Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
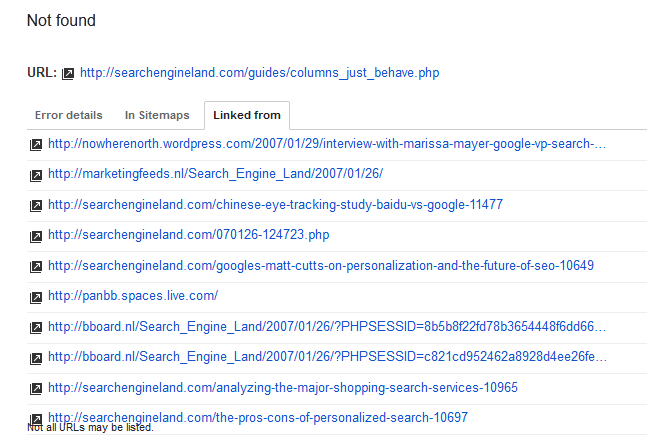
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Moz Crawled My Site. Now What?
Hey everyone! So Moz crawled my site and I passed it over to my dev team who's curious about what they should prioritize. Curious what everyone's thoughts are. Here are the issue types: Duplicate Content - Missing Title - Duplicate Title Tag - Redirect Chain - Title too long - Description too short - Missing Description - Missing h1 - Thin Content - URL Too Long - Has meta noindex Would love any assistance! Thank you!
Technical SEO | | inksoft_mm0 -

Site Crawl -> Duplicate Page Content -> Same pages showing up with duplicates that are not
These, for example: | https://im.tapclicks.com/signup.php/?utm_campaign=july15&utm_medium=organic&utm_source=blog | 1 | 2 | 29 | 2 | 200 |
Technical SEO | | writezach
| https://im.tapclicks.com/signup.php?_ga=1.145821812.1573134750.1440742418 | 1 | 1 | 25 | 2 | 200 |
| https://im.tapclicks.com/signup.php?utm_source=tapclicks&utm_medium=blog&utm_campaign=brightpod-article | 1 | 119 | 40 | 4 | 200 |
| https://im.tapclicks.com/signup.php?utm_source=tapclicks&utm_medium=marketplace&utm_campaign=homepage | 1 | 119 | 40 | 4 | 200 |
| https://im.tapclicks.com/signup.php?utm_source=blog&utm_campaign=first-3-must-watch-videos | 1 | 119 | 40 | 4 | 200 |
| https://im.tapclicks.com/signup.php?_ga=1.159789566.2132270851.1418408142 | 1 | 5 | 31 | 2 | 200 |
| https://im.tapclicks.com/signup.php/?utm_source=vocus&utm_medium=PR&utm_campaign=52release | Any suggestions/directions for fixing or should I just disregard this "High Priority" moz issue? Thank you!0 -

Google crawling but not indexing for no apparent reason
Client's site went secure about two months ago and chose root domain as rel canonical (so site redirects to https://rootdomain.com (no "www"). Client is seeing the site recognized and indexed by Google about every 3-5 days and then not indexed until they request a "Fetch". They've been going through this annoying process for about 3 weeks now. Not sure if it's a server issue or a domain issue. They've done work to enhance .htaccess (i.e., the redirects) and robots.txt. If you've encountered this issue and have a recommendation or have a tech site or person resource to recommend, please let me know. Google search engine results are respectable. One option would be to do nothing but then would SERPs start to fall without requesting a new Fetch? Thanks in advance, Alan
Technical SEO | | alankoen1230 -

First Crawl Report
Just joined SEOMoz today and am slightly overwhelmed, but excited about learning loads from it. I've just received my Crawl Report and there is a
Technical SEO | | iainmoran
404 : UserPreemptionError:
http://www.iainmoran.com/comments/feed/ This is a WordPress site and I've no idea what the best course of action to take. I've done some searching on Google and a couple of sites suggest removing that url from within the robots.txt file. I'm using the Yoast Plugin which apparently creates a robots.txt file, but I can't see any way to edit it. Is there another solution for resolving the 404 error? Many thanks, Iain.0 -

Fixing Crawl Errors
Hi! I moved my Wordpress blog back in August, and lost much of my site traffic. I recently found over 1000 crawl errors in Webmaster Tools because some of my redirects weren't transferred, so we are working on fixing the errors and letting Google know. I'm wondering how long I should expect for Google to recognize that the errors have been fixed and for the traffic to start returning? Thanks! Jodi - momsfavoritestuff.com
Technical SEO | | JodiFTM0 -

Moz Crawl Reporting Duplicate content on "template" styled pages
We have a lot of detail pages on our site that reference specific scholarships. Each page has a different Title and Description. They also have unique information all regarding the same data points. The pages are displayed in a similar structure to the user so the data is easy to read. My problem is a lot of these pages are being reported as duplicate content when they certainly are not. Most of them are reported as duplicates when they have the same sponsor. They may have the same contact information listed. These two are being reported as duplicate of each other. They share some data but they are definitely different scholarships. http://www.collegexpress.com/scholarships/adelaide-mcclelland-garden-club-scholarship/9254/ http://www.collegexpress.com/scholarships/mary-wannamaker-witt-and-lee-hampton-witt-memorial-scholarship/10785/ Would it help to add a Canonical for each page to themselves? Any other suggestions would be great. Thanks
Technical SEO | | GeorgeLaRochelle0 -

Website Grader Report - Permanent Redirect Not Found
Have you ever checked HubSpot's website grader at www.websitegrader.com? I usually notice that the tool gives an error namely "Permanent Redirect Not Found" with below explanation: "Search engines may think www.example.com and example.com are two different sites.You should set up a permanent redirect (technically called a "301 redirect") between these sites. Once you do that, you will get full search engine credit for your work on these sites. :(Website Grader) Can we trust this tool?
Technical SEO | | merkal20050 -

Issue with 'Crawl Errors' in Webmaster Tools
Have an issue with a large number of 'Not Found' webpages being listed in Webmaster Tools. In the 'Detected' column, the dates are recent (May 1st - 15th). However, looking clicking into the 'Linked From' column, all of the link sources are old, many from 2009-10. Furthermore, I have checked a large number of the source pages to double check that the links don't still exist, and they don't as I expected. Firstly, I am concerned that Google thinks there is a vast number of broken links on this site when in fact there is not. Secondly, why if the errors do not actually exist (and never actually have) do they remain listed in Webmaster Tools, which claims they were found again this month?! Thirdly, what's the best and quickest way of getting rid of these errors? Google advises that using the 'URL Removal Tool' will only remove the pages from the Google index, NOT from the crawl errors. The info is that if they keep getting 404 returns, it will automatically get removed. Well I don't know how many times they need to get that 404 in order to get rid of a URL and link that haven't existed for 18-24 months?!! Thanks.
Technical SEO | | RiceMedia0