After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Htaccess and robots.txt and 902 error
-
Hi this is my first question in here I truly hope someone will be able to help. It's quite a detailed problem and I'd love to be able to fix it through your kind help.
It regards htaccess files and robot.txt files and 902 errors.
In October I created a WordPress website from what was previously a non-WordPress site it was quite dated. I had built the new site on a sub-domain I created on the existing site so that the live site could remain live whilst I created on the subdomain. The site I built on the subdomain is now live but I am concerned about the existence of the old htaccess files and robots txt files and wonder if I should just delete the old ones to leave the just the new on the new site.
I created new htaccess and robots.txt files on the new site and have left the old htaccess files there. Just to mention that all the old content files are still sat on the server under a folder called 'old files' so I am assuming that these aren't affecting matters. I access the htaccess and robots.txt files by clicking on 'public html' via ftp
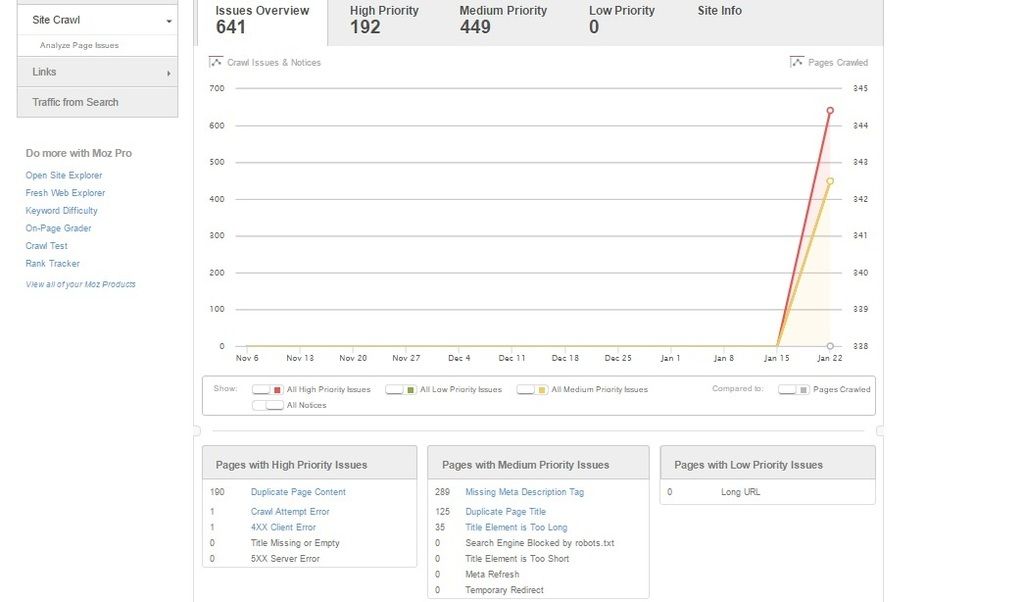
I did a Moz crawl and was astonished to 902 network error saying that it wasn't possible to crawl the site, but then I was alerted by Moz later on to say that the report was ready..I see 641 crawl errors ( 449 medium priority | 192 high priority | Zero low priority ). Please see attached image. Each of the errors seems to have status code 200; this seems to be applying to mainly the images on each of the pages: eg domain.com/imagename .
The new website is built around the 907 Theme which has some page sections on the home page, and parallax sections on the home page and throughout the site. To my knowledge the content and the images on the pages are not duplicated because I have made each page as unique and original as possible. The report says 190 pages have been duplicated so I have no clue how this can be or how to approach fixing this.
Since October when the new site was launched, approx 50% of incoming traffic has dropped off at the home page and that is still the case, but the site still continues to get new traffic according to Google Analytics statistics. However Bing Yahoo and Google show a low level of Indexing and exposure which may be indicative of the search engines having difficulty crawling the site. In Google Analytics in Webmaster Tools, the screen text reports no crawl errors.
W3TC is a WordPress caching plugin which I installed just a few days ago to speed up page speed, so I am not querying anything here about W3TC unless someone spots that this might be a problem, but like I said there have been problems re traffic dropping off when visitors arrive on the home page.
