issue. Your main concern may be a non-concern.
-
Hi Travis. and thx for your response. a little confused by what you mean. http and https "can" be crawled in a limited fashion??? did you mean "can't"? and if so, what then? how does that relate to my question. Generating duplicate content? please elaborate. You seem to raise more questions here
") I need answers... lol. thx.
I need answers... lol. thx.btw this is my robot txt file. I've been blocking the directories that keep coming up as 302 redirects. is this good or bad? I noticed alot of these are from customer reiviews.
Disallow: /cgi-bin/
Disallow: /mobile/category.aspx
Disallow: /myaccount.asp
Disallow: /shoppingcart.asp
Disallow: /orders.asp
Disallow: /AccountSettings.asp
Disallow: /net/FreeShipping.aspx
Disallow: /net/AuthenticateSession.aspx
Disallow: /affiliate_signup.asp
Disallow: /GiftCert_default.asp
Disallow: /redeem/
Disallow: /MyAccount_ApplyGift.asp
Disallow: /help_answer.asp
Disallow: /login.asp
Disallow: /login_sendpass.asp
Disallow: /SearchResults.asp?Cat=1956
Disallow: /category-s/1960.htm
Disallow: /MailingList_subscribe.asp
Disallow: /reviewhelpful.asp -
You have bigger problems. The HTTP and the HTTPS version of the site can be crawled in a limited fashion. Long story short, the site is generating it's own duplicate content.
My question is; "If they are paying to drive traffic to this URL, then why is it doing this?"
This isn't deadly, it's just not good.
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Hundreds of 301 Redirects. Remove Pages or Not?
Hi Mozers, I have a website that has literally got hundreds of 301 redirects. I had a close look at these URLs and only some of them have backlinks to it and remaining all of them are not indexing in Google and has got not backlinks at all. Based on what I have noticed experts mentioning, loads of 301 redirects can potentially slow down the site speed. In a case like the website I have, should I completely take off the pages from website to reduce the number of 301 redirects or should I leave 301 redirects? There is no traffic or backlinks coming from these URLs. Malika
Intermediate & Advanced SEO | | Malika10 -

Delay release of content or fix after release
I am in the midst of moving my site to a new platform. As part of that I am reviewing each and every article for SEO - titles, URLs, content, formatting/structure, etc, etc. I have about 200 articles to move across and my eventual plan is to look at each article and update for these factors. I have all the old content moved across to the new server as-is (the old server is still the one to which my domain's DNS records point). At a high level I have two choice: Point DNS to the new server, which will expose the same content (which isn't particularly SEO-friendly) and then work through each article, fixing the various elements to make them more user friendly. Go through each article, fixing content, structure, etc and THEN update DNS to point to the new server. Obviously the second option adds time before I can switch across. I'd estimate it will take me a few weeks to get through the articles. Option 1 allows me to switch pretty soon and then start going through the articles and updating them. An important point here is the new articles already have new (SEO-friendly) URLs and titles on the new server. I have 301 redirections in place pointing from the old to new URLs. So, it's "only" the content of each article that will be changing on the new server, rather than the URLs, etc. So, I'd be interested in any suggestions on the best approach - move across to the new server now and then fix content or wait till all the content is done and then switch to the new server. Thanks. Mark
Intermediate & Advanced SEO | | MarkWill0 -

GEO IP Redirects affecting Organic Rankings
Not sure if anyone has ever had this problem. We have a client who is a UK based retailer with a large retail presence in Canada and a U.S site as well. For the past year while keeping track of their rankings, they steadily ranked #1 for their brand term on Google.CA. At the end of June we implemented a GEO IP redirect for U.S visitors to be redirected to the U.S site if they clicked on the .CA listing. Over the next two weeks the ranking for the single branded keyword went from #1 to completely off the top 50. Could this have possibly happened due to the GEO IP redirect? The .CO.UK site has always been top 3 in the organic listing and is still #1 but in Google.ca the Canadian site has dropped off completely after consistently ranking #1.
Intermediate & Advanced SEO | | demacmedia0 -

How to 301 redirect old wordpress category?
Hi All, In order to avoid duplication errors we've decided to redirect old categories (merge some categories).
Intermediate & Advanced SEO | | BeytzNet
In the past we have been very generous with the number of categories we assigned each post. One category needs to be redirected back to blog home (removed completely) while a couple others should be merged. Afterwords we will re-categorize some of the old posts. What is the proper way to do so?
We are not technical, Is there a plugin that can assist? Thanks0 -

Redirection Effects on Sub Domain
Hi, I would try to summarize my query through an example. Lets say site A (www.siteA.com) have two sub domain (subdomain1.siteA.com & subdomain2.siteA.com) and another site B ( www.siteB.com ) have no sub domain. Due to some obvious reason we need re direct the site site A (www.siteA.com) to site B ( www.siteB.com ) and one of the sub domain (subdomain1.siteA.com) to site B (subdomain1.siteB.com). Now the question is that in case of ( subdomain2.siteA.com ) can we keep the sub domain to site A even though site A has been re directed to site B ? Reasons for keeping this can be traffic, earnings etc. Is it possible to keep it like that or provision for further optimization? Plz help.
Intermediate & Advanced SEO | | ITRIX0 -

Need advice on 301 domain redirection
Hello friends, We have two sites namely spiderman-example.com & avengers-example.com which sells the same product listed out under similar categories, since we are about to stop or put down the site “avengers-example.com” because we just want to concentrate in bringing up a single brand called spiderman-example.com. “Spiderman-example” has comparatively more visitors and conversion rates than ''avengers-example'' ie. 90 % more traffic and conversion. Avengers-example has a small fraction of loyal customers who still search for the brand-name & there are a hand-full of potential keywords those ranking on its own. So is it advisable to redirect Avengers-example to spiderman-example using 301-redirect? Will this help to gain any link-juice from Avengers-example? If so how can we effectively redirect between two domain’s with minimal loss in page authority & linkjuice to enhance ''spiderman-example''? Off beat:These names "Avengers" and "Spiderman" were just used as an example but the actual site names has no relation to the ones mentioned above.
Intermediate & Advanced SEO | | semvibe0 -

Multi domain redirect to single domain
Hello, all SEOers. Today, I would like to get some ideas about handling multiple domains. I have a client who bought numerous domains under purpose of prevent abuse of their brand name and at the same time for future uses. This client bought more than 100 domains. Some domains are paused, parked, lived and redirected to other site. I don't worry too much of parked domains and paused domains. However, what I am worrying is that there are about 40 different domains are now redirected to single domain and meta refresh was used for redirections. As far as I know, this can raise red flag for Google. I asked clients to clean up unnecessary domains, yet they want to keep them all. So now I have to figure out how to handle all domains which are redirect to single domain. So far, I came up with following ideas. 1. Build gateway page which shows lists of my client sites and redirect all domains to gateway page. 2. Implement robots.txt file to all different domains 3. Delete the redirects and leave it as parked domains. Could anyone can share other ideas in order to handling current status? Please people, share your ideas for me.
Intermediate & Advanced SEO | | Artience0 -

Setting up of 301 redirects
Good morning all, As part of the analysis of our website, we have realised that we are diluting our keyword strength in a particular area by having multiple zones all targeting the same keyword. We have decided to combine these zones into one, and set up 301 redirects so that the remaining zone gets the benefit of the other zones' link juice. When setting up a 301 redirect from zone "X" to zone "Y" say, do I need to keep all of the content in zone X, or should I remove all content before the redirect is set up? Does zone Y still get the benefit of zone X's link juice if the content is removed? Many thanks Guy
Intermediate & Advanced SEO | | Horizon0