After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
How to index e-commerce marketplace product pages
-
Hello!
We are an online marketplace that submitted our sitemap through Google Search Console 2 weeks ago. Although the sitemap has been submitted successfully, out of ~10000 links (we have ~10000 product pages), we only have 25 that have been indexed.
I've attached images of the reasons given for not indexing the platform.
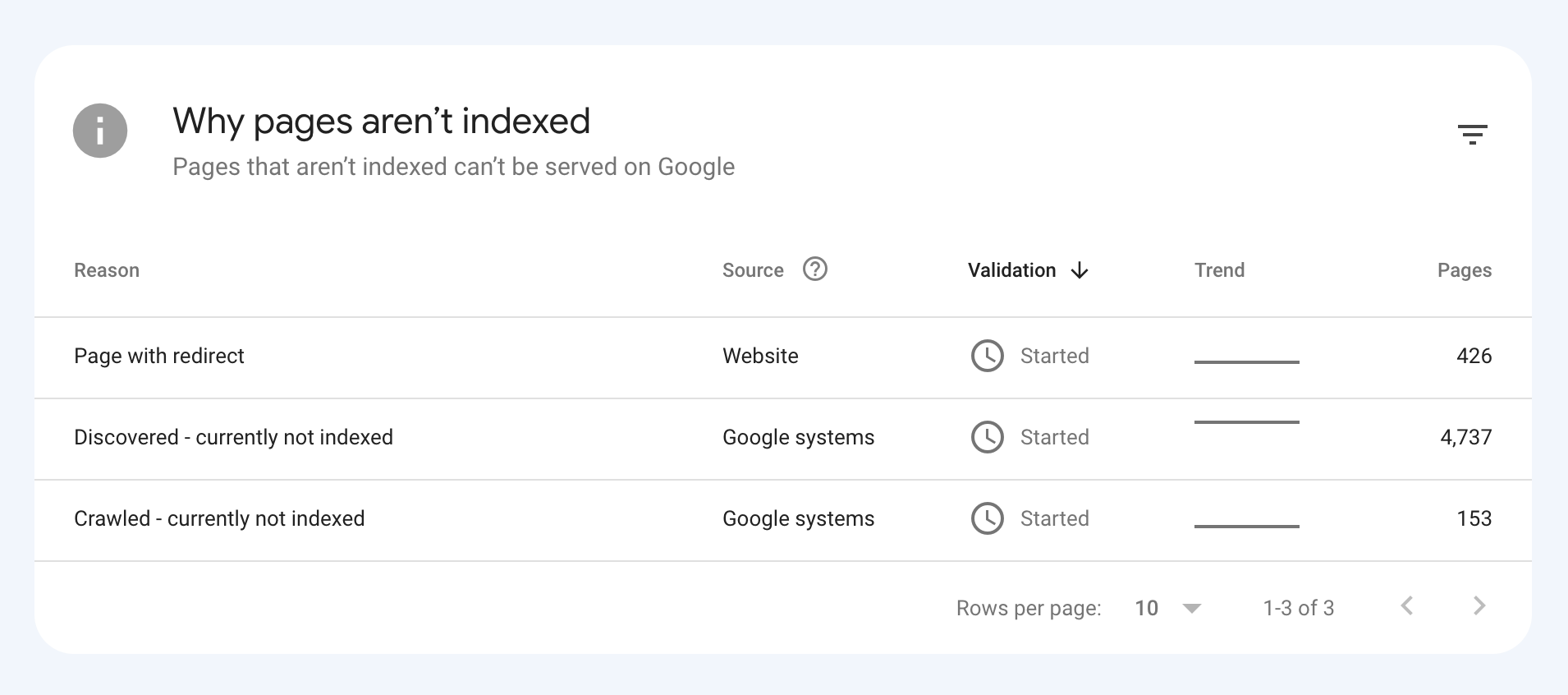
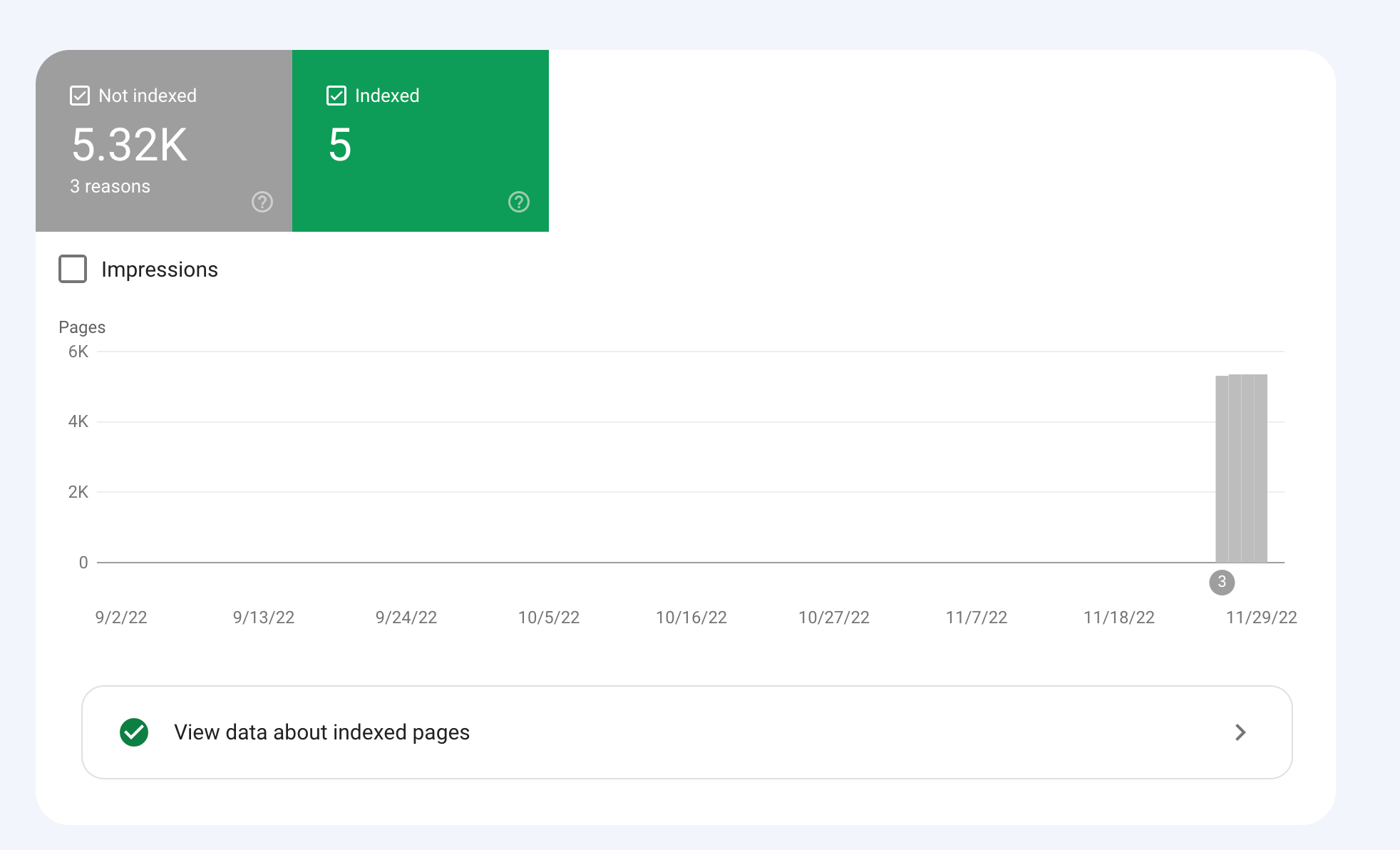
How would we go about fixing this?
-
To get your e-commerce marketplace product pages indexed, make sure your pages include unique and descriptive titles, meta descriptions, relevant keywords, and high-quality images. Additionally, optimize your URLs, leverage schema markup, and prioritize user experience for increased search engine visibility.
-
@fbcosta i hve this problem but its so less in my site
پوشاک پاپیون -
I'd appreciate if someone who faced the same indexing issue comes forward and share the case study with fellow members. Pin points steps a sufferer should do to overcome indexing dilemma. What actionable steps to do to enable quick product indexing? How we can get Google's attention so it can start indexing pages at a quick pace? Actionable advice please.
-
There could be several reasons why only 25 out of approximately 10,000 links have been indexed by Google, despite successfully submitting your sitemap through Google Search Console:
Timing: It is not uncommon for indexing to take some time, especially for larger sites with many pages. Although your sitemap has been submitted, it may take several days or even weeks for Google to crawl and index all of your pages. It's worth noting that not all pages on a site may be considered important or relevant enough to be indexed by Google.
