When rankings dip what's the best diagnostic procedure?
-
Bonjourno from 10 degrees C lighly raining Wetherby UK
")
Every so often SEO feels like a game of snakes & ladders. One minute your rankings go up and then then within the click of a mouse they drop back down. Like a Greek play you begin to feel our mortal lives as SEO pundits is controlled by the Google Gods.
A case in point is illustrated here in this graph:
http://i216.photobucket.com/albums/cc53/zymurgy_bucket/lincoln-drop_zpseeb04690.jpgNow if i want to explain why the rapid dip has occured for target term "Lincoln Solicitors" here's is what i'd do:
1. Go to webmaster tools and check for crawl errors
2. See if a Google algo change has changed the rules of engagment
3. Check another site administrator hasnt tinkered with the original layout
But i wonder what process do other SEO practitioners follow to explain to a disgruntled client - "Why have my rankings that i pay you to look after nose dived?"
Any insights welcome:-)
-
I would check where those 500-errors originate from. Your website does not handle errors well do - i.e. the link to "/About-Us/Partner-Profiles/Partner-Profiles/Anna-Mosey.aspx" throws a 500 and should really be 404's or 410's.
When I do the search (from South Africa), the search term is on page 1, 4th position.
I would perhaps have a look at validating HTML as well - found it quite strange that the anchor-texts in the have so much trailing whitespace.
-
Well, firstly we can do a simple check against dates of known algorithm updates and see if that matches the drop.
So, you have a good rank on 17th July and have dropped at the next rank check on the 26th July.
Panda 3.9 hit on July 24th so there is every chance the site was flagged in this update so that would be my first port of call to see if this seems a likely case.
It's very hard without a link, but start with the dates and if you find something that seems like it could be the case then review the page to see if it is weak, or a near internal duplicate or some such.
I have checked the 14th result for that search term and the page is pretty weak, I am not sure if this is your client but if it is (first two letters of url are www.bm) then these are very weak pages with little to no unique content beyond the address so this is a page created pretty much entirely for search engines so is typical panda fodder.
So, to resolve? Make this page better along with other similar ones and if that is the case, then it should help resolve matters.
Hope that helps!
Marcus -
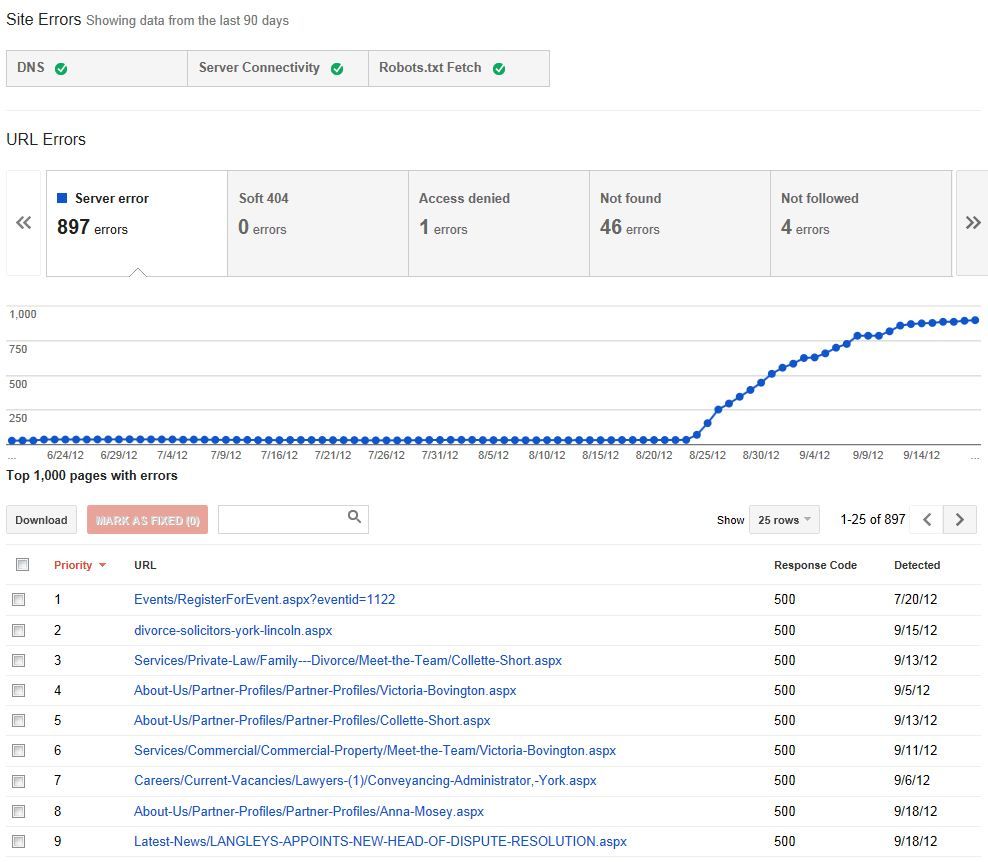
N.B - Looked into webmanster tools and found this:
http://i216.photobucket.com/albums/cc53/zymurgy_bucket/server-errors-langleys_zps10c62870.jpgWould i be right in suggesting this has played a significant part in ranking demotion?
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