The Yoast SEO plugin is being used. I have included information about the htaccess and robots.txt files below. The pages on the subdomain are pointing to the live domain as has been explained to me by the person who did the site migration. I'd like the site to be free from pages and files that shouldn't be there and I feel that the site needs a clean up as well as knowing if the robots.txt and htaccess files that are included in the old site should actually be there or if they should be deleted...
ok here goes with the information in the files. Site 1) refers to the current website. Site 2) refers to the subdomain. Site 3 refers to the folder that contains all the old files from the old non-WordPress file structure.
**************** 1) htaccess on the current site: *********************
BEGIN W3TC Browser Cache
<ifmodule mod_deflate.c=""><ifmodule mod_headers.c="">Header append Vary User-Agent env=!dont-vary</ifmodule>
<ifmodule mod_filter.c="">AddOutputFilterByType DEFLATE text/css text/x-component application/x-javascript application/javascript text/javascript text/x-js text/html text/richtext image/svg+xml text/plain text/xsd text/xsl text/xml image/x-icon application/json
<ifmodule mod_mime.c=""># DEFLATE by extension
AddOutputFilter DEFLATE js css htm html xml</ifmodule></ifmodule></ifmodule>END W3TC Browser Cache
BEGIN W3TC CDN
<filesmatch ".(ttf|ttc|otf|eot|woff|font.css)$"=""><ifmodule mod_headers.c="">Header set Access-Control-Allow-Origin "*"</ifmodule></filesmatch>
END W3TC CDN
BEGIN W3TC Page Cache core
<ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /
RewriteCond %{HTTP:Accept-Encoding} gzip
RewriteRule .* - [E=W3TC_ENC:_gzip]
RewriteCond %{HTTP_COOKIE} w3tc_preview [NC]
RewriteRule .* - [E=W3TC_PREVIEW:_preview]
RewriteCond %{REQUEST_METHOD} !=POST
RewriteCond %{QUERY_STRING} =""
RewriteCond %{REQUEST_URI} /$
RewriteCond %{HTTP_COOKIE} !(comment_author|wp-postpass|w3tc_logged_out|wordpress_logged_in|wptouch_switch_toggle) [NC]
RewriteCond "%{DOCUMENT_ROOT}/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}" -f
RewriteRule .* "/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}" [L]</ifmodule>END W3TC Page Cache core
BEGIN WordPress
<ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]</ifmodule>END WordPress
....(((I have 7 301 redirects in place for old page url's to link to new page url's)))....
#Force non-www:
RewriteEngine on
RewriteCond %{HTTP_HOST} ^www.domain.co.uk [NC]
RewriteRule ^(.*)$ http://domain.co.uk/$1 [L,R=301]**************** 1) robots.txt on the current site: *********************
User-agent: *
Disallow:
Sitemap: http://domain.co.uk/sitemap_index.xml**************** 2) htaccess in the subdomain folder: *********************
Switch rewrite engine off in case this was installed under HostPay.
RewriteEngine Off
SetEnv DEFAULT_PHP_VERSION 53
DirectoryIndex index.cgi index.php
BEGIN WordPress
<ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /WPnewsiteDee/
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /subdomain/index.php [L]</ifmodule>END WordPress
**************** 2) robots.txt in the subdomain folder: *********************
this robots.txt file is empty
**************** 3) htaccess in the Old Site folder: *********************
Deny from all
*************** 3) robots.txt in the Old Site folder: *********************
User-agent: *
Disallow: /
I have tried to be thorough so please excuse the length of my message here. I really hope one of you great people in the Moz community can help me with a solution. I have SEO knowledge I love SEO but I have not come across this before and I really don't know where to start with this one.
Best Regards to you all and thank you for reading this.
-
Here is an update as to what is happening so far. Please excuse the length of this message.
-
The database according to the host is fine (please see below) but WordPress is still calling https:
-
In the WP database wp-actions, http is definitely being called* All certificates are ok and SSL is not active* The WordPress database is returning properly* The WP database mechanics are ok* The WP config-file is not doing https returns, it is calling http correctly
-
They said that the only other possibility could be one of the plugins causing the problem. But how can a plugin cause https problems?...I can see 50 different https pages indexed in Google. Bing has been checked and there are no https pages indexed there. All internal urls always have been http only and that is still the case.
