Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
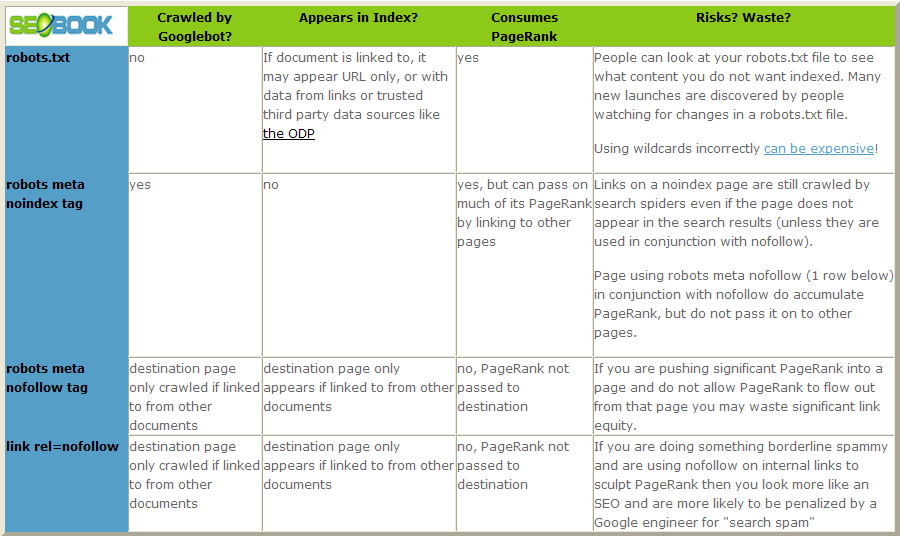
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Meta name Author
Hello! I have a problem. I'm using Rank Math for WordPress. But I can’t configure a basic thing such as <meta name="author" content="" />. I had to insert this code manually using the hook. Does anyone know a normal way to do this markup? Example page: https://b-shoes.com/foot-shaped-shoes/ Thank you!
Technical SEO | | WayneM.0 -

Do you need a canonical tag for search and filter pages?
Hi Moz Community, We've been implementing new canonical tags for our category pages but I have a question about pages that are found via search and our filtering options. Would we still need a canonical tag for pages that show up in search + a filter option if it only lists one page of items? Example below. www.uncommongoods.com/search.html/find/?q=dog&exclusive=1 Thanks!
Technical SEO | | znotes0 -

Pagination when not needed
Hello Moz, Odd one for you today. I've a site with has pagination (rel= next / prev) however its not being used correctly. I'll give you some examples: lets assume its a 5 page site with a home page, about us etc. The home page has a rel="next" tag on it leading to the next tab (about us) this goes all the way down to the final tag (contact us). Normally you use these tags for pages e.g page 1 - 5 but how much will they affect being used in the way above I'm thinking site structure. Just to add there is no view all on it either though this would make no sense in the way it is being used. Normally I would remove but the client wants to know why and I wanted to articulate better then "because its wrong" As always Moz - thanks!
Technical SEO | | GPainter0 -

Robots.txt anomaly
Hi, I'm monitoring a site thats had a new design relaunch and new robots.txt added. Over the period of a week (since launch) webmaster tools has shown a steadily increasing number of blocked urls (now at 14). In the robots.txt file though theres only 12 lines with the disallow command, could this be occurring because a line in the command could refer to more than one page/url ? They all look like single urls for example: Disallow: /wp-content/plugins
Technical SEO | | Dan-Lawrence
Disallow: /wp-content/cache
Disallow: /wp-content/themes etc, etc And is it normal for webmaster tools reporting of robots.txt blocked urls to steadily increase in number over time, as opposed to being identified straight away ? Thanks in advance for any help/advice/clarity why this may be happening ? Cheers Dan0 -

Can't find mistake in robots.txt
Hi all, we recently filled our robots.txt file to prevent some directories from crawling. Looks like: User-agent: * Disallow: /Views/ Disallow: /login/ Disallow: /routing/ Disallow: /Profiler/ Disallow: /LILLYPROFILER/ Disallow: /EventRweKompaktProfiler/ Disallow: /AccessIntProfiler/ Disallow: /KellyIntProfiler/ Disallow: /lilly/ now, as Google Webmaster Tools hasn't updated our robots.txt yet, I checked our robots.txt in some ckeckers. They tell me that the User agent: * contains an error. **Example:** **Line 1: Syntax error! Expected <field>:</field> <value></value> 1: User-agent: *** **`I checked other robots.txt written the same way --> they work,`** accordign to the checkers... **`Where the .... is the mistake???`** ```
Technical SEO | | accessKellyOCG0 -

Oh no googlebot can not access my robots.txt file
I just receive a n error message from google webmaster Wonder it was something to do with Yoast plugin. Could somebody help me with troubleshooting this? Here's original message Over the last 24 hours, Googlebot encountered 189 errors while attempting to access your robots.txt. To ensure that we didn't crawl any pages listed in that file, we postponed our crawl. Your site's overall robots.txt error rate is 100.0%. Recommended action If the site error rate is 100%: Using a web browser, attempt to access http://www.soobumimphotography.com//robots.txt. If you are able to access it from your browser, then your site may be configured to deny access to googlebot. Check the configuration of your firewall and site to ensure that you are not denying access to googlebot. If your robots.txt is a static page, verify that your web service has proper permissions to access the file. If your robots.txt is dynamically generated, verify that the scripts that generate the robots.txt are properly configured and have permission to run. Check the logs for your website to see if your scripts are failing, and if so attempt to diagnose the cause of the failure. If the site error rate is less than 100%: Using Webmaster Tools, find a day with a high error rate and examine the logs for your web server for that day. Look for errors accessing robots.txt in the logs for that day and fix the causes of those errors. The most likely explanation is that your site is overloaded. Contact your hosting provider and discuss reconfiguring your web server or adding more resources to your website. After you think you've fixed the problem, use Fetch as Google to fetch http://www.soobumimphotography.com//robots.txt to verify that Googlebot can properly access your site.
Technical SEO | | BistosAmerica0 -

Quick robots.txt check
We're working on an SEO update for http://www.gear-zone.co.uk at the moment, and I was wondering if someone could take a quick look at the new robots file (http://gearzone.affinitynewmedia.com/robots.txt) to make sure we haven't missed anything? Thanks
Technical SEO | | neooptic0