Canonical for multi store
-
Hello all,
I need to make sure I am doing this correctly; I have one website and with two stores (content is mostly identical) with the following canonical tags;
UK/EU Store: thespacecollective.com
USA/ROW Store: thespacecollective.com/us/
Am I right in thinking that this is incorrect and that only one site should be referencing with the canonical tag?
ie;
UK/EU Store: thespacecollective.com
USA/ROW Store: thespacecollective.com/us/
(please note the removed /us/ from the end of the URL)
-
Thank you for your help! I thought it was correct, just the Moz team not making it clear that it is a "them" problem, as opposed to a Google problem.
-
This is because Moz hasn't updated their crawling tool to consider hreflang in the equation of reporting "duplicates". They've acknowledged that. They might update it in the future. But for now, you just have to ignore pages being reported as duplicate if you know that they are properly linked by hreflang to distinguish countries or languages.
Self-referencing canonical tags are a best practice, and will give an important correct signal to the search engines, which is more important than cleaning up reported warnings in the Moz crawl.
-
This is what I thought, but the Moz team provided conflicting information because a lot of my URLs are showing as duplicates in MozPro.
This was their response:
After looking into your Campaign, it seems that this issue is happening because of the way some of your canonical tags are pointing. These pages are considered duplicates because their canonical tags point to themselves as canonicals, which basically negates the canonicals themselves. For example, 'https://www.thespacecollective.com/archive' is considered a duplicate of 'https://www.thespacecollective.com/us/archive' because the canonical tags for each page just points back to itself.
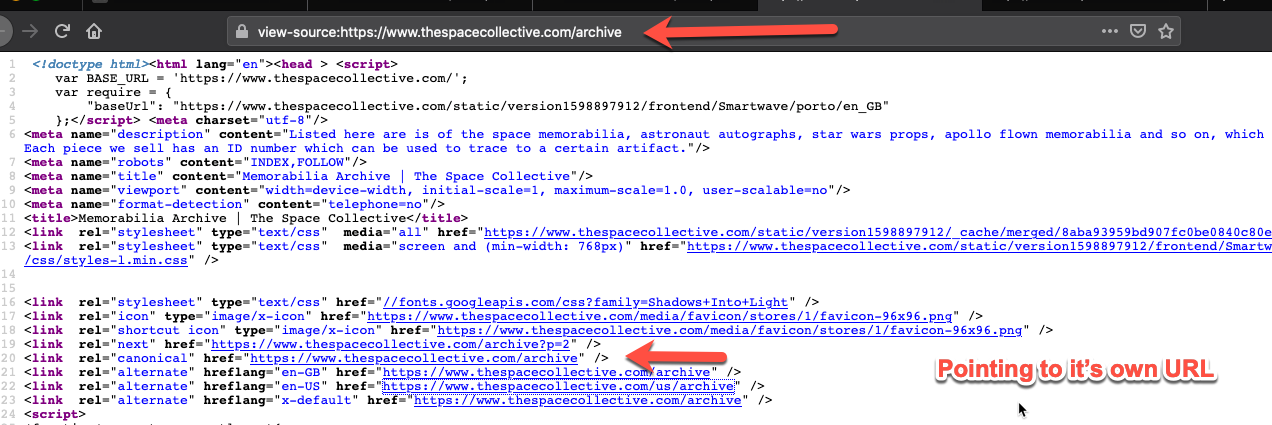
This means that each page is being considered as the most important page with that content, but the content is so similar that they continue to compete against each other for rankings.
Here is how our system interprets duplicate content vs. rel canonical:
Assuming A, B, C, and D are all duplicates,
If A references B as the canonical, then they are not considered duplicates
If A and B both reference C as canonical, A and B are not considered duplicates of each other
If A references C as a canonical, A and B are considered duplicated
If A references C as canonical, B references D, then A and B are considered duplicates
If A references A as canonical and B references B, then A and B are considered duplicatesThe examples you've provided actually fall into the fifth example I've listed above.
-
You should stick with two different canonicals. Self-referencing in each case. And use hreflang tags to link the country-specific variations together.
Pointing both pages to one single canonical is telling the search engine to only index one of those pages.
The self-referencing canonical in this case is simply to deal with variations of the base URL, like in case it has query strings, or http vs. https, or www vs not, etc.
Where you would want to point two different pages to one canonical is when you only want one of those pages to be indexed. If the content is duplicate, the search engine would likely make that choice for you. So, including a canonical lets you give a directive to the search engine, instead of deferring to it on the choice of which.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

How to handle sorting, filtering, and pagination in ecommerce? Canonical is enough?
Hello, after reading various articles and watching several videos I'm still not sure how to handle faceted navigation (sorting/filtering) and pagination on my ecommerce site. Current indexation status: The number of "real" pages (from my sitemap) - 2.000 pages Google Search Console (Valid) - 8.000 pages Google Search Console (Excluded) - 44.000 pages Additional info: Vast majority of those 50k additional pages (44 + 8 - 2) are pages created by sorting, filtering and pagination. Example of how the URL changes while applying filters/sorting: example.com/category --> example.com/category/1/default/1/pricefrom/100 Every additional page is canonicalized properly, yet as you can see 6k is still indexed. When I enter site:example.com/category in Google it returns at least several results (in most of the cases the main page is on the 1st position). In Google Analytics I can see than ~1.5% of Google traffic comes to the sorted/filtered pages. The number of pages indexed daily (from GSC stats) - 3.000 And so I have a few questions: Is it ok to have those additional pages indexed or will the "real" pages rank higher if those additional would not be indexed? If it's better not to have them indexed should I add "noindex" to sorting/filtering links or add eg. Disallow: /default/ in robots.txt? Or perhaps add "noindex, nofollow" to the links? Google would have then 50k pages less to crawl but perhaps it'd somehow impact my rankings in a negative way? As sorting/filtering is not based on URL parameters I can't add it in GSC. Is there another way of doing that for this filtering/sorting url structure? Thanks in advance, Andrew
Intermediate & Advanced SEO | | thpchlk0 -

