Search optimal Tab structure?
-
Good day,
We are in the process of starting a website redesign/development.
We will likely be employing a tabbing structure on our home page and would like to be able to capitalize on the keyword content found across the various tabs.
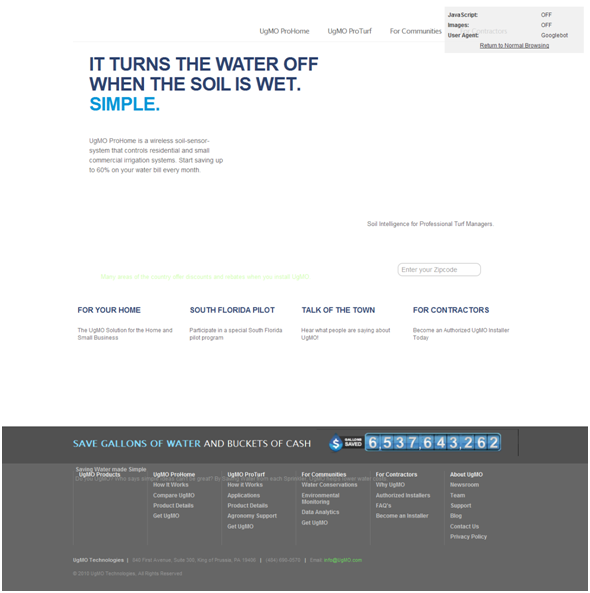
The tab structure will be similar to how this site achieves tabs: http://ugmo.com/
I've uploaded a screen grab of this page as the Googlebot user agent. The text "Soil Intelligence for professional Turf Managers" clicks through to this page: http://ugmo.com/?quicktabs_1=1#quicktabs-1
So I'm thinking there could be some keyword dilution there. That said Google is very much aware of the text on the quicktabs-1 page being related to the home page content: http://www.google.com/search?q=Up+your+game+with+precise+soil+moisture%2C+salinity+and+temperature+measurements.+And+in+the+process%2C+save+water%2C+resources%2C+money.+inurl%3Augmo.com&sourceid=ie7&rls=com.microsoft:en-us:IE-SearchBox&ie=&oe=
Is this the best search optimal way to add keyword density on a home page with a tab structure? Or is there a better means of achieving this?
{61bfcca1-5f32-435e-a311-7ef4f9b592dd}_tabs_as_Googlebot.png
-
I'm pretty sure that's what's happening.
So mendely.com is a book mark approach to tabs, as opposed to the javascript ? variable and then bookmark approach here: http://ugmo.com/?quicktabs_1=1#quicktabs-1
I can see how the content is all on the page.
Is there any dilution with the bookmark approach? To what extent is http://www.mendeley.com/#mobile different than http://www.mendeley.com/ ?
-
is that then not just loading eveything onto 1 url and using javascript to hide the tab 2 & 3 content till someone hits it?
or something like this http://www.mendeley.com/ click on the overview, features, discover research and ipad tabs - all that content is on the page
-
Not exactly, I'm saying each tab will have a set of keywords on them and we'd like those keywords to be accessible to spiders in an optimal manner. So let's say I have
Tab 1 - keyword copy 1
Tab 2 - keyword copy 2
Tab 3 - keyword copy 3
I want to make sure keyword copy 2 & 3 are providing keyword goodness for the home page.
Does that make sense?
-
Not sure if I understand your point correctly. Are you saying you will be dynamically feeding keywords on the pages with tabs?
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Dynamic Canonical Tag for Search Results Filtering Page
Hi everyone, I run a website in the travel industry where most users land on a location page (e.g. domain.com/product/location, before performing a search by selecting dates and times. This then takes them to a pre filtered dynamic search results page with options for their selected location on a separate URL (e.g. /book/results). The /book/results page can only be accessed on our website by performing a search, and URL's with search parameters from this page have never been indexed in the past. We work with some large partners who use our booking engine who have recently started linking to these pre filtered search results pages. This is not being done on a large scale and at present we only have a couple of hundred of these search results pages indexed. I could easily add a noindex or self-referencing canonical tag to the /book/results page to remove them, however it’s been suggested that adding a dynamic canonical tag to our pre filtered results pages pointing to the location page (based on the location information in the query string) could be beneficial for the SEO of our location pages. This makes sense as the partner websites that link to our /book/results page are very high authority and any way that this could be passed to our location pages (which are our most important in terms of rankings) sounds good, however I have a couple of concerns. • Is using a dynamic canonical tag in this way considered spammy / manipulative? • Whilst all the content that appears on the pre filtered /book/results page is present on the static location page where the search initiates and which the canonical tag would point to, it is presented differently and there is a lot more content on the static location page that isn’t present on the /book/results page. Is this likely to see the canonical tag being ignored / link equity not being passed as hoped, and are there greater risks to this that I should be worried about? I can’t find many examples of other sites where this has been implemented but the closest would probably be booking.com. https://www.booking.com/searchresults.it.html?label=gen173nr-1FCAEoggI46AdIM1gEaFCIAQGYARS4ARfIAQzYAQHoAQH4AQuIAgGoAgO4ArajrpcGwAIB0gIkYmUxYjNlZWMtYWQzMi00NWJmLTk5NTItNzY1MzljZTVhOTk02AIG4AIB&sid=d4030ebf4f04bb7ddcb2b04d1bade521&dest_id=-2601889&dest_type=city& Canonical points to https://www.booking.com/city/gb/london.it.html In our scenario however there is a greater difference between the content on both pages (and booking.com have a load of search results pages indexed which is not what we’re looking for) Would be great to get any feedback on this before I rule it out. Thanks!
Technical SEO | | GAnalytics1 -

