When rankings dip what's the best diagnostic procedure?
-
Bonjourno from 10 degrees C lighly raining Wetherby UK
")
Every so often SEO feels like a game of snakes & ladders. One minute your rankings go up and then then within the click of a mouse they drop back down. Like a Greek play you begin to feel our mortal lives as SEO pundits is controlled by the Google Gods.
A case in point is illustrated here in this graph:
http://i216.photobucket.com/albums/cc53/zymurgy_bucket/lincoln-drop_zpseeb04690.jpgNow if i want to explain why the rapid dip has occured for target term "Lincoln Solicitors" here's is what i'd do:
1. Go to webmaster tools and check for crawl errors
2. See if a Google algo change has changed the rules of engagment
3. Check another site administrator hasnt tinkered with the original layout
But i wonder what process do other SEO practitioners follow to explain to a disgruntled client - "Why have my rankings that i pay you to look after nose dived?"
Any insights welcome:-)
-
I would check where those 500-errors originate from. Your website does not handle errors well do - i.e. the link to "/About-Us/Partner-Profiles/Partner-Profiles/Anna-Mosey.aspx" throws a 500 and should really be 404's or 410's.
When I do the search (from South Africa), the search term is on page 1, 4th position.
I would perhaps have a look at validating HTML as well - found it quite strange that the anchor-texts in the have so much trailing whitespace.
-
Well, firstly we can do a simple check against dates of known algorithm updates and see if that matches the drop.
So, you have a good rank on 17th July and have dropped at the next rank check on the 26th July.
Panda 3.9 hit on July 24th so there is every chance the site was flagged in this update so that would be my first port of call to see if this seems a likely case.
It's very hard without a link, but start with the dates and if you find something that seems like it could be the case then review the page to see if it is weak, or a near internal duplicate or some such.
I have checked the 14th result for that search term and the page is pretty weak, I am not sure if this is your client but if it is (first two letters of url are www.bm) then these are very weak pages with little to no unique content beyond the address so this is a page created pretty much entirely for search engines so is typical panda fodder.
So, to resolve? Make this page better along with other similar ones and if that is the case, then it should help resolve matters.
Hope that helps!
Marcus -
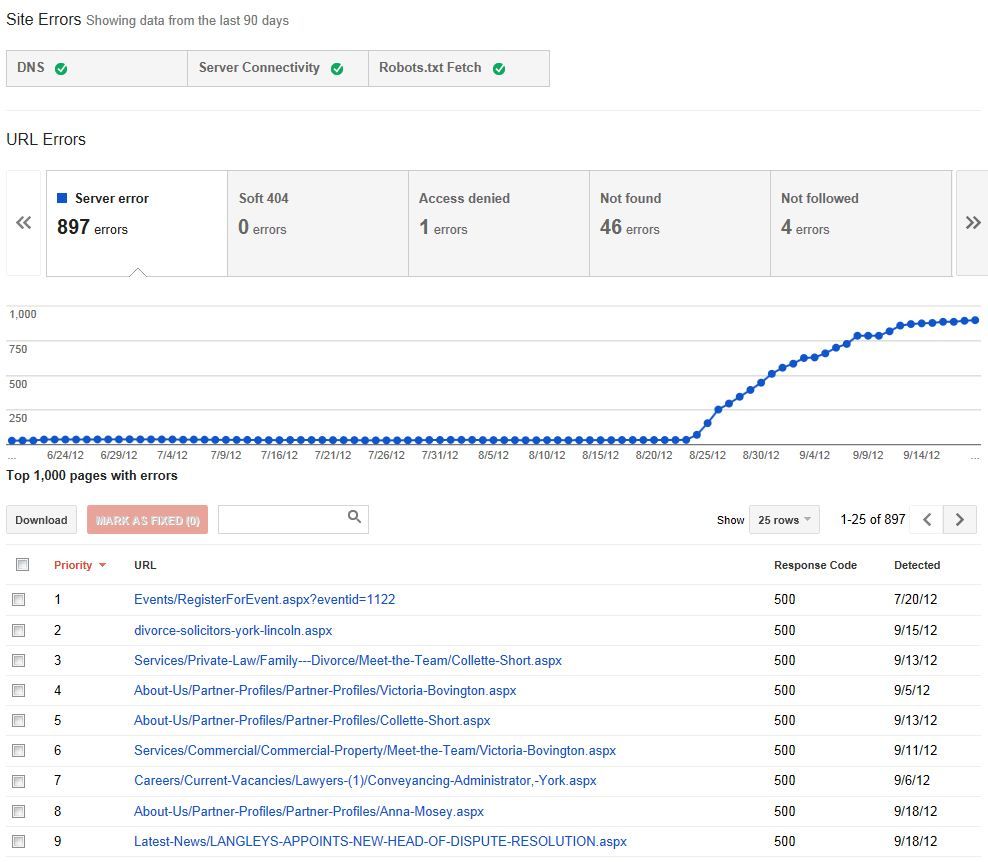
N.B - Looked into webmanster tools and found this:
http://i216.photobucket.com/albums/cc53/zymurgy_bucket/server-errors-langleys_zps10c62870.jpgWould i be right in suggesting this has played a significant part in ranking demotion?
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Sitemap url's not being indexed
There is an issue on one of our sites regarding many of the sitemap url's not being indexed. (at least 70% is not being indexed) The url's in the sitemap are normal url's without any strange characters attached to them, but after looking into it, it seems a lot of the url's get a #. + a number sequence attached to them once you actually go to that url. We are not sure if the "addthis" bookmark could cause this, or if it's another script doing it. For example Url in the sitemap: http://example.com/example-category/0246 Url once you actually go to that link: http://example.com/example-category/0246#.VR5a Just for further information, the XML file does not have any style information associated with it and is in it's most basic form. Has anyone had similar issues with their sitemap not being indexed properly ?...Could this be the cause of many of these url's not being indexed ? Thanks all for your help.
Technical SEO | | GreenStone0 -

