Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
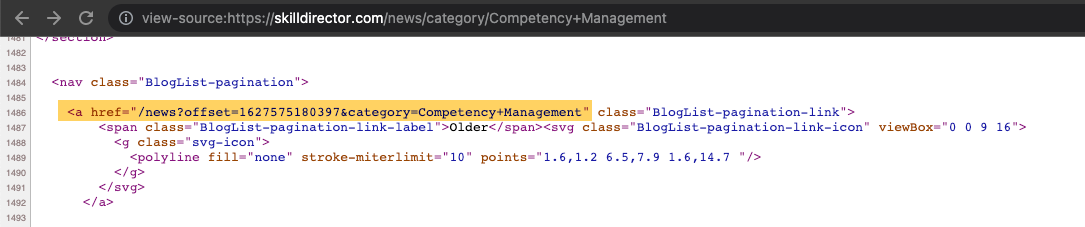
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Crawling error emails
Recently we start having random error messages about crawling issue:
Product Support | | DTashjian
2024-08-30 edweek:Ok
2024-08-29 marketbrief:Err. advertise: Err, edweek:Err, topschooljobs:Ok
2024-08-23 edweek:Ok
2024-08-22 marketbrief:Err. advertise: Err, edweek:Err
2024-08-21 topschooljobs:Ok, edweek:Ok
2024-08-15 marketbrief:Ok. advertise:OK
2024-08-13 edweek:Ok
2024-08-12 marketbrief:Ok
2024-08-08 marketbrief:Ok, advertise:Ok
2024-08-03 edweek:Ok, topschooljobs:Ok
All for 2024-07 - are Ok Yesterday I set 2 more crawls for the same sites (edweek and marketbrief) and I get a morning email about original edweek site is ok (still have some problem but crawl occurs and all is fine) but for test crawl for the same site "EW Test" I just got error email.
Also I suppressed ALL email communications and frankly surprised by this email. Can you please check what is wrong with a crawler or stat collection or I don't know who produced the issues.0 -

Unsolved How can I shorten a url?
I've got way too many long url's but I have no idea how to shorten them?
Getting Started | | laurentjb0 -

Unsolved Moz crawler not working
Hi Moz crawler keep failing on my site with the error showing : Our crawler was banned by a page on your site, either through your robots.txt, the X-Robots-Tag HTTP header, or the meta robots tag. I'm not sure what am I missing out.. this is my robots.txt.. i don't think Im missing anything else.. https://www.wearefutureheads.com/robots.txt can the support team help ?
Moz Pro | | teikh0 -
Unsolved Moz crawler not crawling on my site
Hi all, im facing an issue where moz crawler is unable to crawl my site. The following error keeps showing Our crawler was banned by a page on your site, either through your robots.txt, the X-Robots-Tag HTTP header, or the meta robots tag. This is my robots.txt file : https://www.wearefutureheads.com/robots.txt I'm not sure what else am I missing.. can anyone help
Product Support | | teikh0 -

Unsolved Rogerbot blocked by cloudflare and not display full user agent string.
Hi, We're trying to get MOZ to crawl our site, but when we Create Your Campaign we get the error:
Moz Pro | | BB_NPG
Ooops. Our crawlers are unable to access that URL - please check to make sure it is correct. If the issue persists, check out this article for further help. robot.txt is fine and we actually see cloudflare is blocking it with block fight mode. We've added in some rules to allow rogerbot but these seem to be getting ignored. If we use a robot.txt test tool (https://technicalseo.com/tools/robots-txt/) with rogerbot as the user agent this get through fine and we can see our rule has allowed it. When viewing the cloudflare activity log (attached) it seems the Create Your Campaign is trying to crawl the site with the user agent as simply set as rogerbot 1.2 but the robot.txt testing tool uses the full user agent string rogerbot/1.0 (http://moz.com/help/pro/what-is-rogerbot-, rogerbot-crawler+shiny@moz.com) albeit it's version 1.0. So seems as if cloudflare doesn't like the simple user agent. So is it correct the when MOZ is trying to crawl the site it uses the simple string of just rogerbot 1.2 now ? Thanks
Ben Cloudflare activity log, showing differences in user agent strings
2022-07-01_13-05-59.png0 -

Dead links-urls
What is the quickest way to get Google to clean up dead
Moz Pro | | 1step2heaven
link? I have 74,000 dead links reported back, i have added a robot txt to
disallow and added on Google list remove from my webmaster tool 4 months ago.
The same dead links also show on the open site explores. Thanks0 -

How long is a full crawl?
It's been now over 3 days that the dashboard for one of our campaigns shows "Next Crawl in Progress!". I am not complaining about the length... but I have to agree that SEOMoz is quite addictive, and it's quite frustrating to see that everyday 🙂 Thanks
Moz Pro | | jgenesto0 -

Crawl frequency
What is the frequency of crawl. My crawl diagnostics shows data from over a month ago
Moz Pro | | deBreezeInteractive0