After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
How to stop Google crawling after 301 redirect?
-
I have removed all pages from my old website and set 301 redirect to new website. But, I have verified old website with Google webmaster tools' HTML verification file which enable me to track all data and existence of pages in Google search for my old website. I was assumed that, Google will stop crawling and DE-indexed all pages after 301 redirect. Because, I have set 301 redirect before 3 months.
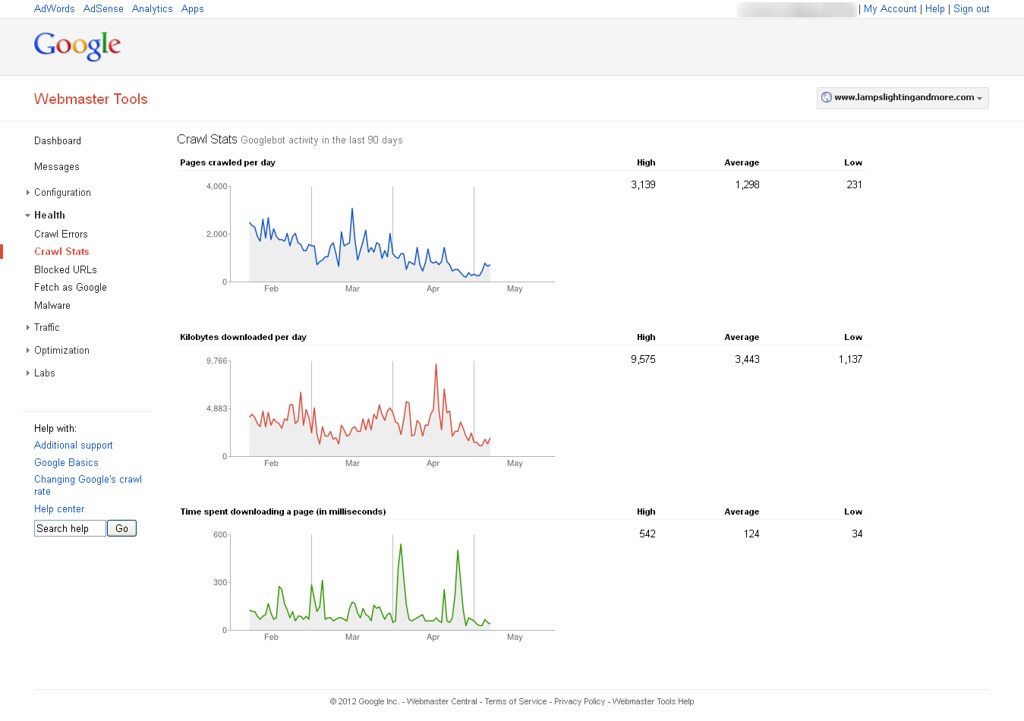
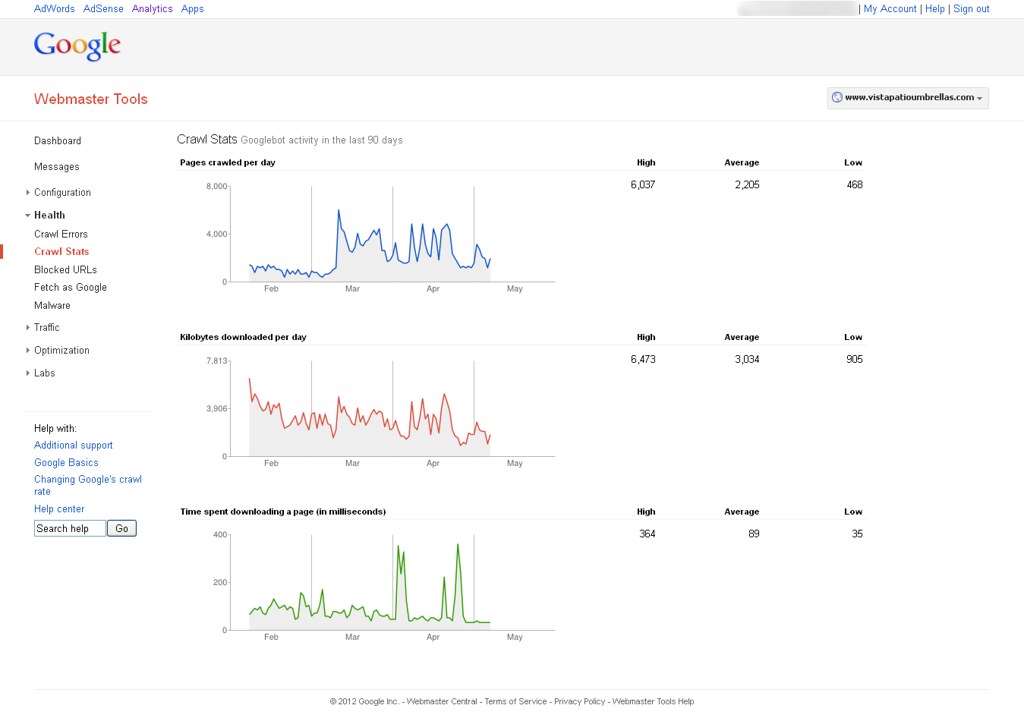
Now, I'm able to see Google bot activity on my website with help of Google webmaster tools. You can find out attachment to know more about it. How can it possible & How Google can crawl removed pages?
You can see following image to know more about it.
&
-
Google is most likely following links on other sites pointing to your old site and then 301'ing to the new site so you're seeing activity in WMT
looking here is still see two pages in the index:
you can go in and remove the site in WMT using the remove URL tool and see if that stops activity in that old WMT account. Crawling or not crawling, reporting or not reporting, there is not an issue here though - the 301's appear to be properly set up.
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-