Good alternatives to Xenu's Link Sleuth and AuditMyPc.com Sitemap Generator
I am working on scraping title tags from websites with 1-5 million pages. Xenu's Link Sleuth seems to be the best option for this, at this point. Sitemap Generator from AuditMyPc.com seems to be working too, but it starts handing up, when a sitemap file, the tools is working on,becomes too large. So basically, the second one looks like it wont be good for websites of this size. I know that Scrapebox can scrape title tags from list of url, but this is not needed, since this comes with both of the above mentioned tools. I know about DeepCrawl.com also, but this one is paid, and it would be very expensive with this amount of pages and websites too (5 million ulrs is $1750 per month, I could get a better deal on multiple websites, but this obvioulsy does not make sense to me, it needs to be free, more or less). Seo Spider from Screaming Frog is not good for large websites. So, in general, what is the best way to work on something like this, also time efficient. Are there any other options for this? Thanks.
Technical SEO | | blrs120 -

How to Remove /feed URLs from Google's Index
Hey everyone, I have an issue with RSS /feed URLs being indexed by Google for some of our Wordpress sites. Have a look at this Google query, and click to show omitted search results. You'll see we have 500+ /feed URLs indexed by Google, for our many category pages/etc. Here is one of the example URLs: http://www.howdesign.com/design-creativity/fonts-typography/letterforms/attachment/gilhelveticatrade/feed/. Based on this content/code of the XML page, it looks like Wordpress is generating these: <generator>http://wordpress.org/?v=3.5.2</generator> Any idea how to get them out of Google's index without 301 redirecting them? We need the Wordpress-generated RSS feeds to work for various uses. My first two thoughts are trying to work with our Development team to see if we can get a "noindex" meta robots tag on the pages, by they are dynamically-generated pages...so I'm not sure if that will be possible. Or, perhaps we can add a "feed" paramater to GWT "URL Parameters" section...but I don't want to limit Google from crawling these again...I figure I need Google to crawl them and see some code that says to get the pages out of their index...and THEN not crawl the pages anymore. I don't think the "Remove URL" feature in GWT will work, since that tool only removes URLs from the search results, not the actual Google index. FWIW, this site is using the Yoast plugin. We set every page type to "noindex" except for the homepage, Posts, Pages and Categories. We have other sites on Yoast that do not have any /feed URLs indexed by Google at all. Side note, the /robots.txt file was previously blocking crawling of the /feed URLs on this site, which is why you'll see that note in the Google SERPs when you click on the query link given in the first paragraph.
Technical SEO | | M_D_Golden_Peak0 -

