Broken Links from Open Site Explorer
-
I am trying to find broken internal links within my site. I found a page that was non-existent but had a bunch of internal links pointing to that page, so I ran an Open Site Explorer report for that URL, but it's limited to 25 URLs.
Is there a way to get a report of all of my internal pages that link to this invalid URL? I tried using the link: search modifier in Google, but that shows no responses.
-
Whew! Big thread.
Sometimes, when you can't find all the broken links to a page, it's easier simply to 301 redirect the page to a destination of your choice. This helps preserve link equity, even for those broken links you can't find on large sites. (and external links, as well)
Not sure if this would help in your situation, but I hope you're getting things sorted out!
-
Jesse,
That's where I started my search, but GWMT wasn't showing this link. I can only presume that because it isn't coming back a 404 (it is showing that "We're Sorry" message instead) that they're considering that message to be content.
Thanks!
-
Lynn, that was a BIG help. I had been running that report, but was restricted to 25 responses. When I saw your suggestion to filter for only internal links, I was able to see all 127.
Big props. Thanks!
-
One more thing to add - GWMT should report all 404 links and their location/referrer.
-
oops! i did not know this. Thanks Irving.
-
Use the word FREE with an asterisk because sreaming frog is now limiting the free version to 500 pages. Xenu is better, even brokenlinkcheck.com lets you spider 3000 pages.
500 pages makes the tool practically worthless for any site of decent size.
-
Indeed if it is not showing a 404, that makes things a bit difficult!
You could try another way, use OSE!
Use the exact page, filter for only internal links, boom 127 pages that link to it. There might be more, but this should get you going!
-
Jesse:
I appreciate your feedback, but am surprised that the ScreamingFrog report found no 404s. SEOmoz found 15 in Roger's last crawl, but those aren't the ones that I'm currently trying to solve.
The problem page is actually showing up as duplicate content, which is kinda screwy. When visiting the page, our normal 404 error doesn't appear (which our developers are still trying to figure out), but instead, an error message appears:
http://www.gallerydirect.com/about-us/media-birchwood
If this were a normal 404 page, we'd probably be able to find the links faster.
-
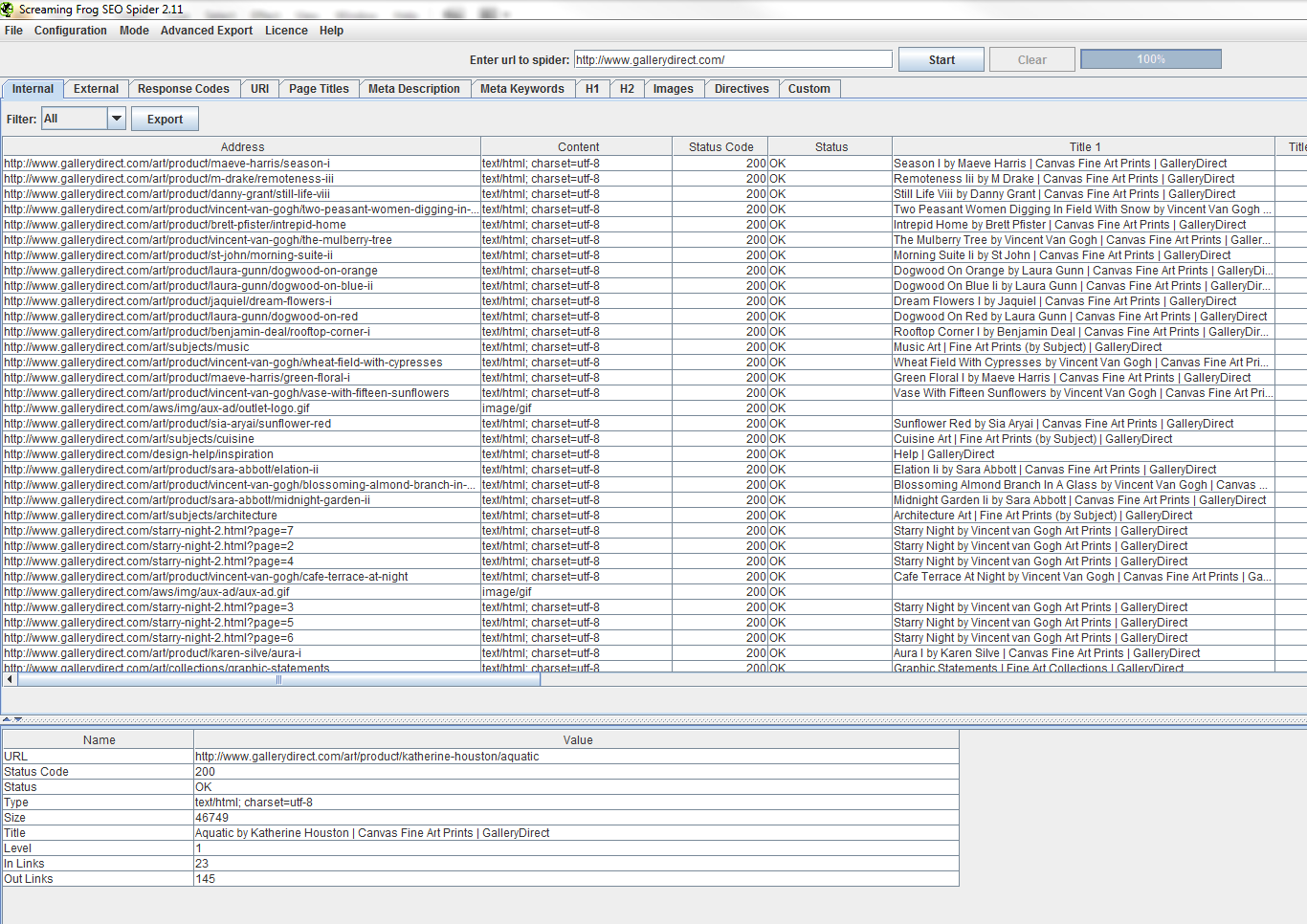
I got tired of the confusion and went ahead and proved it. Not sure if this is the site you wanted results for, but I used the site linked in your profile (www.gallerydirect.com)
took me about 90 seconds and I had a full list... no 404s though
anyway here's a screenshot to prove it:
http://gyazo.com/67b5763e30722a334f3970643798ca62.png
so what's the problem? want me to crawl the fbi site next?
-
I understand. Thing is, there is a way and the spider doesn't affect anything. Like I said, I have screaming frog installed on my computer and I could run a report for your website right now and you or your IT department would never know it happened.. I just don't understand the part where the software doesn't work for you but to each their own i suppose.
-
Jesse:
That movie was creepy, but John Goodman was awesome in it.
I started this thread because I was frustrated that OSE restricts my results to 25 links, and I simply wanted to find the rest for that particular URL. I was assuming that there was either:
a. A method for getting the rest of the links that Roger found
b. Another way of pulling these reports from someone who already spiders them (since I can't get any using the link:[URL] in Google and Webmaster Tools isn't showing them).
Thanks to all for your suggestions.
-
