Unsolved Strange "?offset" URL found with content crawl issues
-
I recently recieved a slew of content crawl issues via Moz for URL's that I have never seen before
For example:
Standard URL: https://skilldirector.com/news,
Newly identified URL: https://skilldirector.com/news?offset=1469542207800&category=Competency+Management).Does anyone know where the URL comes from and how to fix it?
-
@meghanpahinui thank you!
-
Hi there! Thanks so much for the post!
I took a look at the links/pages you provided and it seems these URLs are originating from the pagination on your category pages. For example, if I head to https://skilldirector.com/news/category/Competency+Management and then click "Older" at the bottom of the category page, the next page is an offset URL. I was also able to find the ?offset URL in the source code:
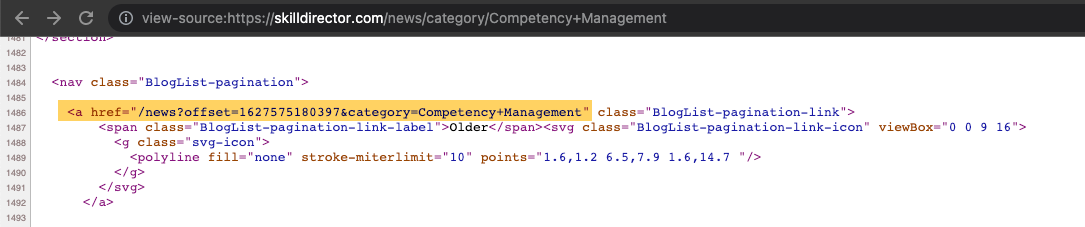
I hope this helps to point you in the right direction!
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Unsolved Crawler was not able to access the robots.txt
I'm trying to setup a campaign for jessicamoraninteriors.com and I keep getting messages that Moz can't crawl the site because it can't access the robots.txt. Not sure why, other crawlers don't seem to have a problem and I can access the robots.txt file from my browser. For some additional info, it's a SquareSpace site and my DNS is handled through Cloudflare. Here's the contents of my robots.txt file: # Squarespace Robots Txt User-agent: GPTBot User-agent: ChatGPT-User User-agent: CCBot User-agent: anthropic-ai User-agent: Google-Extended User-agent: FacebookBot User-agent: Claude-Web User-agent: cohere-ai User-agent: PerplexityBot User-agent: Applebot-Extended User-agent: AdsBot-Google User-agent: AdsBot-Google-Mobile User-agent: AdsBot-Google-Mobile-Apps User-agent: * Disallow: /config Disallow: /search Disallow: /account$ Disallow: /account/ Disallow: /commerce/digital-download/ Disallow: /api/ Allow: /api/ui-extensions/ Disallow: /static/ Disallow:/*?author=* Disallow:/*&author=* Disallow:/*?tag=* Disallow:/*&tag=* Disallow:/*?month=* Disallow:/*&month=* Disallow:/*?view=* Disallow:/*&view=* Disallow:/*?format=json Disallow:/*&format=json Disallow:/*?format=page-context Disallow:/*&format=page-context Disallow:/*?format=main-content Disallow:/*&format=main-content Disallow:/*?format=json-pretty Disallow:/*&format=json-pretty Disallow:/*?format=ical Disallow:/*&format=ical Disallow:/*?reversePaginate=* Disallow:/*&reversePaginate=* Any ideas?
Getting Started | | andrewrench0 -

Unsolved URL dynamic structure issue for new global site where I will redirect multiple well-working sites.
Dear all, We are working on a new platform called [https://www.piktalent.com](link url), were basically we aim to redirect many smaller sites we have with quite a lot of SEO traffic related to internships. Our previous sites are some like www.spain-internship.com, www.europe-internship.com and other similars we have (around 9). Our idea is to smoothly redirect a bit by a bit many of the sites to this new platform which is a custom made site in python and node, much more scalable and willing to develop app, etc etc etc...to become a bigger platform. For the new site, we decided to create 3 areas for the main content: piktalent.com/opportunities (all the vacancies) , piktalent.com/internships and piktalent.com/jobs so we can categorize the different types of pages and things we have and under opportunities we have all the vacancies. The problem comes with the site when we generate the diferent static landings and dynamic searches. We have static landing pages generated like www.piktalent.com/internships/madrid but dynamically it also generates www.piktalent.com/opportunities?search=madrid. Also, most of the searches will generate that type of urls, not following the structure of Domain name / type of vacancy/ city / name of the vacancy following the dynamic search structure. I have been thinking 2 potential solutions for this, either applying canonicals, or adding the suffix in webmasters as non index.... but... What do you think is the right approach for this? I am worried about potential duplicate content and conflicts between static content dynamic one. My CTO insists that the dynamic has to be like that but.... I am not 100% sure. Someone can provide input on this? Is there a way to block the dynamic urls generated? Someone with a similar experience? Regards,
Technical SEO | | Jose_jimenez0 -

