Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
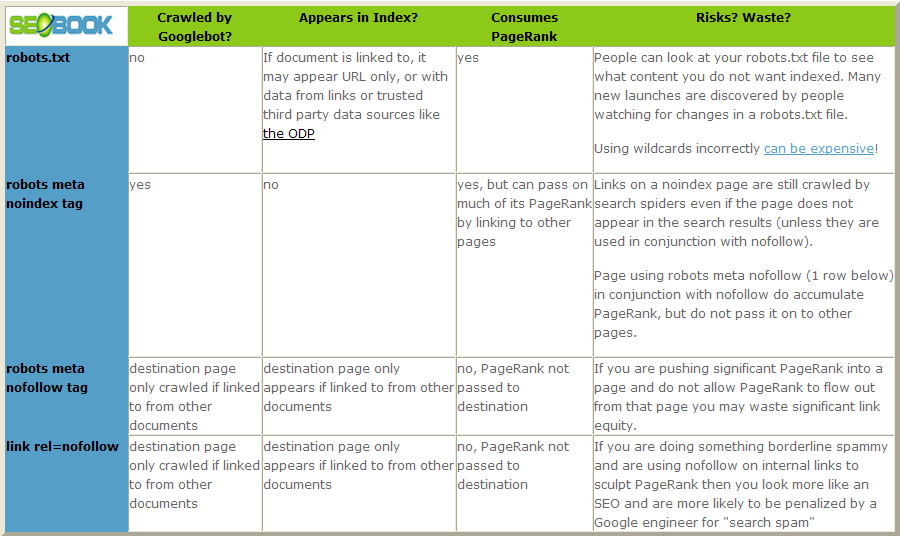
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Meta Title Tags - Quick question!
Hi all, Our category Meta Title Tags are a little woeful and so I'm in the process of rewriting them. Let's say you have a product for sale.... some inkjet cartridges for a Canon BJ10V printer for example. In an effort to keep things concise I was thinking that for this category I should have the meta title set simply as: 'Canon BJ10V Inkjet Cartridges' and perhaps our company name after this text (and a pipe delimiter) This takes us just under 50 characters which is ideal but doesn't include any real keyword variation and will result in the company name being duplicated at the tail of the title tag on 6,000 odd pages. A large number of my competitors have title tags along the lines of: 'Canon BJ10V Cheap Inkjet Cartridges for Canon BJ-10V Ink Printers' I understand the reasoning behind this but does the variation of keywords compensate for the fact that the title looks spammy (to both humans and Search Engines). What would you do? Keep it clean and concise or stuff the title full of keywords. In the event of the former would you include the company name in each title in the knowledge they would be well under 50 characters without? Thanks for your help.
Technical SEO | | ChrisHolgate1 -

Indexing pages content that is not needed
Hi All, I have a site that has articles and a side block that shows interesting articles in a column block. While we google for a keyword i can see the page but the meta description is picked from the side block "interesting articles" and not the actual article in the page. How can i deny indexing that block alone Thanks
Technical SEO | | jomin740 -

Robots.txt
Hello, My client has a robots.txt file which says this: User-agent: * Crawl-delay: 2 I put it through a robots checker which said that it must have a **disallow command**. So should it say this: User-agent: * Disallow: crawl-delay: 2 What effect (if any) would not having a disallow command make? Thanks
Technical SEO | | AL123al0 -

How long after google crawl do you need 301 redirects
We have just added 301's when we moved our site. Google has done a crawl & spat back a few errors. How long do I need to keep those 301's in place? I may need to change some. Thanks
Technical SEO | | Paul_MC0 -

Site blocked by robots.txt and 301 redirected still in SERPs
I have a vanity URL domain that 301 redirects to my main site. That domain does have a robots.txt to disallow the entire site as well. However, for a branded enough search that vanity domain still shows up in SERPs and has the new Google message of: A description for this result is not available because of this site's robots.txt I get why the message is there - that's not my , my question is shouldn't a 301 redirect trump this domain showing in SERPs, ever? Client isn't happy about it showing at all. How can I get the vanity domain out of the SERPs? THANKS in advance!
Technical SEO | | VMLYRDiscoverability0 -

