Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Screaming From occurences and canonicals what does it all mean
-
Bonjourno from Wetherby UK...
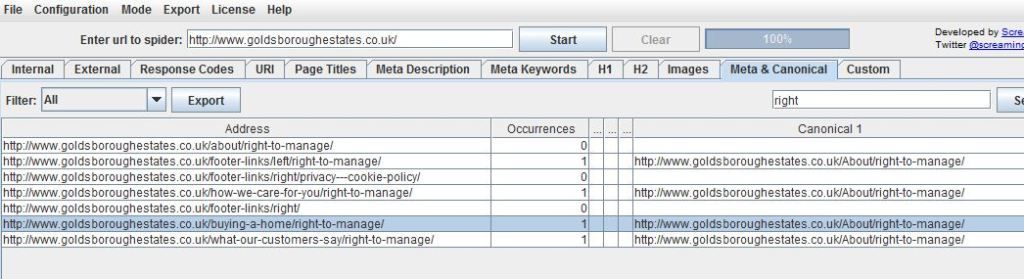
Ive used a package called screamong frog to diagnose canonical errors but can anyone tell me what this means? http://i216.photobucket.com/albums/cc53/zymurgy_bucket/understand-occurances-canonical.jpg
Thanks in advance.
David
-
Thank you for all your replies this was bugging me but the pain of not knowing has vanished like the morning mist as the warming glow of sunshine illumunates truth
")
-
David
Looks like you may have an issue there. The "address" and "canonical 1" should match about 99% of the time. Right now you're telling Google to index all those different address pages as a single URL (About/right-to-manage)... something to look at - and the suggestions below are both good as well.
-Dan
-
I agree with what Streamline Metrics said, I just want to add to this by linking you to a great SEOmoz post on canonicalization which may help you clear things up more.
In your case, having 1 rel="canonical" tag per page is what you want, so you should be fine with that, just make sure that the canonical tags (listed under canonical 1 in Screaming Frog) is the actual URL that you want.
Hope this helps
Zach -
It simply means how many canonical tags are found on that specific page. So if you had two rel=canonical tags on a page, it would say 2 occurrences. For more info, check out http://www.screamingfrog.co.uk/seo-spider/user-guide/tabs/
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Duplicate, submitted URL not selected as canonical
Hi all, A number of our pages have dropped out of search rankings. It seems they are being marked as "Duplicate, submitted URL not selected as canonical" However, the page Google is choosing as the canonical is totally different - different headings, titles, metadata, content on the page. We are completely mystified as to why this is happening. If anyone can shed any light, it would be hugely appreciated! Example URL is this one:
Technical SEO | | Eric_S
https://www.vouchedfor.co.uk/IFA-financial-advisor-mortgage/london Which Google seems to think is a duplicate of this: https://www.vouchedfor.co.uk/solicitor/london0 -

Should I use a canonical URL for images uploaded to a blog post in Wordpress?
Hi, I have a wordpress website that has articles/news posts witch contain imagery. I've noticed that in the Media Library, when you upload an image to a blog post it generates a new permalink ...article-name/article-image-01.jpg I have Yoast SEO plugin and have the option to set a canonical URL for this image. Should I point it back to the actual article? Thanks for any helpers with this.
Technical SEO | | Easigrass0 -

How long does it take for canonical tags to work
How long on average does it take for a canonical tag to work? Understand that canonicals are just a suggestion, but after adding a canonical tag and submitting the page via Google fetch, assuming Google follows the canonical, would you expect it to work after a day or two or does it take longer? We added canonicals to old PPC landing pages that are ranking organically, though our new landing pages (which we want to rank organically) are not identical and have a bit more content/features. They are similar though. Canonicals were added to the old pages (pointing to new pages) and requested indexing via search console. Old pages are still ranking and new pages not so much. FYI we are unable to 301 old PPC pages due to other non negotiable reasons unfortunately. Thanks.
Technical SEO | | SoulSurfer80 -

Removing a canonical tag from Pagination pages
Hello, Currently on our site we have the rel=prev/next markup for pagination along with a self pointing canonical via the Yoast Plugin. However, on page 2 of our paginated series, (there's only 2 pages currently), the canonical points to page one, rather than page 2. My understanding is that if you use a canonical on paginated pages it should point to a viewall page as opposed to page one. I also believe that you don't need to use both a canonical and the rel=prev/next markup, one or the other will do. As we use the markup I wanted to get rid of the canonical, would this be correct? For those who use the Yoast Plugin have you managed to get that to work? Thanks!
Technical SEO | | jessicarcf0 -

Canonical homepage link uses trailing slash while default homepage uses no trailing slash, will this be an issue?
Hello, 1st off, let me explain my client in this case uses BigCommerce, and I don't have access to the backend like most other situations. So I have to rely on BG to handle certain issues. I'm curious if there is much of a difference using domain.com/ as the canonical url while BG currently is redirecting our domain to domain.com. I've been using domain.com/ consistently for the last 6 months, and since we switches stores on Friday, this issue has popped up and has me a bit worried that we'll loose somehow via link juice or overall indexing since this could confuse crawlers. Now some say that the domain url is fine using / or not, as per - https://moz.com/community/q/trailing-slash-and-rel-canonical But I also wanted to see what you all felt about this. What says you?
Technical SEO | | Deacyde0 -

Rel=canonical on Godaddy Website builder
Hey crew! First off this is a last resort asking this question here. Godaddy has not been able to help so I need my Moz Fam on this one. So common problem My crawl report is showing I have duplicate home pages www.answer2cancer.org and www.answer2cancer.org/home.html I understand this is a common issue with apache webservers which is why the wonderful rel=canonical tag was created! I don't want to go through the hassle of a 301 redirect of course for such a simple issue. Now here's the issue. Godaddy website builder does not make any sense to me. In wordpress I could just go add the tag to the head in the back end. But no such thing exist in godaddy. You have to do this weird drag and drop html block and drag it somewhere on the site and plug in the code. I think putting before the code instead of just putting it in there. So I did that but when I publish and inspect in chrome I cannot see the tag in the head! This is confusing I know. the guy at godaddy didn't stand a chance lol. Anyway much love for any replies!
Technical SEO | | Answer2cancer0 -
Rel=canonical Weebly
My problem is with my website as it says I have duplicate page titles and contents because of a /index.html. It says the duplicate content is due to the fact that my homepage on my website is www.seacandytackle.com but it is also www.seacandytackle.com/index.html because I use weebly. How can I use the tag to fix this? It won't let me do a 301 redirect because it is a home page. How can I fix this? What code would I have to use and which url? Also it says that I have duplicate page content between http://www.seacandytackle.com/index.html and http://www.seacandytackle.comhttp://www.seacandytackle.com but I don't recall having any page that looks like http://www.seacandytackle.com http://www.seacandytackle.com from weebly. How can I fix this issue as well? Thank you for any help. Step by step implementation would be particularly helpful in using the rel= tags to fix these duplicate issues.
Technical SEO | | SeaCandyTackle0 -

301 redirect: canonical or non canonical?
Hi, Newbie alert! I need to set up 301 redirects for changed URLs on a database driven site that is to be redeveloped shortly. The current site uses canonical header tags. The new site will also use canonical tags. Should the 301 redirects map the canonical URL on the old site to the corresponding canonical for the new design . . . or should they map the non canonical database URLs old and new? Given that the purpose of canonicals is to indicate our preferred URL, then my guess is that's what I should use. However, how can I be sure that Google (for example) has indexed the canonical in every case? Thx in anticipation.
Technical SEO | | ztalk1120