Correct linking to the /index of a site and subfolders: what's the best practice? link to: domain.com/ or domain.com/index.html ?
Dear all, starting with my .htaccess file: RewriteEngine On
Technical SEO | | inlinear
RewriteCond %{HTTP_HOST} ^www.inlinear.com$ [NC]
RewriteRule ^(.*)$ http://inlinear.com/$1 [R=301,L] RewriteCond %{THE_REQUEST} ^./index.html
RewriteRule ^(.)index.html$ http://inlinear.com/ [R=301,L] 1. I redirect all URL-requests with www. to the non www-version...
2. all requests with "index.html" will be redirected to "domain.com/" My questions are: A) When linking from a page to my frontpage (home) the best practice is?: "http://domain.com/" the best and NOT: "http://domain.com/index.php" B) When linking to the index of a subfolder "http://domain.com/products/index.php" I should link also to: "http://domain.com/products/" and not put also the index.php..., right? C) When I define the canonical ULR, should I also define it just: "http://domain.com/products/" or in this case I should link to the definite file: "http://domain.com/products**/index.php**" Is A) B) the best practice? and C) ? Thanks for all replies! 🙂
Holger0 -

Possible penguin hit but then back, now what's next?
hiz, i did a little check on my site by answering the quiz at mytrafficdropped.com and there was a question about on what dates there was drop in organic. and i did checked my analytics on a top sending keyword. here is what i found. see attached image . Traffic dropped totally on April 20 to onwards. Then got back better in june, but again dropped in October, still down.. anythoughts guys ? 1Jk47.png
Technical SEO | | wickedsunny10 -

Redirect old URL's from referring sites?
Hi I have just came across some URL's from the previous web designer and the site structure has now changed. There are some links on the web however that are still pointing at the old deep weblinks. Without having to contact each site it there a way to automatically sort the links from the old structure www.mydomain.com/show/english/index.aspx to just www.mydomain.com Many Thanks
Technical SEO | | ocelot0 -

What's the best way to solve this sites duplicate content issues?
Hi, The site is www.expressgolf.co.uk and is an e-commerce website with lots of categories and brands. I'm trying to achieve one single unique URL for each category / brand page to avoid duplicate content and to get the correct URL's indexed. Currently it looks like this... Main URL http://www.expressgolf.co.uk/shop/clothing/galvin-green Different Versions http://www.expressgolf.co.uk/shop/clothing/galvin-green/ http://www.expressgolf.co.uk/shop/clothing/galvin-green/1 http://www.expressgolf.co.uk/shop/clothing/galvin-green/2 http://www.expressgolf.co.uk/shop/clothing/galvin-green/3 http://www.expressgolf.co.uk/shop/clothing/galvin-green/4 http://www.expressgolf.co.uk/shop/clothing/galvin-green/all http://www.expressgolf.co.uk/shop/clothing/galvin-green/1/ http://www.expressgolf.co.uk/shop/clothing/galvin-green/2/ http://www.expressgolf.co.uk/shop/clothing/galvin-green/3/ http://www.expressgolf.co.uk/shop/clothing/galvin-green/4/ http://www.expressgolf.co.uk/shop/clothing/galvin-green/all/ Firstly, what is the best course of action to make all versions point to the main URL and keep them from being indexed - Canonical Tag, NOINDEX or block them in robots? Secondly, do I just need to 301 the (/) from all URL's to the non (/) URL's ? I'm sure this question has been answered but I was having trouble coming to a solution for this one site. Cheers, Paul
Technical SEO | | paulmalin0 -

Should I have a 'more' button for links?
I have a website that has a page for each town. rather than listing all the towns with a link to each, I want to show only the most popular towns and have a 'more' button that shows all of them when you click it. I know that the search engine can always see the full list of links and even though the visitor can't this doesn't go against Google guidelines because there is no deception involved, the more button is quite clear. However, my colleague is concerned that this is 'making life hard' for the search engines and so the pages are less likely to be indexed. I disagree. Is he right to worry about this??
Technical SEO | | mascotmike0