Is this correct?
-
I noticed Moz using the following for its homepage
Is this best practice though? The reason I ask is that, I use and I've been reading this page by Google
http://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html
5 common mistakes with rel=canonical
Mistake 2: Absolute URLs mistakenly written as relative URLs
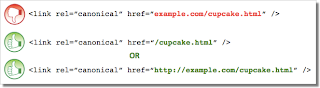
The tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
-
Thanks
-
Ow im sorry, totally mis understood - sorry if i was explaining something you understood.
Moz use
you said they use
/> i presume now you mean the / at the end of the tag.
This is an old school closing tag. HTML elements were traditionally opened and closed in HTML versions before HTML5. Normally this is done obviously with tags such the opener "
" and closer "
". However some elements dont have a seperate closing tag such as "" tags. In older html versions these were closed using the format
Missing these tags didn't used to do much as most browsers rendered the page correctly anyways, but best practice was to include the / to close elements. However with the dawn of HTML5 things changed.
HTML5 doesn't require the closing tag. Elements that used to require one now simply dont. Browsers still understand both versions absolutely fine and its kinda ok to use either. But the most modern and correct practice is to use it without.
Edit:
Racking my brain, i believe the / was added as best practice to assure compatibility with XHTML which was pegged to be the next version of HTML. When XHTML was scrapped in favour of HTML5 it changed. Somebody may correct me on this one though
")
-
Thanks, I realise the usage should be a correct relative URL or a correctly formed absolute URL. In Moz's case, they used a correctly formed absolute URL.
My question is more around...why not use "/"?
Cyto
-
Looks fine to me, i think you misunderstand Mistake 2
They are using an absolute URL
If they did the "mistake 2" their canonical tag would look like
You canonical tags should always be absolute for good practice
is correct
or any variant of this would be wrong

Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-
Is this the correct way of using rel canonical, next and prev for paginated content?
Hello Moz fellows, a while ago (3-4 years ago) we setup our e-commerce website category pages to apply what Google suggested to correctly handle pagination. We added rel "canonicals", rel "next" and "prev" as follows: On page 1: On page 2: On page 3: And so on, until the last page is reached: Do you think everything we have been doing is correct? I have doubts on the way we have handled the canonical tag, so, any help to confirm that is very appreciated! Thank you in advance to everyone.
Intermediate & Advanced SEO | | fablau0 -

Homepage meta title not indexing correctly on google
Hello everyone! We're having a spot of trouble with our website www.whichledlight.com The meta title is coming up wrong on google. In Google it currently reads out
Intermediate & Advanced SEO | | TrueluxGroup
'Which LED Light: LED Bulbs & Lamps Compared'
when it should be
'LED Bulbs & Lamps Compared | Which LED Light' Last snapshot of the page from google was yesterday (5th April 2016) Anyone got any ideas?
Is all the markup correct in the ?0 -

Correct keywords Anchor text for links passing
Hi i have some old pages with more link equity, i m planning to key some bestseller in the main content.. my question is on best use of anchor text, can i use the below for eg: Product name is Chloride Exide Safepower Cs 7-12 12V Sealed Battery so i want to use the key word which is "12v 7ah Battery" in anchor text or buy 12v 7ah battery in Anchor text, will this google consider as spam?? Pls suggest
Intermediate & Advanced SEO | | Rahim1190 -

The correct hreflang for the GB
Hi does anyone know the correct hreflang for the UK Google webmaster error: International Targeting | Language > 'en-GB' - no return tags (sitemaps)Sitemap provided URLs and alternate URLs in 'en-GB' that do not have return tags.Thanks you all
Intermediate & Advanced SEO | | Taiger0 -

Have I set up my structured data correctly, the testing tool suggests not?
Hi, I've recently marked up some Events for a client in hope that they'll appear as rich snippets in ther SERPS. I have access to their Google Search Console so used the Data Highlighter facility to mark them up, rather than the Raven plugin available for WordPress sites like this. I completed this on 10th July and the snippets are yet to appear - I understand that this can take time and there are no guarantees - but as a novice it would be reassuring if someone can advise that I have done this correctly. We did incidentally resubmit a sitemap after completing this task, but I'm not sure if that makes any difference. I've read that it's the structured data testing tool that I need to use to test my markup, but when I input the urls below, the tool doesn't tell me a lot, which either suggests I've marked it up incorrectly, or don't know how to read it! http://www.ad-esse.com/events/19th-august-2015-reducing-costs-changing-culture-improving-services/
Intermediate & Advanced SEO | | nathangdavidson
http://www.ad-esse.com/events/160915-reducing-costs-changing-culture-improving-services-london/
http://www.ad-esse.com/events/151015-reducing-costs-changing-culture-improving-services-london/ Any guidance welcomed! Many thanks,
Nathan0 -

Hreflang doubt use correctly
Hello,I have a question, I want to know which option is best for implementing a multi languages. We have a client whose website will have English and Spanish languages, both languages have the same content but English we focus on the US and UK, and Spanish only for the country Spain, the question arises what is the correct nomenclature we use or would it be the best value.**Option 1:****Option 2:**Or any of the two options is correct What would be the correct ?. Another question, if a German user is in Spain, and do a search on (Google Spain), what will be the best option that should be implemented, / is-de / or single / de /, which one will position before ( provided that the statement I is correct). A greeting and thanks.
Intermediate & Advanced SEO | | omar-moscat0 -

Correct Internal Linking Flow / Keyword Cannibalization
Hi, Would like some advice re our internal linking structure and possible keyword self cannibalization on our ecommerce site.. Will try and give you an overview. Imagine this page structure: Site
Intermediate & Advanced SEO | | bjs2010
Brand 1
Brand 2
Brand 2 Shoes
Products
Brand 2 Sweaters Then say in Brand 2 Shoes page we have the shoes, e.g., the products labeled as Brand 2 Shoes "Name of Model"
Brand 2 Shoes "Name of Model" Now, what I'm worried about is that if I do a search for "Brand 2 Shoes" it should bring up my landing page right? But it doesn't, it brings up some of the products instead... I'm worried that we may be self cannibalizing some of the keywords - and thinking of changing the product page to be "Brand Name of Model Shoes" or "Name of Model Shoes by Brand" Any ideas or comments appreciated! Thanks all0 -

Site Explorer, Social Media Count. Am I linking my social media correctly?
How do I correctly link my social media pages? I have link going from my Twitter, Facebook and Google + to my website. But a quick Open site explorer check says that I have, 0 Facebook Friends, 0 Twitter followers and 0 Google + Followers. Where as in relaity, I have 100 - 1000 follwers on each. Infact, the hyperlink from my Twitter Profile section doesn't appear as a no follow link atall on an OSE check of my website. Am I linking social media wrong?
Intermediate & Advanced SEO | | Paul_Tovey0