-
I have Google fetched the website pages and in the 50 https pages most are images which I think probably must have came from the Yoast sitemap which was originally submitted to the search engines (more recently though I have taken all media image url's out of the Yoast sitemap and put noindex, follow on all image attachments files (the pages and the images on the pages will still be crawled and indexed in Google and search engines, it just means that any image url's won't. What will happen to those unwanted https files though? If I place rel canonical links on the pages that matter will the https pages drop out of the index eventually? I just wish I could find what is causing it (analogy: best to fix a hole in a roof to stop having to use a bowl to catch the water each time it rains).
-
** I looked at analytics today and saw something really interesting (see attached image) - you can see 5 instances of the trailing slash at the home page and to my knowledge there should only be 1 for a website. The Moz Crawl shows just 1 home domain http://example.co.uk/ so I am somewhat confused. Google search results showed 256 results for https url references, and there were 50 available to click on. So perhaps there are 50 https pages being referenced for each trailing slash (could there be 4 other trailing slash duplicate pages indexed and how would I fix it if that is the case?). This might sound naive but I don't have the skillset to fix this at this time so any help and advice would be appreciated.
-
Would Search and Replace plugin help at all or would it be a waste of time since the WordPress database mechanics seem to be ok.
-
I can't place any https to http 301 redirects for the 50 https url's that are indexed in Google, and I can't add any https rewrite rules in htaccess since that type of redirect will only work if a SSL is active. I already tried several redirect rules in htaccess and as expected they wouldn't work which again would probably mean that the SSL is not active for the site.
-
When https is entered instead of http, there should be an automatic resolve to http without me having to worry about that, but I tried again and the https version with a red diagonal line through it appears instead. The problem is that once a web visitor lands on that page they stay in that land of https (visually the main nav bar contents stretch across the page and the images and videos don't appear), and so the traffic will drop off..so hence a bad experience for the user and dropped traffic, decreasing income and bad for seo (split page juice, decreased rankings). There are no crawl errors in Google Search Console and Analytics shows Google Fetch completed for all pages - but when I request fetch and render for the home page it shows as partial instead of completed.
-
I don't want to request any https url removals through Google and search engines - it's not recommended because Google states that http version could be removed as well as https.
-
I did look at this last week:
http://www.screamingfrog.co.uk/5-easy-steps-to-fix-secure-page-https-duplicate-content/
-
Do you think that the https urls are indexed because of links pointing to the site are using https? Perhaps most of the backlinks are https but the preferred setting in Webmaster Tools / Search Console is already set to the non-www version instead of the www version; there has never been a https version of the site.
-
This was one possibility re duplicate content. Here are two pages and the listed duplicates:
-
The first Moz crawl I ever requested came back with hundreds of duplicate errors and I have resolved this. Google crawl had not picked this up previously (so I figured everything had been ok) and it was only realised after that Moz crawl. So https links were seen to be indexed and so the goals are to stop the root cause of the problem and to fix the damage so that any https url's can drop off out of the serps and the index.
-
I considered that the duplicate links in question might not be considered as true duplicates as such - it is actually just that the duplicate pages (these were page attachments created by WordPress for each image uploaded to the site) have no real content so the template elements outweighed the actual unique content elements which was flagging them as duplicates in the moz tool. So I thought that these were unlikely to hurt as they were not duplicates as such but they were indexed thin content. I did a content audit and tidy tidied things up as much as I could (blank pages and weak ones) hence the new recent sitemap submission and fetch to Google.
-
I have already redirected all attachments to the parent page in Yoast, and removed all attachments from the Yoast sitemap and set all media content (in Yoast) to 'noindex, follow'.
-
Naturally it's really important to eliminate the https problem before external backlinks link back to any of the unwanted https pages that are currently indexed. Luckily I haven't started any backlinking work yet, and any links I have posted in search land have all been http version. As I understand it, most server configurations should redirect by default to http when https isn’t configured, so I am confused as to where to take this especially as the host has given the WP database the all clear.
-
It could be taxonomies related to the theme or a slider plugin as I have learned these past few weeks. Disallowing and deindexing those unwanted http URLs would be amazing since I have so far spent weeks already trying to get to the bottom of the problem.
-
Ideally I understand from previous weeks that these 2 things would be very important:
(1)301 redirects from http to https (the host in this case cannot enable this directly through their servers and I can only add these redirects in the htaccess file if there is an active SSL in place).(2)Have in place a canonical url using http for both the http and https variations. Both of those solutions might work on their own and if the 301 redirect can't work with the host then the canonical will fix it? I saw that I could just set a canonical with a fixed transport protocol of http:// - then Google will then sort out the rest. Not preferred from a crawl perspective but would suffice? (Even so I don't know how to put that in place).