run the spider based app from outside their "precious network" then. hell, i could run it right now for you from my computer at work if I wanted. Use your laptop or home computer. It's a simple spider you don't have to be within any network to run it. You could run one for CNN.com if you'd like as well...
-
How else do you expect to trace these broken links without using a "spider?"
Obviously it's the solution. And the programs take up all of like 8 megs... so what's the problem/concern?
I second the screaming frog solution. It will tell you exactly what you need to know and has ZERO risk involved (or whatever it is that's hanging you up). The bazooka comparison is ridiculous, because a bazooka destroys your house. Do you really think a spider crawl will affect your website?
Spiders crawl your site and report findings. This happens often whether you download a simple piece of software or not. What do you think OSE is? Or Google?
I guess what we're saying is if you don't like the answer, then so be it. But that's the answer.
PS - OSE uses a spider to crawl your site...
PPS - Do you suffer from arachnophobia? That movie was friggin awesome now I want to watch old Jeff Daniels films.
PPSS - Do you guys remember John Goodman being in that movie? Wow the late 80s early 90s were really somethin' special.
-
John, I certainly see your point, but our IT guys would not take too kindly to me running a spider-based app from inside their precious network, which is why I was looking for a less intrusive solution.
I'm planning on a campaign to revive "flummoxed" to the everyday lexicon next.
-
Hi Darin,
Both these softwares are made for exactly this kind of job and they are not huge system killing programs or anything. Seriously I use one or both almost every day. I suggest downloading them and seeing how you go, I think you will be happy enough with the results.
-
The way I see it, its much like you missing the last flight home, and you have a choice of getting the bus, that means you might take a little longer, or of course you can wait for the next flight ,which happens to be tomorrow evening, the bus will get you home that night.
I get the bus each and every time, I get home, later than expected I grant you, but I get home a lot quicker than waiting for the plane tomorrow.
Bewildered, I didn't realise it had fallen out of the diction, its a common word (I think) in Ireland, oh and I am still young (ish)
")
-
John:
Bewildered. There's a good word that I'm happy to see someone is keeping it alive for the younger generations.
I'm not ungrateful for your suggestions, but both involve downloading and installing a spider, which seems like overkill, much like using a bazooka to kill a housefly.
-
I am bewildered by this, I have told you one, Lynn has told you another piece of free software that will do this for you.
Anyway, good luck with however you resolve our issues
-
Lynn, part of the problem is definitely template-based, and one of our developers is working on that fix now. However, I also found a number of non-template created links to this page simply due to UBD error (an old Cobol programming term meaning User Brain Dead).
I need to find all of the non-template based, UBD links that may have been created and fix them.
-
Xenu will also do a similar job and doesn't have a limit which I recall the free version of screaming frog has: http://home.snafu.de/tilman/xenulink.html
If you have loads of links to this missing page it sounds like you maybe have a template problem with the links getting inserted on every or lots of pages. In that case if you find the point in the template you will have fixed them all at once (if indeed it is like this).
-
Darin
Its a stand alone piece of software you run, it crawls your website and finds out broken inbound, outbound or internal links, tells you them ,you go and fix them