What's going on with google index - javascript and google bot
Hi all, Weird issue with one of my websites. The website URL: http://www.athletictrainers.myindustrytracker.com/ Let's take 2 diffrenet article pages from this website: 1st: http://www.athletictrainers.myindustrytracker.com/en/article/71232/ As you can see the page is indexed correctly on google: http://webcache.googleusercontent.com/search?q=cache:dfbzhHkl5K4J:www.athletictrainers.myindustrytracker.com/en/article/71232/10-minute-core-and-cardio&hl=en&strip=1 (that the "text only" version, indexed on May 19th) 2nd: http://www.athletictrainers.myindustrytracker.com/en/article/69811 As you can see the page isn't indexed correctly on google: http://webcache.googleusercontent.com/search?q=cache:KeU6-oViFkgJ:www.athletictrainers.myindustrytracker.com/en/article/69811&hl=en&strip=1 (that the "text only" version, indexed on May 21th) They both have the same code, and about the dates, there are pages that indexed before the 19th and they also problematic. Google can't read the content, he can read it when he wants to. Can you think what is the problem with that? I know that google can read JS and crawl our pages correctly, but it happens only with few pages and not all of them (as you can see above).
Technical SEO | | cobano0 -

Lost ranking and can't figure out why
My page http://www.drschulmanplasticsurgery.com/body/buttock-lift-augmentation-new-york-city/ recently moved from first page to past the 15th. I was never penalized on the last update and have very few links pointing to this page. I can't figure out why i just moved so far back. Can anyone offer some advice?
Technical SEO | | Roots70 -

Hard-working newbie question: benefit of moving my blog to my online store's domain?
Hi all, I've been running an online wine store in Switzerland for a month and have been working hard on SEO (I love learning about it). Anyway, for a couple of years prior to launching the store, I had been running a wine blog whose articles are ranking well in Google. I now want to link the two. My questions are: A) will the addition of the blog (store.com/blog) contribute to the store's domain authority (currently, the blog authority is higher than the site authority)? B) technically, can I 301 the whole blog to store.com/blog? Any help and tips would be appreciated. Thank you!
Technical SEO | | fkupfer0 -

