Robots.txt wildcards - the devs had a disagreement - which is correct?
-
Hi – the lead website developer was assuming that this wildcard: Disallow: /shirts/?* would block URLs including a ? within this directory, and all the subdirectories of this directory that included a “?”
The second developer suggested that this wildcard would only block URLs featuring a ? that come immediately after /shirts/ - for example: /shirts?minprice=10&maxprice=20 BUT argued that this robots.txt directive would not block URLS featuring a ? in sub directories - e.g. /shirts/blue?mprice=100&maxp=20
So which of the developers is correct?
Beyond that, I assumed that the ? should feature a * on each side of it – for example - /? - to work as intended above? Am I correct in assuming that?
-
Thanks Logan - much appreciated, as ever - that really helps
") - if I was to add another * to **Allow: /?resultspage= > so **Allow: /?*resultspage= - what would happen then? ****
- if I was to add another * to **Allow: /?resultspage= > so **Allow: /?*resultspage= - what would happen then? **** -
Ok, gotcha. Add the following directives:
Disallow: /shirts/?
This prevents crawling of the following:
- /shirts**/golden/**?minprice=10&maxprice=20
- /shirts/?minprice=10&maxprice=20
Allow: /*?resultspage=
Allows crawling of the following:
- /shirts/navy/?resultspage=02
- /shirts/?resultspage=01
-
Thanks Logan - much appreciated - the aim would be to prevent bots crawling any parameter'd URL but only in the products section, and not all of them - see below.
I noticed the shirt URLs can be produce many pages of results - e.g. if you look for a type of shirt you can get up to 20 pages of results - the resulting URLs also feature a ?
So you end up with - for example - /shirts/?resultspage=01 and then /shirts/?resultspage=02 or shirts/navy/?resultspage=01 and /shirts/navy/?resultspage=02 - and so on - and it would be good to index them somehow. So I wonder how I can override disallow parameters robots.txt instruction only for specific paths and even individual pages?
-
Disallow: /shirts/?* will only block URLs that end with /shirts/ before beginning a parameter string. If you want to block /shirts**/golden/**?minprice=10&maxprice=20 you'll have to add the asterisk before and after the ?
What the end goal here? Preventing bots from crawling any parameter'd URL?
-
I suppose the nub of the disagreement is this: would Disallow: /shirts/?* block /shirts/?minprice=10&maxprice=20 and also block URLS further down the URL directory structure - e.g. /shirts/mens/navyblue/?minprice=10&maxprice=20 ?
-
Thanks Logan - the lead website developer was assuming that this wildcard: Disallow: /shirts/?* would block URLs including a ? within this directory, and all the subdirectories of this directory that included a “?”
If I amended the URL to
/shirts/?minprice=10&maxprice=20 would robots.txt work as intended right there?and would that robots.txt work as intended further down the directory structure of the URLs? E.g.
/shirts**/golden/**?minprice=10&maxprice=20 -
Hi Luke,
The second developer is correct....well, more correct than the first. Your example of /shirts?minprice=10&maxprice=20 would not be blocked by this direction, since there's no slack after shirts.
For future reference, you can test how directives function in Google Search Console. Under the 'Crawl' menu, there's a robots.txt tester in which you can manually edit the robots.txt directives (they don't apply to the live file) and enter test URLs to see which directive, if any, would prevent crawling.
You are correct in your assumption that a * on either side of the ? would prevent crawling of both /shirts/blue?mprice=100&maxp=20 and /shirts/?minprice=10&maxprice=20
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Meta robots
Hi, I am checking a website for SEO and I've noticed that a lot of pages from the blog have the following meta robots: meta name="robots" content="follow" Normally these pages should be indexed, since search engines will index and follow by default. In this case however, a lot of pages from this blog are not indexed. Is this because the meta robots is specified, but only contains follow? So will search engines only index and follow by default if there is no meta robots specified at all? And secondly, if I would change the meta robots, should I just add index or remove the meta robots completely from the code? Thanks for checking!
Intermediate & Advanced SEO | | Mat_C0 -

Our parent company has included their sitemap links in our robots.txt file - will that have an impact on the way our site is crawled?
Our parent company has included their sitemap links in our robots.txt file. All of their sitemap links are on a different domain and I'm wondering if this will have any impact on our searchability or potential rankings.
Intermediate & Advanced SEO | | tsmith1310 -

