Understanding Redirects and Canonical Tags in SEO: A Complex Case
-
Hi everyone,
nothing serious here, i'm just playing around doing my experiments
")
but if any1 of you guys understand this chaos and what was the issue here, i'd appreciate if you try to explain it to me.I had a page "Linkaufbau" on my website at https://chriseo.de/linkaufbau.
My .htaccess file contains only basic SEO stuff:
# removed ".html" using htaccess RewriteCond %{THE_REQUEST} ^GET\ (.*)\.html\ HTTP RewriteRule (.*)\.html$ $1 [R=301,L] # internally added .html if necessary RewriteCond %{REQUEST_FILENAME}.html -f RewriteCond %{REQUEST_URI} !/$ RewriteRule (.*) $1\.html [L] # removed "index" from directory index pages RewriteRule (.*)/index$ $1/ [R=301,L] # removed trailing "/" if not a directory RewriteCond %{REQUEST_FILENAME} !-d RewriteCond %{REQUEST_URI} /$ RewriteRule (.*)/ $1 [R=301,L] # Here’s the first redirect: RedirectPermanent /index /My first three questions:
Why do I need this rule? Why must this rule be at the top? Why isn't this handled by mod_rewrite?Now to the interesting part:
I moved the Linkaufbau page to the SEO folder: https://chriseo.de/seo/linkaufbau and set up the redirect accordingly:
RedirectPermanent /linkaufbau /seo/linkaufbau.htmlI deleted the old /linkaufbau page.
I requested indexing for /seo/linkaufbau in the Google Search Console. Once the page was indexed, I set a canonical to the old URL:
<link rel="canonical" href="https://chriseo.de/linkaufbau">- Then I resubmitted the sitemap and requested indexing for /seo/linkaufbau again, even though it was already indexed.
- Due to the canonical tag, the page quickly disappeared.
- I then requested indexing for /linkaufbau and /linkaufbau.html in GSC (the old, deleted page).
After two days, both URLs were back in the serps::
https://chriseo.de/linkaufbau https://chriseo.de/linkaufbau.htmlthis is the new page /seo/linkaufbau
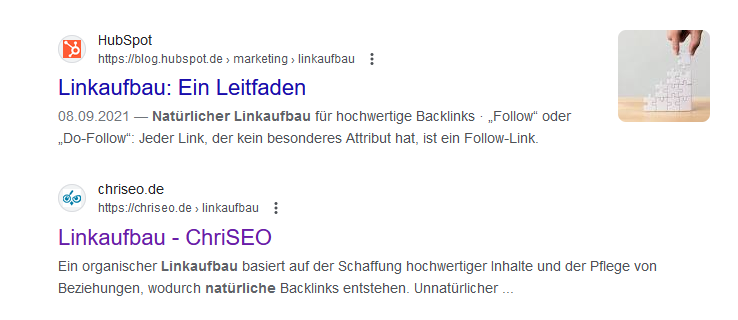
This is the old page /linkaufbau
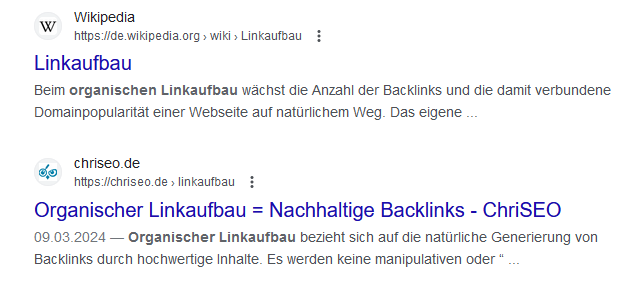
Both URLs are now in the search results and all rankings are significantly better than before for keywords like:
organic linkbuilding linkaufbau kosten linkaufbau service natürlicher linkaufbau hochwertiger linkaufbau organische backlinks linkaufbau strategie linkaufbau agenturInterestingly, both URLs (with and without .html) redirect to the new URL https://chriseo.de/seo/linkaufbau, which in turn has a canonical pointing to https://chriseo.de/linkaufbau (without .html).
In the SERPs, when https://chriseo.de/linkaufbau is shown, my new, updated snippet is displayed. When /linkaufbau.html is shown, it displays the old, deleted page that had already disappeared from the index.
I have now removed the canonical tag.
I don't fully understand the process of what happened and why. If anyone has any ideas, I would be very grateful.
Best regards,
Chris -
When you move a web page from one URL to another, you use redirects to ensure that users and search engines are directed to the new URL. 301 is a permanent redirect. It tells search engines that the page has permanently moved to a new location. 302 is a temporary redirect. It tells search engines that the move is only temporary, so they should keep the original page indexed. Meta Refresh is a type of redirect that happens on the page level. It's not as SEO-friendly as server-side redirects because it doesn't pass the same level of link equity. Canonical tags are HTML elements that help prevent duplicate content issues by specifying the preferred version of a web page.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Why did my Domain Authority drop?
I had an ok domain authority. We focused on building backlinks for our website and it shows that we received a significant number of backlinks. However, today, our DA fell significantly. I don't understand why that happened. Can someone please help me with this situation? Thank you.
Link Building | | MizbaCMU1 -

