Why are Google SERP Sitelinks "Not Working?"
-
Hi,
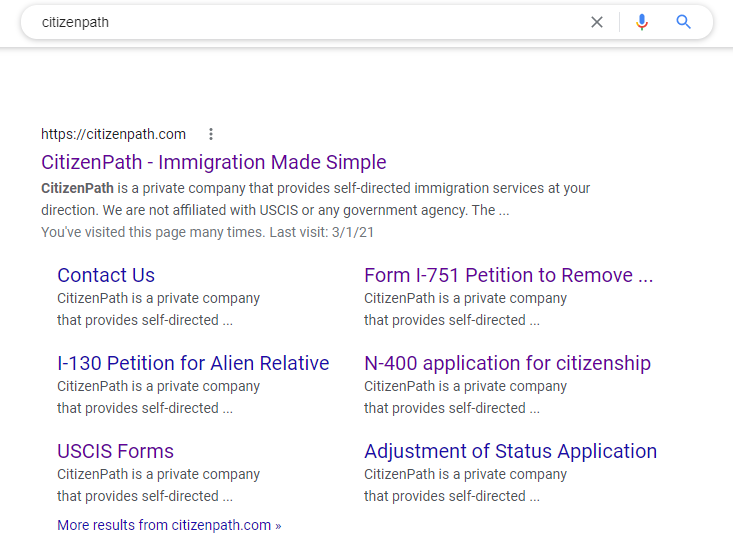
I'm hoping someone can provide some insight. I Google searched "citizenpath" recently and found that all of our our sitelinks have identical text. The text seems to come from the site footer. It isn't using the meta descriptions (we definitely have) or even a Google-dictated snippet from the page. I understand we don't have "control" of this. It's also worth mentioning that if you search a specific page like "contact us citizenpath" you'll get a more appropriate excerpt.
Can you help us understand what is happening? This isn't helpful for Google users or CitizenPath. Did the Google algorithm go awry or is there a technical error on our site? We use up-to-date versions of Wordpress and Yoast SEO. Thanks!
-
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@123russ let me know how it goes.
PS: I'd appreciate upvote if you find my suggestions helpful. -
@terentyev Thank you for taking the time to review this. I'll ask our team to review your suggestions.
-
@123russ I checked your site, and it seems that there is an issue with embedded iframes you are using on your site.
Check out your document outline in W3 validator and tell your developer to fix fatal errors (in your case - multiple body tags).Another thing I would do is to add the texts that you are using in meta descriptions somewhere on the top of the page, behind the H1 title.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

"Moz encountered an error on one or more pages on your site" Error
I have been receiving this error for a while: "Moz encountered an error on one or more pages on your site" It's a Multi-Lingual Wordpress website, the robots.txt is set to allow crawlers on all links and I have followed the same process for other website I've done yet I'm receiving this error for this site.
Technical SEO | | JustinZimri0 -

"Site:" without Homepage, Why?
Hi all, When I put "site:bettingexchange.it" on www.google.it in the SERP it's NOT showed the HOMEPAGE "bettingexchange.it". Google starts with other pages lik "bettingexchange.it/siti/". It's the first time I see something like this, How is it possibile?
Technical SEO | | bettingexchange
How can I reintroduce the homepage?0 -

Rel="canonical"
HI, I have site named www.cufflinksman.com related to Cufflinks. I have also install WordPress in sub domain blog.cufflinksman.com. I am getting issue of duplicate content a site and blog have same categories but content different. Now I would like to rel="canonical" blog categories to site categories. http://www.cufflinksman.com/shop-cufflinks-by-hobbies-interests-movies-superhero-cufflinks.html http://blog.cufflinksman.com/category/superhero-cufflinks-2/ Is possible and also have any problem with Google with this trick?
Technical SEO | | cufflinksman0 -

Best action to take for "error" URLs?
My site has many error URLs that Google webmaster has identified as pages without titles. These are URLs such as: www.site.com/page???1234 For these URLs should I: 1. Add them as duplicate canonicals to the correct page (that is being displayed on the error URLs) 2. Add 301 redirect to the correct URL 3. Block the pages in robots.txt Thanks!
Technical SEO | | theLotter0 -

How many steps for a 301 redirect becomes a "bad thing"
OK, so I am not going to worry now about being a purist with the htaccess file, I can't seem to redirect the old pages without redirect errors (project is an old WordPress site to a redesigned WP site). And the new site has a new domain name; and none of the pages (except the blog posts) are the same. I installed the Simple 301 redirects plugin on old site and it's working (the Redirection plugin looks very promising too, but I got a warning it may not be compatible with the old non-supported theme and older v. of WP). Now my question using one of the redirect examples (and I need to know this for my client, who is an internet marketing consultant so this is going to be very important to them!): Using Redirect Checker, I see that http://creativemindsearchmarketing.com/blog --- 301 redirects to http://www.creativemindsearchmarketing.com/blog --- which then 301 redirects to final permanent location of http//www.cmsearchmarketing.com/blog How is Google going to perceive this 2-step process? And is there any way to get the "non-www-old-address" and also the "www-old-address" to both redirect to final permanent location without going through this 2-stepper? Any help is much appreciated. _Cindy
Technical SEO | | CeCeBar0 -

A rel="canonical" to www.homepage.com/home.aspx Hurts my Rank?
Hello, The CMS that I use makes 3 versions of the homepage:
Technical SEO | | EvolveCreative
www.homepage.com/home.aspx homepage.com homepage.com/default.aspx By default the CMS is set to rel=canonical all versions to the www.homepage.com/home.aspx version. If someone were to link to a website they most likely aren't going to link to www.homepage.com/home.aspx, they'll link to www.homepage.com which makes that link juice flow through the canonical to www.homepage.com/home.aspx right? Why make that extra loop at all? Wouldn't that be splitting the juice? I know 301's loose 1-5 % juice, but not sure about canonical. I assume it works the same way? Thanks! http://yoursiteroot/0 -

Why "title missing or empty" when title tag exists?
Greetings! On Dec 1, 2011 in a SEOMoz campaign, two crawl metrics shot up from zero (Nov 17, Nov 24). "Title missing or empty" was 9,676. "Duplicate page content" was 9,678. Whoa! Content at site has not changed. I checked a sample of web pages and each seems to have a proper TITLE tag. Page content differs as well -- albeit we list electronic part numbers of hard-to-find parts, which look similar. I found a similar post http://www.seomoz.org/q/why-crawl-error-title-missing-or-empty-when-there-is-already-title-and-meta-desciption-in-place . In answer, Sha ran Screaming Frog crawler. I ran Frog crawler on a few hundred pages. Titles were found and hash codes were unique. Hmmm. Site with errors is http://electronics1.usbid.com Small sample of pages with errors: electronics1.usbid.com/catalog_10.html
Technical SEO | | groovykarma
electronics1.usbid.com/catalog_100.html
electronics1.usbid.com/catalog_1000.html I've tried to reproduce errors yet I cannot. What am I missing please? Thanks kindly, Loren0 -

Google dropping pages from SERPS
The website for my London based plumbing company has thousands of specifically tailored pages for the various services we provide to all the areas in London. It equates to approximately 6000 pages in total. When google has all these pages indexed, we tend to get a fair bit of traffic - as they cater pretty well for long tail searches. However, every once in a while Google will drop the vast majority of our indexed pages from SERPs for a few days or weeks at a time - for example at the moment Google is only indexing 613 whereas last week it was back at the normal ~6000. Why does this happen? We of course lose a lot of organic traffic when these pages don't displayed - what are we doing wrong? Website: www.pgs-plumbers.co.uk
Technical SEO | | guy_andrews0