If Robots.txt have blocked an Image (Image URL) but the other page which can be indexed has this image, how is the image treated?
Hi MOZers, This probably is a dumb question but I have a case where the robots.tags has an image url blocked but this image is used on a page (lets call it Page A) which can be indexed. If the image on Page A has an Alt tags, then how is this information digested by crawlers? A) would Google totally ignore the image and the ALT tags information? OR B) Google would consider the ALT tags information? I am asking this because all the images on the website are blocked by robots.txt at the moment but I would really like website crawlers to crawl the alt tags information. Chances are that I will ask the webmaster to allow indexing of images too but I would like to understand what's happening currently. Looking forward to all your responses 🙂 Malika
Intermediate & Advanced SEO | | Malika11 -

Is this correct?
I noticed Moz using the following for its homepage Is this best practice though? The reason I ask is that, I use and I've been reading this page by Google http://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html 5 common mistakes with rel=canonical Mistake 2: Absolute URLs mistakenly written as relative URLs
Intermediate & Advanced SEO | | Bio-RadAbs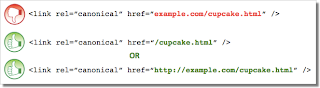 The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
0
The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
0 -

Should I disallow all URL query strings/parameters in Robots.txt?
Webmaster Tools correctly identifies the query strings/parameters used in my URLs, but still reports duplicate title tags and meta descriptions for the original URL and the versions with parameters. For example, Webmaster Tools would report duplicates for the following URLs, despite it correctly identifying the "cat_id" and "kw" parameters: /Mulligan-Practitioner-CD-ROM
Intermediate & Advanced SEO | | jmorehouse
/Mulligan-Practitioner-CD-ROM?cat_id=87
/Mulligan-Practitioner-CD-ROM?kw=CROM Additionally, theses pages have self-referential canonical tags, so I would think I'd be covered, but I recently read that another Mozzer saw a great improvement after disallowing all query/parameter URLs, despite Webmaster Tools not reporting any errors. As I see it, I have two options: Manually tell Google that these parameters have no effect on page content via the URL Parameters section in Webmaster Tools (in case Google is unable to automatically detect this, and I am being penalized as a result). Add "Disallow: *?" to hide all query/parameter URLs from Google. My concern here is that most backlinks include the parameters, and in some cases these parameter URLs outrank the original. Any thoughts?0 -

