After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Unsolved Crawler was not able to access the robots.txt
-
I'm trying to setup a campaign for jessicamoraninteriors.com and I keep getting messages that Moz can't crawl the site because it can't access the robots.txt. Not sure why, other crawlers don't seem to have a problem and I can access the robots.txt file from my browser. For some additional info, it's a SquareSpace site and my DNS is handled through Cloudflare. Here's the contents of my robots.txt file:
# Squarespace Robots Txt User-agent: GPTBot User-agent: ChatGPT-User User-agent: CCBot User-agent: anthropic-ai User-agent: Google-Extended User-agent: FacebookBot User-agent: Claude-Web User-agent: cohere-ai User-agent: PerplexityBot User-agent: Applebot-Extended User-agent: AdsBot-Google User-agent: AdsBot-Google-Mobile User-agent: AdsBot-Google-Mobile-Apps User-agent: * Disallow: /config Disallow: /search Disallow: /account$ Disallow: /account/ Disallow: /commerce/digital-download/ Disallow: /api/ Allow: /api/ui-extensions/ Disallow: /static/ Disallow:/*?author=* Disallow:/*&author=* Disallow:/*?tag=* Disallow:/*&tag=* Disallow:/*?month=* Disallow:/*&month=* Disallow:/*?view=* Disallow:/*&view=* Disallow:/*?format=json Disallow:/*&format=json Disallow:/*?format=page-context Disallow:/*&format=page-context Disallow:/*?format=main-content Disallow:/*&format=main-content Disallow:/*?format=json-pretty Disallow:/*&format=json-pretty Disallow:/*?format=ical Disallow:/*&format=ical Disallow:/*?reversePaginate=* Disallow:/*&reversePaginate=*Any ideas?
-
Hi there,
If a crawler cannot access your robots.txt file, it might be due to server issues or incorrect file permissions. Ensure the robots.txt file exists on your server and check for any typos in the file name or path. Also, confirm that your server returns a 200 status code for the robots.txt file. If the server is incorrectly configured to return a 403 or 404 error, crawlers will be unable to access it.
-
Hi andrewrench,
If a crawler cannot access your robots.txt file, it might be due to server issues or incorrect file permissions. Ensure the robots.txt file exists on your server and check for any typos in the file name or path. Also, confirm that your server returns a 200 status code for the robots.txt file. If the server is incorrectly configured to return a 403 or 404 error, crawlers will be unable to access it.
-
When a crawler is unable to access the robots.txt file of a website, it typically means that the file is either missing, restricted, or inaccessible due to server issues. The robots.txt file provides directives to web crawlers about which parts of a website can or cannot be accessed and indexed. Here are some possible reasons and solutions:
Possible Reasons:
File Does Not Exist: The robots.txt file might not be present on the server.
Permission Issues: The file could have restricted permissions that prevent it from being accessed by the crawler.
Server Errors: Temporary server issues, such as a 403 Forbidden error, could block the crawler from accessing the file.
Incorrect URL: The crawler might be trying to access the robots.txt file using the wrong URL or path.
Blocked by Firewall: The server's firewall might be configured to block certain crawlers or user agents.
Solutions:
Create or Restore the robots.txt File: Ensure that the robots.txt file exists in the root directory of your website (e.g., https://www.example.com/robots.txt).
Check File Permissions: Make sure the file has appropriate read permissions (typically 644).
Review Server Logs: Check your server logs to identify any issues or errors related to the file's access.
Verify URL: Ensure that the crawler is using the correct URL to access the file.
Firewall Configuration: Review your firewall settings to allow access to the robots.txt file for all legitimate crawlers.
Additional Steps:
Test with Google Search Console: Use the "Robots.txt Tester" tool in Google Search Console to identify any issues.
Check for Manual Blocking: Ensure that you haven't accidentally blocked access to the robots.txt file in your server's configuration or with specific rules in the file itself.
By addressing these issues, you can ensure that crawlers can access your robots.txt file and follow the directives you've set for your website's content. -
Hello,
If a crawler cannot access your robots.txt file, this could create issues in how your site is indexed. Here are some steps to identify and address this problem:
Check File Permissions:
Make sure your robots.txt file is accessible. Set its permissions (typically 644) so it's readable by everyone; this can be accomplished using either your hosting control panel or FTP client.
Verify File Location:
Your robots.txt file should be located in the root directory of your website - for example if example.com was the domain, this would mean accessing it at example.com/robots.txt
Make sure that your server is configured appropriately to serve the robots.txt file by reviewing its.htaccess or server settings to ensure there are no rules blocking access. Test with Google
Search Console:
Google Search Console makes it easy to test your robots.txt file using their "Robots.Txt Tester" under "Crawl." Simply visit this section of their platform, select your file, and see if Google can access it or if there are any errors with it.
Review Content:
Check that the content of your robots.txt file is accurate. Change content according to your requirements.
Check for Syntax Errors:
Even small syntax errors can have serious repercussions. Double-check for typos or formatting issues before publishing content to your site.
-
If a crawler cannot access the robots.txt file, it may be due to server misconfigurations, incorrect file permissions, or the file being missing. The robots.txt file is essential for guiding web crawlers on which pages they are allowed to access.
-
Did you check google.com/webmasters/tools/robots-testing-tool ? all good here ?