-
There are around 180 W3C validation errors. Would it help matters to get these fixed? Would this help to fix the problem do you know? The homepage renders with critical errors and a couple of warnings.
-
The 907 Theme scores well for its concept and functionality but its SEO reviews aren't that great.
-
Duplicate problems are not related to the W3 Total Cache plugin which is one of the plugins in place.
-
Regarding addons (trailing slash): Example: http://domain.co.uk/events redirects to http://domain.co.uk/events/ the addon must only do it on active urls - even if it didn't there were no reports of / duplicate errors in the Moz Crawl so its a different issue that would need looking at separately I would think.
-
At the bottom of each duplicate page there is an option for noindex. There are page sections and parallax sections that make up the home page, and each has to be published to become a live part of the home page. This isn't great for SEO I understand that because only the top page section is registered in Yoast as being the home page the other sections on the home page are not crawled as part of the home page but are instead separate page sections. Is it ok to index those page sections? If I noindex, follow them would that be good practice here. The theme does not auto block the page section from appearing in search engines.
-
Can noindex only be put on whole pages and not the specific page sections? I just want to make sure that the content on all the pages (media and text) and page sections are crawlable.
-
To ultimately fix the https problem re indexed pages out there could this eventually be a case of having to add SSL to the site just because there is no better way - just so the https to http redirect rule can be added to the htaccess file? If so, I don't think that would fix the root cause of the problem, but the root cause could be one of the plugins? Confused.
-
With Canonical url's does that mean the https links that don't have canonicals will deindex eventually? Are the https links giving a 404 (I'm worried because normally 404's need 301's as you know and I can't put a 301 on a https url in this situation). Do I have to do set a canonical for every single page on the website because of the extent of the problem that has occurred?
-
Nearly all of the traffic is being dropped after visiting the home page, and I can't for the life of me see why. Is it because of all these https pages? Once canonicals are in place how long will it take for everything to return to how it should be? Is it worthwhile starting a ppc campaign or should I wait until everything has calmed down on the site?
-
Is this a case of setting the canonical URL and then the rest will sort itself out? (please see the screenshot attached regarding the 5 home pages that each have a trailing slash).
-
This is the entire current situation. I understand this might not be so straight forward but I would really appreciate help as the site continues to drop traffic and income. Others will be able to learn from this string of questions and responses too. Thank you for reading this far and have a nice day. Kind Regards,
-
-
Hi I replied to you there. Please PM me back thanks.
-
PM sent
-
Hi thanks can you explain this in a way that I can properly understand. A lot of what I asked hasn't been addressed: eg what do I do with the older htaccess and robots.txt filesand what is causing the 902 error. A step by step guide would be preferable as I would like to implement the changes. There are only 7 redirects in place and those and the instruction from the caching plugin are working fine as far as I can see. The force non-www works but are you saying that everything inside the htaccess file isn't correct? L flag?
Are you saying to just reorder from:
W3TC cache setW3TC compression set
W3TC CDN
W3TC page cache
WordPress handler - with L flag!
Redirects
Force non-wwwto this:
Force non-www
Redirects
W3TC
WordPress handler..and then run another Moz Crawl?
Could there be any chance at all of the old robots.txt and old htaccess files impeding or conflicting with the new htaccess and robts.txt files? The 902 error and the page duplication will be solved if I put your changes into place?
Thanks I look forward to resolving this, 50% of traffic is dropping off at the home page (see attached image). Thanks
-
Usual .htaccess mess... WHY? Because of flags:
https://httpd.apache.org/docs/2.4/rewrite/flags.htmlAs you can see there are few flags L, R, NC and other. But we will focus on L and R only:
R - redirect. This make 302 redirect but you can specify other response codes between 301 and 399. Example R=301.
L - last. This flag causes mod_rewrite to stop processing the rule set.Let's go back on your file here is structure:
W3TC cache setW3TC compression set
W3TC CDN
W3TC page cache
WordPress handler - with L flag!
Redirects
Force non-wwwWhat is the problem? The problem is that after L flag - everything is stopped. This mean that www and non-www works and no redirect between them. You need to make changes in your file as this:
Force non-www
Redirects
W3TC
WordPress handlerAnd check and recheck everything one more time. Including redirects.
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-