Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
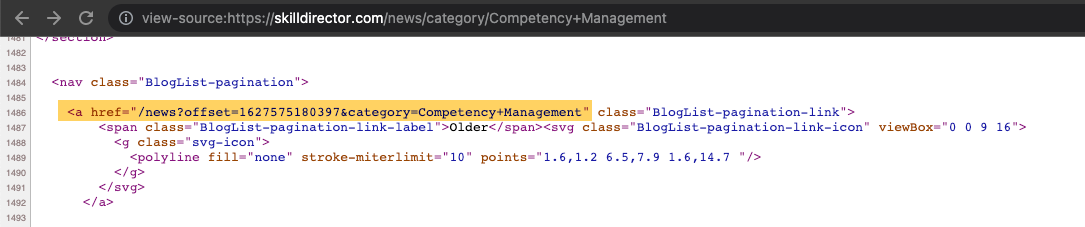
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved How can I shorten a url?
I've got way too many long url's but I have no idea how to shorten them?
Getting Started | | laurentjb0 -

Unsolved Crawler was not able to access the robots.txt
I'm trying to setup a campaign for jessicamoraninteriors.com and I keep getting messages that Moz can't crawl the site because it can't access the robots.txt. Not sure why, other crawlers don't seem to have a problem and I can access the robots.txt file from my browser. For some additional info, it's a SquareSpace site and my DNS is handled through Cloudflare. Here's the contents of my robots.txt file: # Squarespace Robots Txt User-agent: GPTBot User-agent: ChatGPT-User User-agent: CCBot User-agent: anthropic-ai User-agent: Google-Extended User-agent: FacebookBot User-agent: Claude-Web User-agent: cohere-ai User-agent: PerplexityBot User-agent: Applebot-Extended User-agent: AdsBot-Google User-agent: AdsBot-Google-Mobile User-agent: AdsBot-Google-Mobile-Apps User-agent: * Disallow: /config Disallow: /search Disallow: /account$ Disallow: /account/ Disallow: /commerce/digital-download/ Disallow: /api/ Allow: /api/ui-extensions/ Disallow: /static/ Disallow:/*?author=* Disallow:/*&author=* Disallow:/*?tag=* Disallow:/*&tag=* Disallow:/*?month=* Disallow:/*&month=* Disallow:/*?view=* Disallow:/*&view=* Disallow:/*?format=json Disallow:/*&format=json Disallow:/*?format=page-context Disallow:/*&format=page-context Disallow:/*?format=main-content Disallow:/*&format=main-content Disallow:/*?format=json-pretty Disallow:/*&format=json-pretty Disallow:/*?format=ical Disallow:/*&format=ical Disallow:/*?reversePaginate=* Disallow:/*&reversePaginate=* Any ideas?
Getting Started | | andrewrench0 -

Unsolved How do I cancel this crawl?
The latest crawl on my site was the 4th Jan with a current crawl 'in progress'. How do i cancel this crawl and start a new one? I've been getting keyword ranking etc but no new issues are coming through. Screenshot 2022-05-31 083642.jpg
Moz Tools | | ClaireU0 -

Unsolved Performance Metrics crawl error
I am getting an error:
Product Support | | bhsiao 0
Crawl Error for mobile & desktop page crawl - The page returned a 4xx; Lighthouse could not analyze this page.
I have Lighthouse whitelisted, is there any other site I need to whitelist? Anything else I need to do in Cloudflare or Datadome to allow this tool to work?1 -
Duplicate Page Titles & Content
We have just launched a new version of a website and after running it through SEOMOZ we have over 6000 duplicate title & content errors. (awesome) 😕 We have products that show up multiple times under different URLs however we "thought" we had implemented the rel=canonical correctly. My question is - do these errors still show up in SEOMOZ despite the canonical tags being there OR if they were "correct" would we be getting "zero" errors?
Moz Pro | | ZaddleMarketing0 -

After I make corrections of my crawl diagnostics report, how can I tell is those corrections "took". Is there a way to immediatly refresh that report. Will it eventually refresh?'
I have made corrections to the crawl diagnostics report. Can I refresh this report? I would like to see if my corrections were correct. Thanks for your anticipated answer!
Moz Pro | | Bob550 -

Crawl Report Warnings
How much notice should be paid to the warnings on the SEO Moz crawl reports? We manage a fairly large property site and a lot of the errors on the crawl reports relate to automated responses. As a matter of priority which of the list below will have negative affects with the search engines? Temporary RedirectToo Many On-Page LinksOverly-Dynamic URLTitle Element Too Long (> 70 Characters)Title Missing or EmptyDuplicate Page ContentDuplicate Page TitleMissing Meta Description Tag
Moz Pro | | SoundinTheory0 -

"no urls with duplicate content to report"
Hi there, i am trying to clean up some duplicate content issues on a website. The crawl diagnostics says that one of the pages has 8 other URLS with the same content. When i click on the number "8" to see the pages with duplicate content, i get to a page that says "no urls with duplicate content to report". Why is this happening? How do i fix it?
Moz Pro | | fourthdimensioninc0