Is our robots.txt file correct?
-
Could you please review our robots.txt file and let me know if this is correct.
Thank you!
-
What's the end goal here?
Are you actively trying to block all bots?If so, I would still suggest "Disallow:/".
The other syn-text may also work, but if Google suggests using a backslash, you should probably use it. -
Hi, it seems correct to me however try to use the robots.txt checker tool in GWTools. You may try to include a couple of your urls and see if google can crawl them.
I find only redundant the follwing rule:
User-agent: Mediapartners-Google.
If you have already set up a disallow: rule for all bot excluding rogerbot which can't access the community folder why create a new rule stating the same for mediapartners?
Again, why are you saying to all bots they can access the entire site, being that the default rule? Avoid those lines, include just the rogerbot and sitemaps rule and you're done.
-
Thank you for the reply. We want to allow all crawling, except for rogerbot in the community folder.
I have updated the robots.txt to the following, does this look right?:
User-agent: * Disallow: User-agent: rogerbot Disallow: /community/ User-agent: Mediapartners-Google Disallow: Sitemap: http://www.faithology.com/sitemap.xml view the robots here: http://www.faithology.com/robots.txt -
There are some errors, but since I'm not sure what you are trying to accomplish, I recommend checking it with a tool first. Here is a great tool to check your robots.txt file and give you information on errors - http://tool.motoricerca.info/robots-checker.phtml
If you still need assistance after running it through the tool, please reply and we can help you further.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Is this correct?
I noticed Moz using the following for its homepage Is this best practice though? The reason I ask is that, I use and I've been reading this page by Google http://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html 5 common mistakes with rel=canonical Mistake 2: Absolute URLs mistakenly written as relative URLs
Intermediate & Advanced SEO | | Bio-RadAbs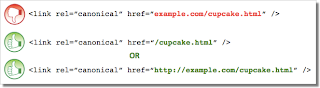 The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
0
The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
0 -

Should comments and feeds be disallowed in robots.txt?
Hi My robots file is currently set up as listed below. From an SEO point of view is it good to disallow feeds, rss and comments? I feel allowing comments would be a good thing because it's new content that may rank in the search engines as the comments left on my blog often refer to questions or companies folks are searching for more information on. And the comments are added regularly. What's your take? I'm also concerned about the /page being blocked. Not sure how that benefits my blog from an SEO point of view as well. Look forward to your feedback. Thanks. Eddy User-agent: Googlebot Crawl-delay: 10 Allow: /* User-agent: * Crawl-delay: 10 Disallow: /wp- Disallow: /feed/ Disallow: /trackback/ Disallow: /rss/ Disallow: /comments/feed/ Disallow: /page/ Disallow: /date/ Disallow: /comments/ # Allow Everything Allow: /*
Intermediate & Advanced SEO | | workathomecareers0 -

Googlebot Can't Access My Sites After I Repair My Robots File
Hello Mozzers, A colleague and I have been collectively managing about 12 brands for the past several months and we have recently received a number of messages in the sites' webmaster tools instructing us that 'Googlebot was not able to access our site due to some errors with our robots.txt file' My colleague and I, in turn, created new robots.txt files with the intention of preventing the spider from crawling our 'cgi-bin' directory as follows: User-agent: * Disallow: /cgi-bin/ After creating the robots and manually re-submitting it in Webmaster Tools (and receiving the green checkbox), I received the same message about Googlebot not being able to access the site, only difference being that this time it was for a different site that I manage. I repeated the process and everything, aesthetically looked correct, however, I continued receiving these messages for each of the other sites I manage on a daily-basis for roughly a 10-day period. Do any of you know why I may be receiving this error? is it not possible for me to block the Googlebot from crawling the 'cgi-bin'? Any and all advice/insight is very much welcome, I hope I'm being descriptive enough!
Intermediate & Advanced SEO | | NiallSmith1 -

Missing Title Tags on Include Files?
GWT is telling me 3 of my include files (Contact Form - Header - Footer) are missing a Title Tag. This has never happened to me before and don't know how to tackle it. On the other hand the warning refers to a subdirectory of my site to these respective include files… The main directory, with literally the same html structure and no Title, returns no errors. Any ideas as to why this error now? or how to fix it? Thanks,
Intermediate & Advanced SEO | | dhidalgo10 -

Robots
I have just noticed this in my code name="robots" content="noindex"> And have noticed some of my keywords have dropped, could this be the reason?
Intermediate & Advanced SEO | | Paul780 -

Not using a robot command meta tag
Hi SEOmoz peeps. Was doing some research on robot commands and found a couple major sites that are not using them. If you check out the code for these: http://www.amazon.com http://www.zappos.com http://www.zappos.com/product/7787787/color/92100 http://www.altrec.com/ You fill not find a meta robot command line. Of course you need the line for any noindex, nofollow, noarchive pages. However for pages you want crawled and indexed, is there any benefit for not having the line at all? Thanks!
Intermediate & Advanced SEO | | STPseo0 -

XML Sitemap instruction in robots.txt = Worth doing?
Hi fellow SEO's, Just a quick one, I was reading a few guides on Bing Webmaster tools and found that you can use the robots.txt file to point crawlers/bots to your XML sitemap (they don't look for it by default). I was just wondering if it would be worth creating a robots.txt file purely for the purpose of pointing bots to the XML sitemap? I've submitted it manually to Google and Bing webmaster tools but I was thinking more for the other bots (I.e. Mozbot, the SEOmoz bot?). Any thoughts would be appreciated! 🙂 Regards, Ash
Intermediate & Advanced SEO | | AshSEO20110 -

Sitemaps. When compressed do you use the .gz file format or the (untidy looking, IMHO) .xml.gz format?
When submitting compressed sitemaps to Google I normally use the a file named sitemap.gz A customer is banging on that his web guy says that sitemap.xml.gz is a better format. Google spiders sitemap.gz just fine and in Webmaster Tools everything looks OK... Interested to know other SEOmoz Pro's preferences here and also to check I haven't made an error that is going to bite me in the ass soon! Over to you.
Intermediate & Advanced SEO | | NoisyLittleMonkey0