Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
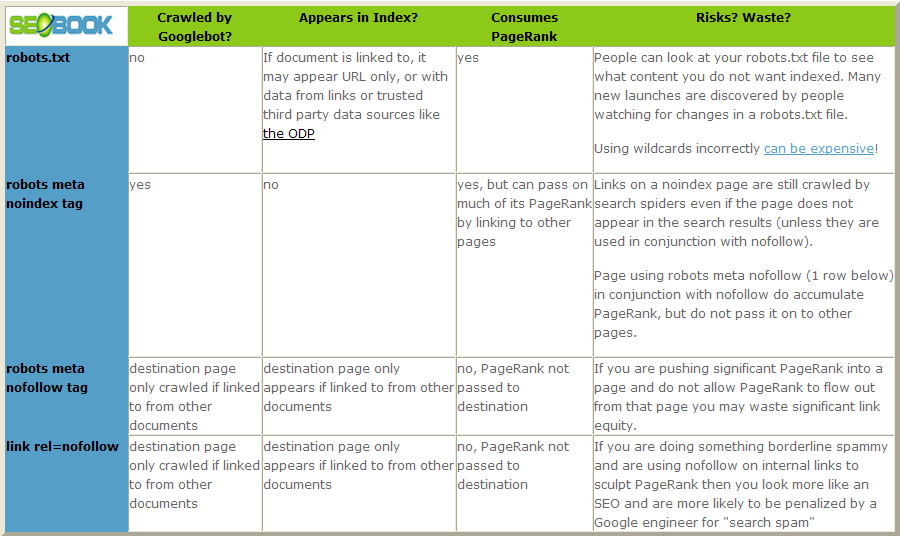
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Need help in diagnosing what I may be doing wrong
I have a site that has been having problems ranking. Initially, spam rate was at 18%. I have since changed the URL and forwarded to the original so now the spam rate is under 5%. Phone calls started picking back up very slowly but then by August 2024 things came to a screeching halt. Phone has been dead and very little business has been written. I did notice on the robots.txt file it had this: User-agent: *
Technical SEO | | SOM24
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: bingbot
Disallow: /no-bing-crawl/
Disallow: wp-admin and now I have since changed it to this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php Sitemap: https://urlishere.com/sitemap_index.xml My question is what else do I need to do to get this site to start ranking again? We are blogging once a month, writing press releases once a month, updating the social media a few times a week. I feel like maybe there is something on the backend that needs to be done to get this site back to ranking. I am using SEO by Yoast and I have filled in the title and meta description fields for all pages. There is a spot in Yoast where I can validate the site with Google, Bing, etc. I'm trying to figure out how to do that. I do see in the site's Google Webmaster Tools there are several pages not indexing. Any ideas on what else I can do to get this site to start ranking again? Thank you.0 -

X-robots tag causing no index issues
I have an interesting problem with a site which has an x-robot tag blocking the site from being indexed, the site is in Wordpress, there are no issues with the robots.txt or at the page level, I cant find the noindex anywhere. I removed the SEO plug-in which was there and installed Yoast but it made no difference. this is the url: https://www.cotswoldflatroofing.com/ Its coming up with a HTTP error: x-robots tag noindex, nofollow, noarchive
Technical SEO | | Donsimong0 -

Little confused regarding robots.txt
Hi there Mozzers! As a newbie, I have a question that what could happen if I write my robots.txt file like this... User-agent: * Allow: / Disallow: /abc-1/ Disallow: /bcd/ Disallow: /agd1/ User-agent: * Disallow: / Hope to hear from you...
Technical SEO | | DenorL0 -

Meta Title Tags - Quick question!
Hi all, Our category Meta Title Tags are a little woeful and so I'm in the process of rewriting them. Let's say you have a product for sale.... some inkjet cartridges for a Canon BJ10V printer for example. In an effort to keep things concise I was thinking that for this category I should have the meta title set simply as: 'Canon BJ10V Inkjet Cartridges' and perhaps our company name after this text (and a pipe delimiter) This takes us just under 50 characters which is ideal but doesn't include any real keyword variation and will result in the company name being duplicated at the tail of the title tag on 6,000 odd pages. A large number of my competitors have title tags along the lines of: 'Canon BJ10V Cheap Inkjet Cartridges for Canon BJ-10V Ink Printers' I understand the reasoning behind this but does the variation of keywords compensate for the fact that the title looks spammy (to both humans and Search Engines). What would you do? Keep it clean and concise or stuff the title full of keywords. In the event of the former would you include the company name in each title in the knowledge they would be well under 50 characters without? Thanks for your help.
Technical SEO | | ChrisHolgate1 -

Mobile sitemap needed for responsive website?
I've seen some older 2012 posts that discuss, but nothing recent given the new changes to emphasize mobile. For website that are already tested and verified as mobile responsive, is best practice to develop a mobile-specific sitemap and submit that as well? Or will any mobile crawlers spider the regular sitemap?
Technical SEO | | Addion0 -

Robots.txt Download vs Cache
We made an update to the Robots.txt file this morning after the initial download of the robots.txt file. I then submitted the page through Fetch as Google bot to get the changes in asap. The cache time stamp on the page now shows Sep 27, 2013 15:35:28 GMT. I believe that would put the cache time stamp at about 6 hours ago. However the Blocked URLs tab in Google WMT shows the robots.txt last downloaded at 14 hours ago - and therefore it's showing the old file. This leads me to believe for the Robots.txt the cache date and the download time are independent. Is there anyway to get Google to recognize the new file other than waiting this out??
Technical SEO | | Rich_A0 -

Block Domain in robots.txt
Hi. We had some URLs that were indexed in Google from a www1-subdomain. We have now disabled the URLs (returning a 404 - for other reasons we cannot do a redirect from www1 to www) and blocked via robots.txt. But the amount of indexed pages keeps increasing (for 2 weeks now). Unfortunately, I cannot install Webmaster Tools for this subdomain to tell Google to back off... Any ideas why this could be and whether it's normal? I can send you more domain infos by personal message if you want to have a look at it.
Technical SEO | | zeepartner0 -

Meta-robots Nofollow on logins and admins
In my SEO MOZ reports I am getting over 400 errors as Meta-robots Nofollow. These are all leading to my admin login page which I do not want robots in. Should I put some code on these pages so the robots know this and don't attempt to and I do not get these errors in my reports?
Technical SEO | | Endora0