Spam URL'S in search results
We built a new website for a client. When I do 'site:clientswebsite.com' in Google it shows some of the real, recently submitted pages. But it also shows many pages of spam url results, like this 'clientswebsite.com/gockumamaso/22753.htm' - all of which then go to the sites 404 page. They have page titles and meta descriptions in Chinese or Japanese too. Some of the urls are of real pages, and link to the correct page, despite having the same Chinese page titles and descriptions in the SERPS. When I went to remove all the spammy urls in Search Console (it only allowed me to temporarily hide them), a whole load of new ones popped up in the SERPS after a day or two. The site files itself are all fine, with no errors in the server logs. All the usual stuff...robots.txt, sitemap etc seems ok and the proper pages have all been requested for indexing and are slowly appearing. The spammy ones continue though. What is going on and how can I fix it?
Technical SEO | | Digital-Murph0 -

Received A Notice Regarding Spammy Structured Data. But we don't have any structured data or do we?
Got a message that we have spammy structured data on our site via webmaster tools and have no idea what they are referring to. We do not use any structured data using schema.org mark up. Could they be referring to something else? The message was: To: Webmaster of <a>http://www.lulus.com/</a>, Google has detected structured markup on some of your pages that violates our structured data quality guidelines. In order to ensure quality search results for users, we display rich search results only for content that uses markup that conforms to our quality guidelines. This manual action has been applied to lulus.com/ . We suggest that you fix your markup and file a reconsideration request. Once we determine that the markup on the pages is compliant with our guidelines, we will remove this manual action. What could we be showing them that would be interpreted as structured data, and or spammy structured data?
Technical SEO | | KentH0 -

Many errors in Search Console (strange parameters)
Hello, I have many strange parameters in my search console that make many 404 pages, for example: mywebsite.com/article-name/&ct=ga&cd=CAIyGjk4YjY4ZDExNTYxOTgzZTk6Y29tOmVuOlVT&usg=AFQjCNFvpYpYpYf9DoyRBBu8jbiQB8JcIQ mywebsite.com/article-name/&sa=U&ved=0ahUKEwj1zMLR0JbLAhUGM5oKHejjBJAQqQIILSgAMAk&usg=AFQjCNEBNFx3dG5B0-16X6eXTS7k-Srm6Q Can someone tell me how to solve it?
Technical SEO | | JohnPalmer0 -

What I doing wrong when trying to search for links from external websites to my website
This is just the little frustrating question nothing important but I’m sure somebody will know the answer. In the white board Friday this week Rand suggested at one point that when you’re searching for results links to your website if you put a - followed by site followed by your url like –site:yourwebsite.com you get the results of pages with links on other websites but excluding your own webpages but it just doesn’t work I get no results just an error message, any idea why? If I remove the - I get tons of results but there on my own webpages……….
Technical SEO | | whitbycottages0 -

Optimizing one site for multiple countries
I am working on a project, where we have one website, with a country specific domain, which is currently ranking well in local search. The client now wants to expand his business into two new countries (all english speaking) and would like to rank for the same keywords in these two new countries. The customer do not want to create new websites for the new countries. Because its a local domain and the website is setup for local search in GWT with locally hosted server, i expect challenges in optimizing for new countries without impacting the current local ranking. Question 1: What would be the recommended approach for maintaining their existing ranking on local search, while optimizing for the new countries.
Technical SEO | | petersen0 -

Optimize flash site
Hello, How can we optimize a site like this - http://www.ziba.com.au/ . The whole site is in flash. What are the alternatives ?
Technical SEO | | seoug_20050 -

Should I set up a disallow in the robots.txt for catalog search results?
When the crawl diagnostics came back for my site its showing around 3,000 pages of duplicate content. Almost all of them are of the catalog search results page. I also did a site search on Google and they have most of the results pages in their index too. I think I should just disallow the bots in the /catalogsearch/ sub folder, but I'm not sure if this will have any negative effect?
Technical SEO | | JordanJudson0