Migrating Subfolder content to New domain Safely
Hello everyone, I'm currently facing a challenging situation and would greatly appreciate your expertise and guidance. I own a website, maniflexa.com, primarily focused on the digital agency niche. About 3 months ago, I created a subfolder, maniflexa.com/emploi/, dedicated to job listings which is a completely different niche. The subfolder has around 120 posts and pages. Unfortunately, since I created the subfolder, the rankings of my main site have been negatively impacted. I was previously ranking #1 for all local digital services keywords, but now, only 2 out of 16 keywords have maintained their positions. Other pages have dropped to positions 30 and beyond. I'm considering a solution and would like your advice: I'm planning to purchase a new domain and migrate the content from maniflexa.com/emploi/ to newdomain.com. However, I want to ensure a smooth migration without affecting the main domain maniflexa.com rankings and losing backlinks from maniflexa.com/emploi/ pages. Is moving the subfolder content to a new domain a viable solution? And how can I effectively redirect all pages from the subfolder to the new domain while preserving page ranks and backlinks?
Intermediate & Advanced SEO | | davidifaso
I wish they did, but GSC doesn't offer a solution to migration content from subfolder to a new domain. 😢 Help a fellow Mozer. Thanks for giving a hand.0 -

Searchability Strategy
We recently had a technical SEO audit carried out and it highlighted how many clicks it took to get to many of our pages (more than 4)). Does anyone have advice on how to create a structure for our pages to avoid this or recommend any articles I can read?
Technical SEO | | Caroline_Ardmoor0 -
How To Encourage Google To Discover Links?
I got a valuable backlink from a high authority website (MSN), but the link is placed in the middle of a slideshow with 20 pictures, and the only way to reach it is by clicking through the slideshow. After 6 months, this link still hasn't been noticed by Moz or Semrush, and I assume Google hasn't seen it either, because it's in the middle of a slideshow. Is there any way to encourage Google to find this link? Or am I all out of luck?
Link Building | | David56750 -

Duplicate content: using the robots meta tag in conjunction with the canonical tag?
We have a WordPress instance on an Apache subdomain (let's say it's blog.website.com) alongside our main website, which is built in Angular. The tech team is using Akamai to do URL rewrites so that the blog posts appear under the main domain (website.com/more-keywords/here). However, due to the way they configured the WordPress install, they can't do a wildcard redirect under htaccess to force all the subdomain URLs to appear as subdirectories, so as you might have guessed, we're dealing with duplicate content issues. They could in theory do manual 301s for each blog post, but that's laborious and a real hassle given our IT structure (we're a financial services firm, so lots of bureaucracy and regulation). In addition, due to internal limitations (they seem mostly political in nature), a robots.txt file is out of the question. I'm thinking the next best alternative is the combined use of the robots meta tag (no index, follow) alongside the canonical tag to try to point the bot to the subdirectory URLs. I don't think this would be unethical use of either feature, but I'm trying to figure out if the two would conflict in some way? Or maybe there's a better approach with which we're unfamiliar or that we haven't considered?
Technical SEO | | prasadpathapati0 -

Can Anybody Understand This ?
Hey guyz,
Technical SEO | | atakala
These days I'm reading the paperwork from sergey brin and larry which is the first paper of Google.
And I dont get the Ranking part which is: "Google maintains much more information about web documents than typical search engines. Every hitlist includes position, font, and capitalization information. Additionally, we factor in hits from anchor text and the PageRank of the document. Combining all of this information into a rank is difficult. We designed our ranking function so that no particular factor can have too much influence. First, consider the simplest case -- a single word query. In order to rank a document with a single word query, Google looks at that document's hit list for that word. Google considers each hit to be one of several different types (title, anchor, URL, plain text large font, plain text small font, ...), each of which has its own type-weight. The type-weights make up a vector indexed by type. Google counts the number of hits of each type in the hit list. Then every count is converted into a count-weight. Count-weights increase linearly with counts at first but quickly taper off so that more than a certain count will not help. We take the dot product of the vector of count-weights with the vector of type-weights to compute an IR score for the document. Finally, the IR score is combined with PageRank to give a final rank to the document. For a multi-word search, the situation is more complicated. Now multiple hit lists must be scanned through at once so that hits occurring close together in a document are weighted higher than hits occurring far apart. The hits from the multiple hit lists are matched up so that nearby hits are matched together. For every matched set of hits, a proximity is computed. The proximity is based on how far apart the hits are in the document (or anchor) but is classified into 10 different value "bins" ranging from a phrase match to "not even close". Counts are computed not only for every type of hit but for every type and proximity. Every type and proximity pair has a type-prox-weight. The counts are converted into count-weights and we take the dot product of the count-weights and the type-prox-weights to compute an IR score. All of these numbers and matrices can all be displayed with the search results using a special debug mode. These displays have been very helpful in developing the ranking system. "0 -

How do I fix the h1 tag?
No More Than One H1 Tag Easy fix <dl> <dt>Number of H1s</dt> <dd>2</dd> <dt>Explanation</dt> <dd>Best practices for both SEO and accessibility require only a single H1 tag. The H1 is meant to be the page's headline, and thus, multiple H1s are confusing. Consider employing H2, H3 or CSS styles to achieve the same results with text visualization.</dd> <dt>Recommendation</dt> <dd>Remove multiple instances of the H1 tag, so that only one exists on the page.</dd> <dd>I get this error yet it does not tell me how to fix it. I'm not even sure what the H1 tag is?
Technical SEO | | 678648631264
</dd> </dl>0 -

301 Redirect
Hi there, We are re-branding & re-structuring our website, there will be quite a number of 301 re-directs, possibly hundreds. The question is: Should i wait until the re-branding has been completed and do al the 301's in one go?, or should I try and do 301's as i go along? Kind Regards
Technical SEO | | Paul780