After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Pages with Duplicate Content Error
-
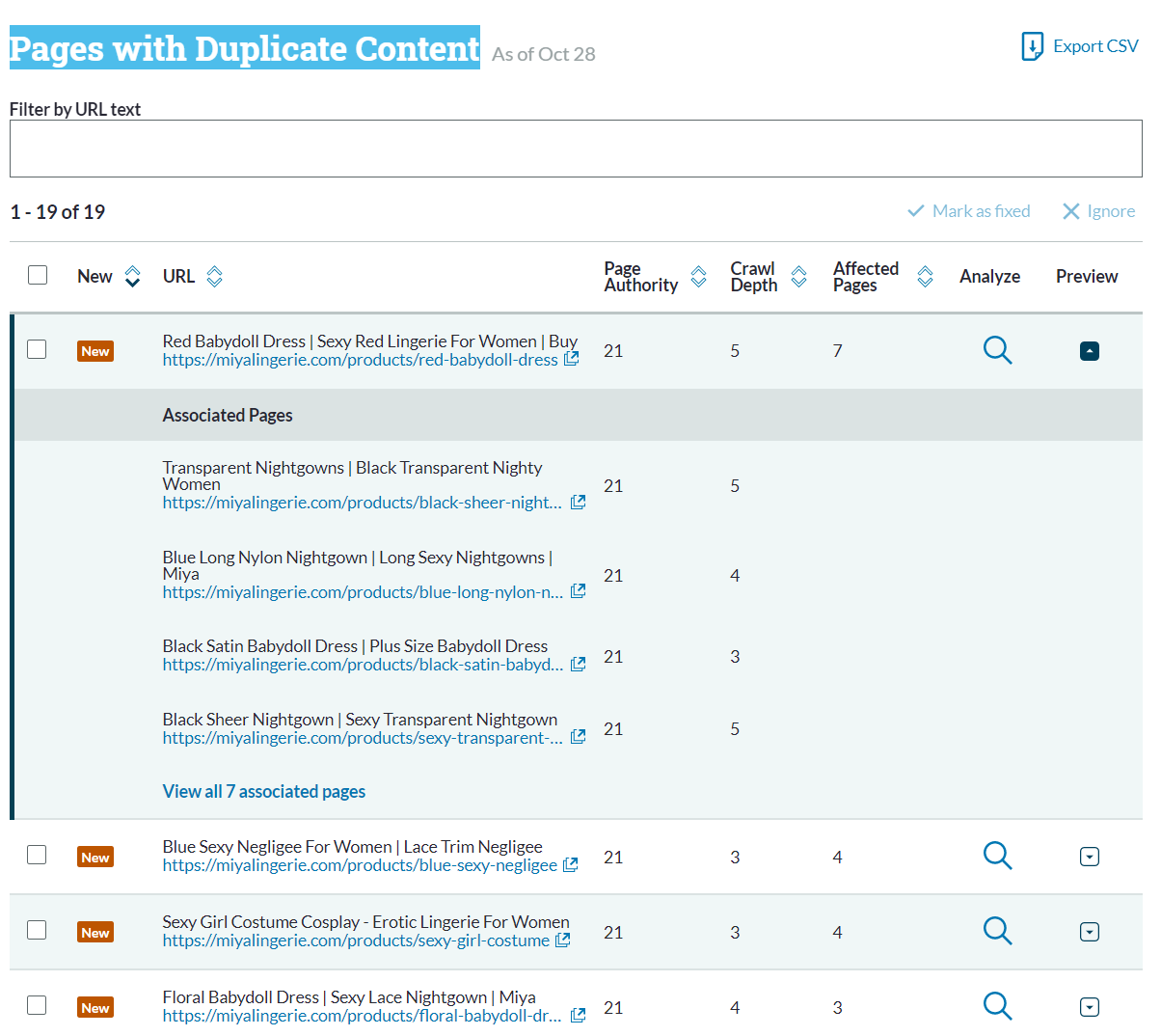
Hello, the result of renewed content appeared in the scan results in my Shopify Store. But these products are unique. Why am I getting this error? Can anyone please help to explain why?
-
How can i find?
-
Remove any duplicate content marketing, replace it with quality white hat text, we done this for a Cardiff Demolition Contractor and got them onto page one of Google.
-
HI there!
Pages can be flagged as duplicate if there isn't enough unique content on each page to distinguish them from each other.
The Moz tools have a 90% threshold for duplicate content, which means that any pages with code that is at least 90% the same will be flagged as duplicates of one another.There is a great Whiteboard Friday video which explains duplicate content, in addition to how unique pages can get flagged.
To solve this you may want to add more unique and valuable content to each page.
At time of writing, you won't get a penalty for duplicate content, however anything you can do to help search engines understand what you content is about, and at the same time creating value for your visitors, will support a strong content marketing and SEO strategy.
I hope this helps!
Jo
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 06657
06657
-
 031.4k
031.4k
-
 051.9k
051.9k
-
 062.0k
062.0k
-
 066.4k
066.4k
-
 033.2k
033.2k
-
 153.9k
153.9k
-
 074.8k
074.8k