Avoiding Duplicate Content with Used Car Listings Database: Robots.txt vs Noindex vs Hash URLs (Help!)
Hi Guys, We have developed a plugin that allows us to display used vehicle listings from a centralized, third-party database. The functionality works similar to autotrader.com or cargurus.com, and there are two primary components: 1. Vehicle Listings Pages: this is the page where the user can use various filters to narrow the vehicle listings to find the vehicle they want.
Intermediate & Advanced SEO | | browndoginteractive
2. Vehicle Details Pages: this is the page where the user actually views the details about said vehicle. It is served up via Ajax, in a dialog box on the Vehicle Listings Pages. Example functionality: http://screencast.com/t/kArKm4tBo The Vehicle Listings pages (#1), we do want indexed and to rank. These pages have additional content besides the vehicle listings themselves, and those results are randomized or sliced/diced in different and unique ways. They're also updated twice per day. We do not want to index #2, the Vehicle Details pages, as these pages appear and disappear all of the time, based on dealer inventory, and don't have much value in the SERPs. Additionally, other sites such as autotrader.com, Yahoo Autos, and others draw from this same database, so we're worried about duplicate content. For instance, entering a snippet of dealer-provided content for one specific listing that Google indexed yielded 8,200+ results: Example Google query. We did not originally think that Google would even be able to index these pages, as they are served up via Ajax. However, it seems we were wrong, as Google has already begun indexing them. Not only is duplicate content an issue, but these pages are not meant for visitors to navigate to directly! If a user were to navigate to the url directly, from the SERPs, they would see a page that isn't styled right. Now we have to determine the right solution to keep these pages out of the index: robots.txt, noindex meta tags, or hash (#) internal links. Robots.txt Advantages: Super easy to implement Conserves crawl budget for large sites Ensures crawler doesn't get stuck. After all, if our website only has 500 pages that we really want indexed and ranked, and vehicle details pages constitute another 1,000,000,000 pages, it doesn't seem to make sense to make Googlebot crawl all of those pages. Robots.txt Disadvantages: Doesn't prevent pages from being indexed, as we've seen, probably because there are internal links to these pages. We could nofollow these internal links, thereby minimizing indexation, but this would lead to each 10-25 noindex internal links on each Vehicle Listings page (will Google think we're pagerank sculpting?) Noindex Advantages: Does prevent vehicle details pages from being indexed Allows ALL pages to be crawled (advantage?) Noindex Disadvantages: Difficult to implement (vehicle details pages are served using ajax, so they have no tag. Solution would have to involve X-Robots-Tag HTTP header and Apache, sending a noindex tag based on querystring variables, similar to this stackoverflow solution. This means the plugin functionality is no longer self-contained, and some hosts may not allow these types of Apache rewrites (as I understand it) Forces (or rather allows) Googlebot to crawl hundreds of thousands of noindex pages. I say "force" because of the crawl budget required. Crawler could get stuck/lost in so many pages, and my not like crawling a site with 1,000,000,000 pages, 99.9% of which are noindexed. Cannot be used in conjunction with robots.txt. After all, crawler never reads noindex meta tag if blocked by robots.txt Hash (#) URL Advantages: By using for links on Vehicle Listing pages to Vehicle Details pages (such as "Contact Seller" buttons), coupled with Javascript, crawler won't be able to follow/crawl these links. Best of both worlds: crawl budget isn't overtaxed by thousands of noindex pages, and internal links used to index robots.txt-disallowed pages are gone. Accomplishes same thing as "nofollowing" these links, but without looking like pagerank sculpting (?) Does not require complex Apache stuff Hash (#) URL Disdvantages: Is Google suspicious of sites with (some) internal links structured like this, since they can't crawl/follow them? Initially, we implemented robots.txt--the "sledgehammer solution." We figured that we'd have a happier crawler this way, as it wouldn't have to crawl zillions of partially duplicate vehicle details pages, and we wanted it to be like these pages didn't even exist. However, Google seems to be indexing many of these pages anyway, probably based on internal links pointing to them. We could nofollow the links pointing to these pages, but we don't want it to look like we're pagerank sculpting or something like that. If we implement noindex on these pages (and doing so is a difficult task itself), then we will be certain these pages aren't indexed. However, to do so we will have to remove the robots.txt disallowal, in order to let the crawler read the noindex tag on these pages. Intuitively, it doesn't make sense to me to make googlebot crawl zillions of vehicle details pages, all of which are noindexed, and it could easily get stuck/lost/etc. It seems like a waste of resources, and in some shadowy way bad for SEO. My developers are pushing for the third solution: using the hash URLs. This works on all hosts and keeps all functionality in the plugin self-contained (unlike noindex), and conserves crawl budget while keeping vehicle details page out of the index (unlike robots.txt). But I don't want Google to slap us 6-12 months from now because it doesn't like links like these (). Any thoughts or advice you guys have would be hugely appreciated, as I've been going in circles, circles, circles on this for a couple of days now. Also, I can provide a test site URL if you'd like to see the functionality in action.0 -

Should comments and feeds be disallowed in robots.txt?
Hi My robots file is currently set up as listed below. From an SEO point of view is it good to disallow feeds, rss and comments? I feel allowing comments would be a good thing because it's new content that may rank in the search engines as the comments left on my blog often refer to questions or companies folks are searching for more information on. And the comments are added regularly. What's your take? I'm also concerned about the /page being blocked. Not sure how that benefits my blog from an SEO point of view as well. Look forward to your feedback. Thanks. Eddy User-agent: Googlebot Crawl-delay: 10 Allow: /* User-agent: * Crawl-delay: 10 Disallow: /wp- Disallow: /feed/ Disallow: /trackback/ Disallow: /rss/ Disallow: /comments/feed/ Disallow: /page/ Disallow: /date/ Disallow: /comments/ # Allow Everything Allow: /*
Intermediate & Advanced SEO | | workathomecareers0 -

Why specify robots instead of googlebot for a Panda affected site?
Daniweb is the poster child for sites that have recovered from Panda. I know one strategy she mentioned was de-indexing all of her tagged content, fo rexample: http://www.daniweb.com/tags/database Why do you think more Panda affected sites specifying 'googlebot' rather than 'robots' to capture traffic from Bing & Yahoo?
Intermediate & Advanced SEO | | nicole.healthline0