Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
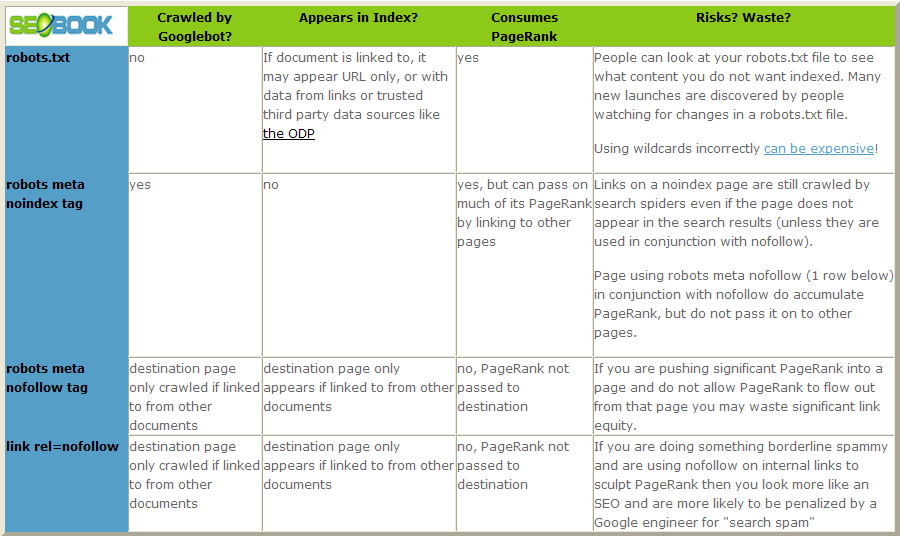
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Utilizing one robots.txt for two sites
I have two sites that are facilitated hosting in similar CMS. Maybe than having two separate robots.txt records (one for every space), my web office has made one which records the sitemaps for the two sites, similar to this:
Technical SEO | | eulabrant0 -

Crawler issues on subdomain - Need resolving?
Hey Guys, I'm fairly new to the world of SEO and have a ton of crawler issues with a friends website I'm doing some work on. After Moz did a site crawl I'm getting loads of errors (Total of 100+ for critical crawler, content and meta data). Most of these are due to broken social links on a subdomain - so my question is do I need to resolve all of the errors even if they are on a sub-domain? Will it affect the primary website? Thanks, Jack
Technical SEO | | Jack11660 -

2 sitemaps on my robots.txt?
Hi, I thought that I just could link one sitemap from my site's robots.txt but... I may be wrong. So, I need to confirm if this kind of implementation is right or wrong: robots.txt for Magento Community and Enterprise ...
Technical SEO | | Webicultors
Sitemap: http://www.mysite.es/media/sitemap/es.xml
Sitemap: http://www.mysite.pt/media/sitemap/pt.xml Thanks in advance,0 -

Animated Video and Google Ranking, need advice
Hi I will like to have a company create animated video on our home page to offer a better experience in our online store selling furnace filters and increase conversion. Can it hurt ranking? Loading Time? File format? All thing I should worry. But what about videos like this company create: http://webvideo.kickerinc.ca/explainer-videos/?gclid=CJK68770grACFYje4Aod6kR5jA# Do you have recommendation or reference about serious company producing videos animated to had on web site? Thjank you for your help, BigBlaze
Technical SEO | | BigBlaze2050 -

Google (GWT) says my homepage and posts are blocked by Robots.txt
I guys.. I have a very annoying issue.. My Wordpress-blog over at www.Trovatten.com has some indexation-problems.. Google Webmaster Tools data:
Technical SEO | | FrederikTrovatten22
GWT says the following: "Sitemap contains urls which are blocked by robots.txt." and shows me my homepage and my blogposts.. This is my Robots.txt: http://www.trovatten.com/robots.txt
"User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/ Do you have any idea why it says that the URL's are being blocked by robots.txt when that looks how it should?
I've read a couple of places that it can be because of a Wordpress Plugin that is creating a virtuel robots.txt, but I can't validate it.. 1. I have set WP-Privacy to crawl my site
2. I have deactivated all WP-plugins and I still get same GWT-Warnings. Looking forward to hear if you have an idea that might work!0 -

How do I add meta descriptions to Archives in Wordpress?
My most recent crawl returned a number of 'missing meta description' errors, and when I checked individual URLs, it turned out they were Wordpress Archived pages - for individual months and days (e.g. http:// .../2011/01). What's the best way to go about adding descriptions to these pages, if at all? Or should I have these pages not be indexed? I am using the All in One SEO plugin, so maybe there is an easy fix through this plugin, or it may be the cause of these errors? Any help is appreciated, thanks in advance! **EDIT After looking it up further, I have decided to use noindex for Archives, which should solve my problem right? Or is there a benefit to having those archived pages?
Technical SEO | | NetPicks0 -

Is robots.txt a must-have for 150 page well-structured site?
By looking in my logs I see dozens of 404 errors each day from different bots trying to load robots.txt. I have a small site (150 pages) with clean navigation that allows the bots to index the whole site (which they are doing). There are no secret areas I don't want the bots to find (the secret areas are behind a Login so the bots won't see them). I have used rel=nofollow for internal links that point to my Login page. Is there any reason to include a generic robots.txt file that contains "user-agent: *"? I have a minor reason: to stop getting 404 errors and clean up my error logs so I can find other issues that may exist. But I'm wondering if not having a robots.txt file is the same as some default blank file (or 1-line file giving all bots all access)?
Technical SEO | | scanlin0 -

Robots.txt
My campaign hse24 (www.hse24.de) is not being crawled any more ... Do you think this can be a problem of the robots.txt? I always thought that Google and friends are interpretating the file correct, seen that he site was crawled since last week. Thanks a lot Bernd NB: Here is the robots.txt: User-Agent: * Disallow: / User-agent: Googlebot User-agent: Googlebot-Image User-agent: Googlebot-Mobile User-agent: MSNBot User-agent: Slurp User-agent: yahoo-mmcrawler User-agent: psbot Disallow: /is-bin/ Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-DE-Site/de_DE/-/EUR/hse24_Storefront-Start Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-AT-Site/de_DE/-/EUR/hse24_Storefront-Start Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-CH-Site/de_DE/-/CHF/hse24_Storefront-Start Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-DE-Site/de_DE/-/EUR/hse24_DisplayProductInformation-Start Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-AT-Site/de_DE/-/EUR/hse24_DisplayProductInformation-Start Allow: /is-bin/INTERSHOP.enfinity/WFS/HSE24-CH-Site/de_DE/-/CHF/hse24_DisplayProductInformation-Start Allow: /is-bin/intershop.static/WFS/HSE24-Site/-/Editions/ Allow: /is-bin/intershop.static/WFS/HSE24-Site/-/Editions/Root%20Edition/units/HSE24/Beratung/
Technical SEO | | remino630