Why am I not showing up in the SERP's or Google Local?
I have been trying to optimise the following site for both Google SERP's and Google Local - Pixel Primate The URL has been around for around 3 years now but they just updated the website and launched it in December 2012. I did the on-page optimisation early in January 2013 and Google seems to have indexed the changes, for the home page at least. One major keyword I am targeting for the home page is 'Web Design Leicester'. I understand that the DA is fairly low (24) so this is something I need to improve. However, I've experienced positive results fairly quickly from just on-page optimisation for other sites I have worked on. The site just doesn't seem to be ranking at all for any keywords. Maybe the industry type is just extremely competitve but I find it very strange to not be visible anywhere in the SERPs. The site does not seem to have any penalties as it ranks for 'Pixel Primate' and all pages appear when doing a site: search. Also what's strange is that I set up the Google Local listing years ago but it doesn't appear anywhere in the local listing, not even when I search for it manually. Any suggestions would be appreciated.
Technical SEO | | CWseo0 -
Product landing page URL's for e-commerce sites - best practices?
Hi all I have built many e-commerce websites over the years and with each one, I learn something new and apply to the next site and so on. Lets call it continuous review and improvement! I have always structured my URL's to the product landing pages as such: mydomain.com/top-category => mydomain.com/top-category/sub-category => mydomain.com/top-category/sub-category/product-name Now this has always worked fine for me but I see more an more of the following happening: mydomain.com/top-category => mydomain.com/top-category/sub-category => mydomain.com/product-name Now I have read many believe that the longer the URL, the less SEO impact it may have and other comments saying it is better to have the just the product URL on the final page and leave out the categories for one reason or another. I could probably spend days looking around the internet for peoples opinions so I thought I would ask on SEOmoz and see what other people tend to use and maybe establish the reasons for your choices? One of the main reasons I include the categories within my final URL to the product is simply to detect if a product name exists in multiple categories on the site - I need to show the correct product to the user. I have built sites which actually have the same product name (created by the author) in multiple areas of the site but they are actually different products, not duplicate content. I therefore cannot see a way around not having the categories in the URL to help detect which product we want to show to the user. Any thoughts?
Technical SEO | | yousayjump0 -

No Google cached snapshot image... 'Text-only version' working.
We are having an issue with Googles cached image snapshops... Here is an example: http://webcache.googleusercontent.com/search?q=cache:IyvADsGi10gJ:shop.deliaonline.com/store/home-and-garden/kitchen/morphy-richards-48781-cooking/ean/5011832030948+&cd=308&hl=en&ct=clnk&gl=uk I wondered if anyone knows or can see the cause of this problem? Thanks
Technical SEO | | pekler1 -

Replacing H1's with images
We host a few Japanese sites and Japanese fonts tend to look a bit scruffy the larger they are. I was wondering if image replacement for H1 is risky or not? eg in short... spiders see: Some header text optimized for seo then in the css h1 {
Technical SEO | | -Al-
text-indent: -9999px;
} h1.header_1{ background:url(/images/bg_h1.jpg) no-repeat 0 0; } We are considering this technique, I thought I should get some advise before potentially jeopardising anything, especially as we are dealing with one of the most important on page elements. In my opinion any attempt to hide text could be seen as keyword stuffing, is it a case that in moderation it is acceptable? Cheers0 -

URL's for news content
We have made modifications to the URL structure for a particular client who publishes news articles in various niche industries. In line with SEO best practice we removed the article ID from the URL - an example is below: http://www.website.com/news/123/news-article-title
Technical SEO | | mccormackmorrison
http://www.website.com/news/read/news-article-title Since this has been done we have noticed a decline in traffic volumes (we have not as yet assessed the impact on number of pages indexed). Google have suggested that we need to include unique numerical IDs in the URL somewhere to aid spidering. Firstly, is this policy for news submissions? Secondly (if the previous answer is yes), is this to overcome the obvious issue with the velocity and trend based nature of news submissions resulting in false duplicate URL/ title tag violations? Thirdly, do you have any advice on the way to go? Thanks P.S. One final one (you can count this as two question credits if required), is it possible to check the volume of pages indexed at various points in the past i.e. if you think that the number of pages being indexed may have declined, is there any way of confirming this after the event? Thanks again! Neil0