Unsolved Performance Metrics crawl error
I am getting an error:
Product Support | | bhsiao 0
Crawl Error for mobile & desktop page crawl - The page returned a 4xx; Lighthouse could not analyze this page.
I have Lighthouse whitelisted, is there any other site I need to whitelist? Anything else I need to do in Cloudflare or Datadome to allow this tool to work?1 -

Unsolved Halkdiki Properties
Hello,
Moz Pro | | TheoVavdinoudis
I have a question about Site Crawl: Content Issues segment. I have an e-shop and moz showing me problem because my urls are too similar and my H1s are the same
<title>Halkdiki Properties
https://halkidikiproperties.com/en/properties?property_category=1com&property_subcategory=&price_min_range=&price_max_range=&municipality=&area=&sea_distance=&bedroom=&hotel_bedroom=&bathroom=&place=properties&pool=&sq_min=&sq_max=&year_default=&fetures=&sort=1&length=12&ids= <title>Halkdiki Properties
https://halkidikiproperties.com/en/properties?property_category=2&property_subcategory=&price_min_range=0&price_max_range=0&municipality=&area=&sea_distance=&bedroom=0&hotel_bedroom=0&bathroom=0&place=properties&pool=0&sq_min=&sq_max=&year_default=&fetures=&sort=1&length=12&ids= Can someone help, is a big problem or I ignore it?? thank you0 -

Block Moz (or any other robot) from crawling pages with specific URLs
Hello! Moz reports that my site has around 380 duplicate page content. Most of them come from dynamic generated URLs that have some specific parameters. I have sorted this out for Google in webmaster tools (the new Google Search Console) by blocking the pages with these parameters. However, Moz is still reporting the same amount of duplicate content pages and, to stop it, I know I must use robots.txt. The trick is that, I don't want to block every page, but just the pages with specific parameters. I want to do this because among these 380 pages there are some other pages with no parameters (or different parameters) that I need to take care of. Basically, I need to clean this list to be able to use the feature properly in the future. I have read through Moz forums and found a few topics related to this, but there is no clear answer on how to block only pages with specific URLs. Therefore, I have done my research and come up with these lines for robots.txt: User-agent: dotbot
Moz Pro | | Blacktie
Disallow: /*numberOfStars=0 User-agent: rogerbot
Disallow: /*numberOfStars=0 My questions: 1. Are the above lines correct and would block Moz (dotbot and rogerbot) from crawling only pages that have numberOfStars=0 parameter in their URLs, leaving other pages intact? 2. Do I need to have an empty line between the two groups? (I mean between "Disallow: /*numberOfStars=0" and "User-agent: rogerbot")? (or does it even matter?) I think this would help many people as there is no clear answer on how to block crawling only pages with specific URLs. Moreover, this should be valid for any robot out there. Thank you for your help!0 -

Is it possible to block Moz from crawling sites?
Hi, is it possible to stop Moz from crawling a site at the server level? Not that I am looking to do this or anything, but here's why I'm asking. I have been crawling a site that is managed (currently by 2 parties), and I noticed that this week pages crawled went from 80 (last week) to 1 page!! I know, what? See my image attached... and the issues all went to zero "0"....! So is it possible that someone can't prevent Moz from crawling the site at the server level? I checked the robots.txt file on the site, but nothing there. I'm curious. dYNUwjd.jpg
Moz Pro | | co.mc0 -

SEOMOZ Crawling Our Site
Hi there, We get a report from SEOMOZ every week which shows our performance within search. I noticed for our website www.unifor.com.au that it looks through over 10,000 pages, however our website sells less than 500 products so not sure why or how so many pages are trawled? If someone could let me know that would be great. It uses up a lot of bandwidth doing each of these searches so if the amount of pages being trawled reduced it would definitely assist. Thanks, Geoff
Moz Pro | | BeerCartel750 -
"Powered by SEOMOZ" at the bottom of White Label reports?
I'd like to upgrade to Pro Plus for the white label / own branding option. However, I have just noticed that the "white label" pdf reports still feature "Powered by SEOMOZ" at the bottom of each page. Is this a mistake? $2400 / year should be enough to remove SEOMOZ branding completely, surely?
Moz Pro | | AndieF1