Should I apply Canonical Links from my Landing Pages to Core Website Pages?
I am working on an SEO project for the website: https://wave.com.au/ There are some core website pages, which we want to target for organic traffic, like this one: https://wave.com.au/doctors/medical-specialties/anaesthetist-jobs/ Then we have basically have another version that is set up as a landing page and used for CPC campaigns. https://wave.com.au/anaesthetists/ Essentially, my question is should I apply canonical links from the landing page versions to the core website pages (especially if I know they are only utilising them for CPC campaigns) so as to push link equity/juice across? Here is the GA data from January 1 - April 30, 2019 (Behavior > Site Content > All Pages😞
Intermediate & Advanced SEO | | Wavelength_International0 -

Index, follow on a paginated page with a different rel=canonical URL
Hello, I have a question about meta robots ="index, follow" and rel=canonical on category page pagination. Should the sorted page be <meta name="robots" content="index,follow"></meta name="robots" content="index,follow"> since the rel="canonical" is pointing to a separate page that is different from the URL? Any thoughts on this topic would be awesome. Thanks. Main Category Page
Intermediate & Advanced SEO | | Choice
https://www.site.com/category/
<meta name="robots" content="index,follow"><link rel="canonical" href="https: www.site.com="" category="" "=""></link rel="canonical" href="https:></meta name="robots" content="index,follow"> Sorted Page
https://www.site.com/category/?p=2&dir=asc&order=name
<meta name="robots" content="index, follow"=""><link rel="canonical" href="https: www.site.com="" category="" ?p="2""></link rel="canonical" href="https:></meta name="robots" content="index,> As you can see, the meta robots is telling Google to index https://www.site.com/category/?p=2&dir=asc&order=name , yet saying the canonical page is https://www.site.com/category/?p=2 .0 -

Is Google ignoring my canonicals?
Hi, We have rel=canonical set up on our ecommerce site but Google is still indexing pages that have rel=canonical. For example, http://www.britishbraces.co.uk/braces/novelty.html?colour=7883&p=3&size=599 http://www.britishbraces.co.uk/braces/novelty.html?p=4&size=599 http://www.britishbraces.co.uk/braces/children.html?colour=7886&mode=list These are all indexed but all have rel=canonical implemented. Can anyone explain why this has happened?
Intermediate & Advanced SEO | | HappyJackJr0 -

Block in robots.txt instead of using canonical?
When I use a canonical tag for pages that are variations of the same page, it basically means that I don't want Google to index this page. But at the same time, spiders will go ahead and crawl the page. Isn't this a waste of my crawl budget? Wouldn't it be better to just disallow the page in robots.txt and let Google focus on crawling the pages that I do want indexed? In other words, why should I ever use rel=canonical as opposed to simply disallowing in robots.txt?
Intermediate & Advanced SEO | | YairSpolter0 -

Cross-Domain Canonical Showing as inbound links?
I run several ecommerce websites, and there is some overlap in the products offered between sites. To solve this duplicate content issue, I use a cross-domain rel canonical so that there is only 1 authoritative page per product, even if it is sold on multiple sites. However, I am noticing that my inbound link profile is massively expanding because Google sees these as inbound links. The top linking domains for my site are all owned by me, even though there are not any actual links between the sites. Has anyone else experienced this?
Intermediate & Advanced SEO | | stevenmusumeche0 -

Cross Domain Rel Canonical for Affiliates?
Hi We use the Cross Domain Rel Canonical for duplicate content between our own websites, but what about affiliates sites who want our XML feed, (descriptions of our products). We don´t mind being credited but would this present a danger for us? Who is controlling the use of that cross domain rel canonical, us in our feed or them? Is there another way around it?
Intermediate & Advanced SEO | | xoffie0 -

To "Rel canon" or not to "Rel canon" that is the question
Looking for some input on a SEO situation that I'm struggling with. I guess you could say it's a usability vs Google situation. The situation is as follows: On a specific shop (lets say it's selling t-shirts). The products are sorted as follows each t-shit have a master and x number of variants (a color). we have a product listing in this listing all the different colors (variants) are shown. When you click one of the t-shirts (eg: blue) you get redirected to the product master, where some code on the page tells the master that it should change the color selectors to the blue color. This information the page gets from a query string in the URL. Now I could let Google index each URL for each color, and sort it out that way. except for the fact that the text doesn't change at all. Only thing that changes is the product image and that is changed with ajax in such a way that Google, most likely, won't notice that fact. ergo producing "duplicate content" problems. Ok! So I could sort this problem with a "rel canon" but then we are in a situation where the only thing that tells Google that we are talking about a blue t-shirt is the link to the master from the product listing. We end up in a situation where the master is the only one getting indexed, not a problem except for when people come from google directly to the product, I have no way of telling what color the costumer is looking for and hence won't know what image to serve her. Now I could tell my client that they have to write a unique text for each varient but with 100 of thousands of variant combinations this is not realistic ir a real good solution. I kinda need a new idea, any input idea or brain wave would be very welcome. 🙂
Intermediate & Advanced SEO | | ReneReinholdt0