Do I need robots.txt and meta robots?
-
If I can manage to tell crawlers what I do and don't want them to crawl for my whole site via my robots.txt file, do I still need meta robots instructions?
-
Older information, but mostly still relevant:
-
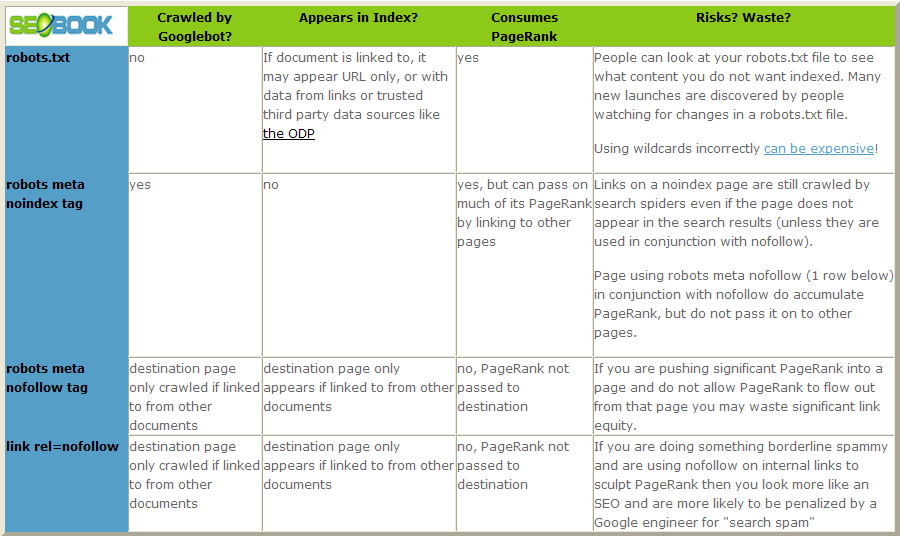
Although robots.txt and meta robots appear to do similar things, they both serve different functions.
Block with Robots.txt - This tells the engines to not crawl the given URL but tells them that they may keep the page in the index and display it in in results.
Block with Meta NoIndex - This tells engines they can visit but they are not allowed to display the URL in results. (this is a suggestion only - Google may still choose to show the URL)
Source: http://www.seomoz.org/learn-seo/robotstxt
The disadvantage of robots.txt is that it blocks Google from crawling the page, meaning no link juice can flow through the page, and if Google discovers the URL through other means (external links) it may show the URL anyway in search results, usually without a meta description.
The advantage of robots.txt is it can improve crawl efficiency - useful if you find Google crawling a bunch of unnecessary pages and eating up your crawl allowance.
Most of the time, I only use robots.txt to solve problems that I can't solve at the page level. I usually prefer to keep pages out of the index using a meta NOINDEX, FOLLOW tag.
-
If you want the stub listing removed as well, this is quite straight forward once you have it blocked in Robots. Instructions here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=1663419
Just checking though: If the content you are trying to remove is something private that should be hidden (as opposed to just low value stuff that you don't want cluttering the SERPS) then this isn't the right way to go about it. If that is the case reply back.
-
Hello Mat,
As far as I know if I blocked a url using robots.txt.For that page I will get only url in serps but i want to remove url from serps also.How to do that?
-
In short, no. You only need to include the instruction in one or the other. Most people find that the robots.txt file is the preferred solution because it will only take a few lines to specify which parts of a well structured site should and should not be crawled.
-
What do you mean by meta robots instructions? Are you referring to the meta tags that go on each individual page? In that case, no, you don't necessarily need them. Robots assume a page should be crawled unless told otherwise. I'd still do it for pages that you don't want indexed and/or followed because a lot of times, robots, especially Google, seem to ignore these directives.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

HTTP Status showing up in opensiteexplorer top pages as blocked by robot.txt file
I am trying to find an answer to this question it has alot of url on this page with no data when i go into the data source and search for noindex or robot.txt but the site is visible in the search engines ?
Technical SEO | | ReSEOlve0 -