Robots.txt checker
Google seems to have discontinued their robots.txt checker. Is there another tool that I can use to check my text instead? Thanks!
Technical SEO | | theLotter0 -

Google (GWT) says my homepage and posts are blocked by Robots.txt
I guys.. I have a very annoying issue.. My Wordpress-blog over at www.Trovatten.com has some indexation-problems.. Google Webmaster Tools data:
Technical SEO | | FrederikTrovatten22
GWT says the following: "Sitemap contains urls which are blocked by robots.txt." and shows me my homepage and my blogposts.. This is my Robots.txt: http://www.trovatten.com/robots.txt
"User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/ Do you have any idea why it says that the URL's are being blocked by robots.txt when that looks how it should?
I've read a couple of places that it can be because of a Wordpress Plugin that is creating a virtuel robots.txt, but I can't validate it.. 1. I have set WP-Privacy to crawl my site
2. I have deactivated all WP-plugins and I still get same GWT-Warnings. Looking forward to hear if you have an idea that might work!0 -

Duplicate Meta Description in GWMT
We've just discovered that there are multiple duplicate URLs indexed for a site that we're working on. It seems that when new versions of the site was developed in the last couple of years, there were new page names and URL structures that were used. All of these seem to be showing up as Duplicate Meta Descriptions in Google's WMT, which is not surprising as they are basically the same page with the same content that are just sitting on different page names/URLs. This is an example of the situation, where URL 5 is the current version. Note: all the others are still live and resolve, although they are not linked to from the current site. URL 1: www.example.com/blue-tshirts.html (Version 1 - January 2010) URL 2: www.example.com/blue-t-shirts.html (Version 2 - July 2010) URL 3: www.example.com/blue_t_shirts.html (Version 3 - November 2010) URL 4: www.example.com/buy/blue_tshirts.html (Version 4 - January 2011) URL 5: www.example.com/buy/bluetshirts.html (Version 5 - April 2011) Presumably, this is a clear case of duplicate content. QUESTION: In order to solve it, shall we 301 all of the previous URLs to the current one - ie. Redirect URLs 1-4 to URL 5? Or, should some of them be NoIndexed? To complicate matters, there is Pagination on most of them. For example: URL 1: www.example.com/blue-tshirts.html (Version 1 - January 2010) URL 1a: www.example.com/page-1/blue-tshirts.html URL 1b: www.example.com/page-2/blue-tshirts.html URL 1c: www.example.com/page-3/blue-tshirts.html URL 4: www.example.com/buy/blue_tshirts.html URL 4a: www.example.com/buy/page-1/blue_tshirts.html URL 4b: www.example.com/buy/page-2/blue_tshirts.html URL 4c: www.example.com/buy/page-3/blue_tshirts.html URL 5: www.example.com/buy/bluetshirts.html URL 5a: www.example.com/buy/page-1/bluetshirts.html URL 5b: www.example.com/buy/page-2/bluetshirts.html URL 5c: www.example.com/buy/page-3/bluetshirts.html Since URL 5 is the current site, we are going to 'NoIndex, Follow' URLs 5a, 5b and 5c, which is what we understand to be the correct thing to do for paginated pages. QUESTION: What shall we do with URLs 1a, 1b and 1c? Should we apply the same "No Index, Follow" OR should they be 301'd to their respective counterparts in 5a, 5b and 5c? QUESTION: In the same way, since URL 4 is the version just before the current live Version 5, does it make a different on whether the paginated pages (ie 4a, 4b and 4c) should be No Indexed or 301'd? Thanks in advance for all responses and suggestions, it's greatly appreciated.
Technical SEO | | orangechew0