Enter your URL, be it a page or directory, run it, it will give you all bad links. And it wont limit you to 25.
You don't need to implement anything ... run the software once, use it, and well bin it afterwards if you wish
But by all means, you can do as you suggest with SE ...
Regards
John
-
John,
While I could look at implementing such a spider to run the check sitewide on a regular basis, I am not looking to go that far at the moment. For right now, I'm only looking for all of the pages on my site that link to a single incorrect URL. I would have to think that there's a solution available for such a limited search.
If I have to, I suppose I can fix the 25 that Open Site Explorer displays, wait a few days for the crawler to run again, then run the report again, fix the next 25, then so on and so on, but that's going to spread the fix out potentially over a number of weeks.
-
Free tool, non SEO Moz related
http://www.screamingfrog.co.uk/seo-spider/ , run that, will find all broken links, where they are coming from etc etc
Hope I aint braking any rules posting it
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Can anyone please explain the real difference between backlinks, 301 links, and redirect links?which one is better to rank a website? i am looking for the help for one of my website
Can anyone please explain the real difference between backlinks, 301 links, and redirect links? which one is better to rank a website? I am looking for help for one of my website vacuum cleaners
Intermediate & Advanced SEO | | hshajjajsjsj3880 -

Easiest Way to Balance Links Across Site?
I'm struggling to reach the last few spots for my client's main keyword, hovering around mid-page on the first SERP. I have continuously built more links to this page but have not seen a correlation in movement, until I finally realised that I have too high a ratio of links pointing to the home page relative to those pointing to other pages on the site, which doesn't look natural (stupidly, for the last year we have mainly only been trying to rank the home page). I already have links on most UK directories - since the links I need are really just safe links (they don't need to have power), can anyone suggest the best/cheapest source of link-building that I could use to point more links to other pages on the site, to balance the site's overall profile? A press release, perhaps? Thanks in advance!
Intermediate & Advanced SEO | | zakkyg0 -

My wordpress site generating bad links
Hello Everyone, I have wordpress site Which is from last 20 days generating links like For Example http://www.domainname.com/game/965/wiki/キャラクター図鑑_レアリティ(★★★)_【ID:675】ワッツ・ステップニー htttp://www.domainname.com/nkpghfu_13356_gvgjq_tfjhnkt_jsj_296_82566_673_567_245 This is screenshot of webmaster tools http://prnt.sc/ccwh0e can please any expert check & Tell How this Link i am getting, Also What are steps i need take for removing this Errors, As it is harming my sites Flow As well As Rankings. Thanx in Advance
Intermediate & Advanced SEO | | innovativekrishna10 -

Outbound link to PDF vs outbound link to page
If you're trying to create a site which is an information hub, obviously linking out to authoritative sites is a good idea. However, does linking to a PDF have the same effect? e.g Linking to Google's SEO starter guide PDF, as opposed to linking to a google article on SEO. Thanks!
Intermediate & Advanced SEO | | underscorelive0 -

.GOV Link - same impact on my site's rankings whether link to home or Gov related category?
I own a job site and I am about to get a link from a .GOV. My site has a category called "State Jobs". Should I ask the ".Gov" to link to my homepage or to the state job page and use the anchor text "State Jobs". I understand "State Jobs" page would get a big kick by that being the anchor text and linking to that specific page, but the question I have is this: for my site as a whole (homepage and various categories) would they get around the same "push up" whether the linking is to 1) my homepage with anchor text being my site's name or 2) to the state job specific page and in this case the anchor text would be "State Jobs"? thank you
Intermediate & Advanced SEO | | knielsen0 -

Because Goolge chose this link to my site?
I'm better ranked in Google for that link (http://www.vipgoldrj.com/paginas/ensaios.html) and not in (http://www.vipgoldrj.com/), you know you explain why? In all keywords, except that (luxury escorts in Rio de Janeiro) Sorry my english, I'm from Brazil and I'm using Google translator.
Intermediate & Advanced SEO | | WebMaster0210 -

Relaunching old site - Will it regain former link equity?
We've got an older site with significant link equity. It 301 redirects to our current website, passing all traffic, link value, etc. The 301 redirects have been in place for several years. Since the original redirects were setup, the current website has acquired massive link equity above and beyond the redirects. I am considering removing all the 301 redirects and bringing the old site back to life (same URLs, content, design as before). I would also keep the current website live as is. The goal is to capture more SERP visibility by having 2 website "brands" in the same market. Will the old site regain it's former link equity or will we effectively be starting from scratch? In other words, does Google consider how long 301 redirects have been in place?
Intermediate & Advanced SEO | | Jeff_DomainTools0 -
Multiple sites linking back with pornographic anchor text
I discovered a while ago that we had quite a number of links pointing back to one of our customer's websites. The anchor text of these links contain porn that is extremely bad. These links are originating from forums that seems to link between themselves and then throw my customers web address in there at the same time. Any thoughts on this? I'm seriously worried that this may negatively affect the site.
Intermediate & Advanced SEO | | GeorgeMaven0