Blocking Affiliate Links via robots.txt
Hi, I work with a client who has a large affiliate network pointing to their domain which is a large part of their inbound marketing strategy. All of these links point to a subdomain of affiliates.example.com, which then redirects the links through a 301 redirect to the relevant target page for the link. These links have been showing up in Webmaster Tools as top linking domains and also in the latest downloaded links reports. To follow guidelines and ensure that these links aren't counted by Google for either positive or negative impact on the site, we have added a block on the robots.txt of the affiliates.example.com subdomain, blocking search engines from crawling the full subddomain. The robots.txt file is the following code: User-agent: * Disallow: / We have authenticated the subdomain with Google Webmaster Tools and made certain that Google can reach and read the robots.txt file. We know they are being blocked from reading the affiliates subdomain. However, we added this affiliates subdomain block a few weeks ago to the robots.txt, but links are still showing up in the latest downloads report as first being discovered after we added the block. It's been a few weeks already, and we want to make sure that the block was implemented properly and that these links aren't being used to negatively impact the site. Any suggestions or clarification would be helpful - if the subdomain is being blocked for the search engines, why are the search engines following the links and reporting them in the www.example.com subdomain GWMT account as latest links. And if the block is implemented properly, will the total number of links pointing to our site as reported in the links to your site section be reduced, or does this not have an impact on that figure?From a development standpoint, it's a much easier fix for us to adjust the robots.txt file than to change the affiliate linking connection from a 301 to a 302, which is why we decided to go with this option.Any help you can offer will be greatly appreciated.Thanks,Mark
Technical SEO | | Mark_Ginsberg0 -

Robots.txt Download vs Cache
We made an update to the Robots.txt file this morning after the initial download of the robots.txt file. I then submitted the page through Fetch as Google bot to get the changes in asap. The cache time stamp on the page now shows Sep 27, 2013 15:35:28 GMT. I believe that would put the cache time stamp at about 6 hours ago. However the Blocked URLs tab in Google WMT shows the robots.txt last downloaded at 14 hours ago - and therefore it's showing the old file. This leads me to believe for the Robots.txt the cache date and the download time are independent. Is there anyway to get Google to recognize the new file other than waiting this out??
Technical SEO | | Rich_A0 -

Rankings have fallen suddenly - I need a plan of attack.
I started my business a few years ago. Only recently (6 month) I started to get some good traffic and sales. At first I was ranking pretty well 3-5 for my main keywords and business began to pick up. After Penguin I was hit hard and I'm placing 10-17'ish. My Google local/places has disappeared too. I haven't received any contact from Google about unnatural links (but I'm not sure where that would appear? Email? Web Master Tools? Horses head on my pillow?). I've read so many different things online about what I 'could' do. I'm not sure where to start. I've checked and I know we've created lots of questionable back links. Using the Open Site Explorer lots of the backlinks don't have terrible DA but some do. I guess I was hoping someone would give me a checklist or priority list of things to do. It's just me so I need to use my time as best I can. What should I be doing first? Should I be trying to: Remove my bad backlinks? Spend my time making quality backlinks. On-page issues that I can't see? Telling google i'm sorry via web master tools. Changing to new domain (eek) I'm very time poor and hoped the seoMoz community might save me from wasting my time. www.bringyourownlaptop.com.au Keywords: indesign training, web design courses & photoshop courses Thank you in advance. Dan
Technical SEO | | danlovesadobe0 -

Issue Missing Meta Description Tag
Hello Friends, Today I found missing meta description tag when Seomoz update my website crawl diagnostics. I recovered other type missing meta description tag but I don't understand how can I recover this type page. Here is the examples. http://www.example.com/blog/page/2/ http://www.example.com/blog/page/3/ http://www.example.com/blog/page/4/ Links continue...... Thanks KLLC
Technical SEO | | KLLC0 -

Using Robots.txt
I want to Block or prevent pages being accessed or indexed by googlebot. Please tell me if googlebot will NOT Access any URL that begins with my domain name, followed by a question mark,followed by any string by using Robots.txt below. Sample URL http://mydomain.com/?example User-agent: Googlebot Disallow: /?
Technical SEO | | semer0 -

Robots.txt not working?
Hello This is my robots.txt file http://www.theprinterdepo.com/Robots.txt However I have 8000 warnings on my dashboard like this:4 What am I missing on the file¿ Crawl Diagnostics Report On-Page Properties <dl> <dt>Title</dt> <dd>Not present/empty</dd> <dt>Meta Description</dt> <dd>Not present/empty</dd> <dt>Meta Robots</dt> <dd>Not present/empty</dd> <dt>Meta Refresh</dt> <dd>Not present/empty</dd> </dl> URL: http://www.theprinterdepo.com/catalog/product_compare/add/product/100/uenc/aHR0cDovL3d3dy50aGVwcmludGVyZGVwby5jb20vaHAtbWFpbnRlbmFjZS1raXQtZm9yLTQtbGo0LWxqNS1mb3ItZXhjaGFuZ2UtcmVmdWJpc2hlZA,,/ 0 Errors No errors found! 1 Warning 302 (Temporary Redirect) Found about 5 hours ago <a class="more">Read More</a>
Technical SEO | | levalencia10