-
Hi Andrew,
It sounds like you're running into an issue with Moz being unable to access your robots.txt file, even though other crawlers and your browser can access it. Since your site is on SquareSpace and DNS is managed through Cloudflare, there could be a couple of things to consider:
Cloudflare Settings: Sometimes, Cloudflare's security settings (like firewall rules or bot management) can block certain bots, including Moz's crawler. You might want to check your Cloudflare settings to ensure that Moz’s IP addresses or user agents aren’t being inadvertently blocked.
Robots.txt Caching: Cloudflare may cache your robots.txt file. Try purging the cache for that file specifically to ensure the most up-to-date version is being served. This can sometimes resolve issues where different services see different versions of the file.
SquareSpace Configuration: Double-check if SquareSpace has any additional settings or restrictions that might affect how external crawlers, like Moz, interact with your site. Since SquareSpace handles a lot of things on the backend, their support might be able to provide more insight.
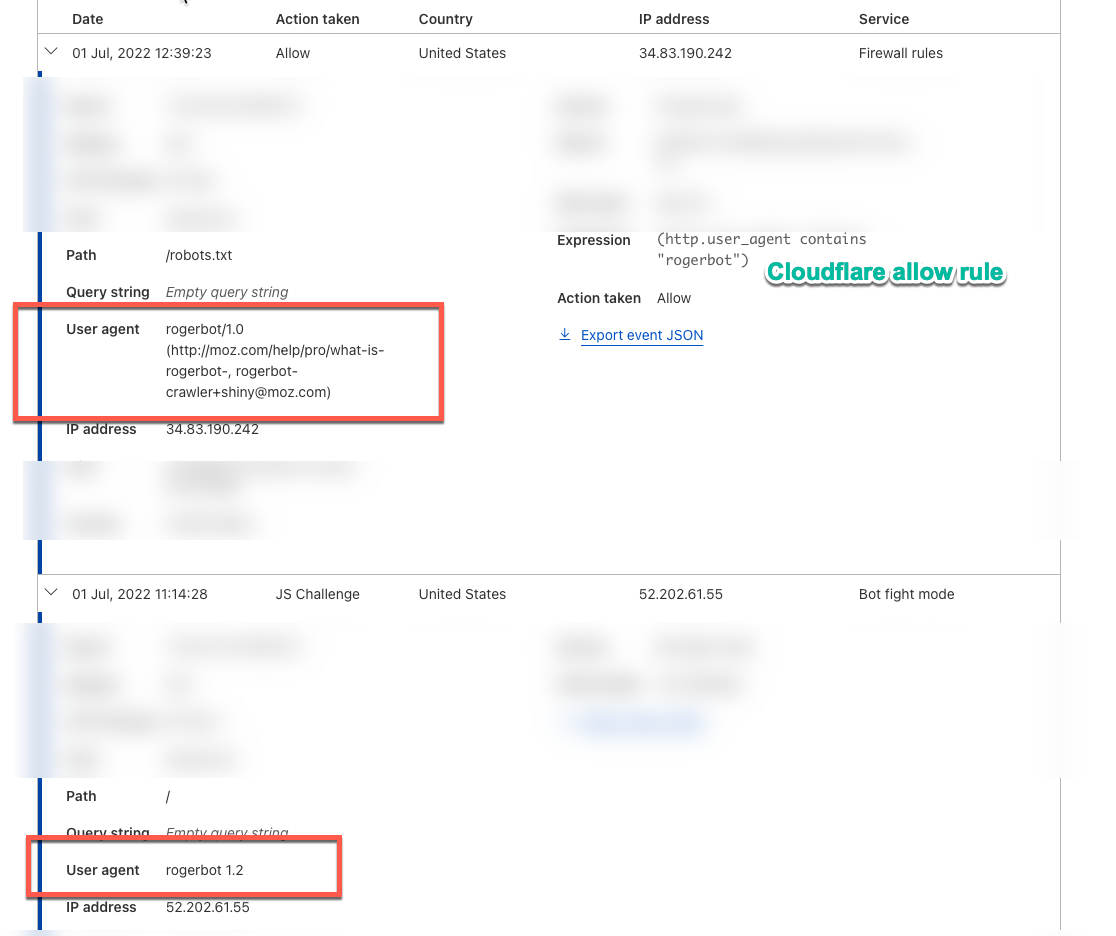
Allow Moz in robots.txt: If Moz’s specific user agent isn't listed in your robots.txt file, you could try explicitly allowing it by adding the following to the top of your file:
User-agent: rogerbot Allow: /If the issue persists after checking these, reaching out to Moz support with specifics about your setup might help you get more targeted assistance.
-
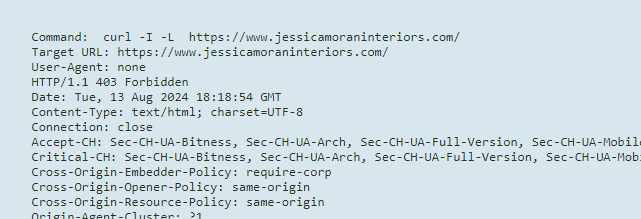
Hi @andrewrench!
Aneta from the help team here. I had a look at this for you and I can see that we are getting a 403 forbidden error when pinging your site. I would recommend looking into this and if you need any further help please don't hesitate to reach out to help@moz.com.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-