Quality of Content: Google may not index pages that it considers low-quality, thin or duplicate content. If a significant number of your product pages have similar or duplicate content, they may not be indexed. To avoid this issue, make sure your product pages have unique, high-quality content that provides value to users.
Technical issues: Your site may have technical issues that are preventing Google from crawling and indexing your pages. These issues could include problems with your site's architecture, duplicate content, or other issues that may impact crawling and indexing.
Inaccurate Sitemap: There is also a possibility that there are errors in the sitemap you submitted to Google. Check the sitemap to ensure that all the URLs are valid, the sitemap is up to date and correctly formatted.
To troubleshoot this issue, you can check your site's coverage report on Google Search Console, which will show you which pages have been indexed and which ones haven't. You can also check your site's crawl report to see if there are any technical issues that may be preventing Google from crawling your pages. Finally, you can also run a site audit to identify and fix any technical issues that may be impacting indexing.
-
@fbcosta As per my experience, if your site is new it will take some time to index all of the URLs, and the second thing is, if you have Hundreds of URLs, it doesn't mean Google will index all of them.
You can try these steps which will help in fast indexing:
- Sharing on Social Media
- Interlinking from already indexed Pages
- Sitemap
- Share the link on the verified Google My Business Profile (Best way to index fast). You can add by-products or create a post and link it to the website.
- Guest post
I am writing here for the first time, I hope it will help
")
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 0151.9k
0151.9k
-
 071.6k
071.6k
-
 031.8k
031.8k
-
 021.7k
021.7k
-
 1104.5k
1104.5k
-
 012.9k
012.9k
-
 0318.7k
0318.7k
-
 195.0k
195.0k