How do i fix temporary redirects from Volusion?
-
I have around 20 temporary redirects that i can not really change. they look like this:
See attached
As you can see they are from LOGIN.ASP. This are system calls. I think the last thing I tried was blocking them in my robottxt file. but it doesn't seem to make a difference. Am I being effected by these redirects? How will Google look at them?
-
I actually got rid of The articles.asp links because they were not descriptive in the urls. I chose to create pages as opposed to these article snap-ins. They are still in my article menu i suppose, but there should be no links or menus items pointing directly to the article.asp(s). did you see that there were?
Yes i will have duplicate content. My blog www.bestbybrazil.com similar name without "fit" is set to auto post to several sites at once. If my website www.bestfitbybrazil.com is showing some of the same content, then again this must be pulling from the pages that were set up before. I think Volusion will still show stuff that you have in the background even if you dont have it on your website. So i will try deleting them i guess. kind of a pack rat with data. Always think i might be able to use it again.
by the way it looks like MOZ is only showing one other fix for me "Overly Dynamic Url"
http://www.bestfitbybrazil.com/NEW-ARRIVALS-s/1931.htm?searching=Y&sort=4&cat=1931&show=300&page=1
How do i get rid of this? Its not even a page. its a search. the page is as follows
http://www.bestfitbybrazil.com/NEW-ARRIVALS-s/1931.htm. Everything after is some kind of query. Do I need to enter the entire link as a dissallow in robot text or contact volusion. Not sure how much help they would be since MOZ is showing this.
Seems to work when i added the disallow in robot.text
-
Hi Robert,
Weird, you are right - the canonical tag appears on the majority of pages, but not on a select few, like https://www.bestfitbybrazil.com/Articles.asp?ID=282, which is indexed with its https URL. Is there something different you can see about this URL structure or where it sits in the site that might cause this? Could be worth pointing this one out to the Volusion team too. It appears that no URL with the Articles.asp?ID= structure has a canonical tag.
The other thing I see about this URL by just having a play around is that just changing the query string at the end to 283 as opposed to 282 is bring up the same page: http://www.bestfitbybrazil.com/Articles.asp?ID=283
Unrelated to the initial issue but a lot of the site's content is also duplicated on http://bestfitbybrazil.blogspot.co.uk/, a Google plus page and Tumblr e.g. https://www.google.co.uk/search?q=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&oq=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&aqs=chrome..69i57.1069j0j9&sourceid=chrome&es_sm=91&ie=UTF-8#filter=0&q=%22Bia+Brazil+Leggings+LE2854+are+sophisticated+and+versitile+sexy+leggings.+They+fit+like+a+glove%2C+shaping+and+enhancing+your+figure.%22&safe=off
-
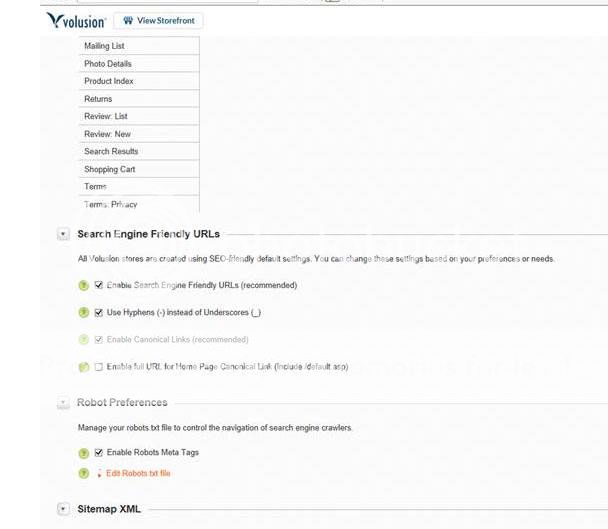
Thanks for you help Travis. Jane, I'm a little confused about this http vs https. I know they mean, but not whats happiening. I use Volusion. This a snap shot of my settings. Doesn't this take care of the Canonical concern or do i need to check something else on? Volusion support claims this is fine. Are you seeing something that might reflect its not. There setting is supposed to handle the default.asp vs. other dupe issues. My settings
-
Hi Robert,
Disallowing these in robots.txt is the correct thing to do here - this takes away any potential Google problem regarding the login pages. Google MIGHT still index them (but it's not - see here) because blocking via robots.txt says "don't crawl this" rather than "don't index this URL". Subtle difference, but you do sometimes see URLs that are blocked in robots.txt showing up in the index as JUST a URL (no title tag or meta description, since Google was not allowed to crawl the page). An example from your own site is the affiliate sign up page, which is blocked but indexed (see screenshot here).
Moz obeys robots.txt but it's showing these errors, likely because it has seen the links to those redirecting pages somewhere. But Google should not be a problem.
Regarding the HTTPS issue Travis pointed out, check out this search. This shows that you have pages with HTTPS URLs indexed - the top result for me is this page.
You need to implement the canonical tag to point to the preferred version of each URL (HTTP or HTTPS), or implement 301 redirects from one to the other, so URLs like this one are not indexed as they are now.
Cheers,
Jane
-
If the URLs were indexed, found and bookmarked, then visited at a later date - possibly - you're missing some sales. I doubt it, but that's something to keep in mind for the future.
The Moz forum is the place to ask about further questions. I may not have the time to get back to you, or not in the time frame you need.
Sending away soon-ish.
-
seems like MOZ is not finding the redirects since I disallowed them in robot txt using **"Disallow: /reviewhelpful.asp" **. The only way a live person would try to find these links in search is if they were just entered something like the "product name + rating" google finds it. I guess that means it doesn't need to be indexed to be found??
Anyhow my email is support@bestfitbybrazil.com
thx.
-
Google won't index what it can't crawl. You should be alright, from a duplicate content perspective. If people, real live ones, are trying to reach the site via this link, then you might have problems. If they can't reach it, you can't sell. You'll have to check your server log files to figure that out.
If actual 'hoomans' are trying to reach that URL (Not me bro, you don't want to see me in leggings. I'm in Grapevine TX. You can discount that traffic.)
Otherwise, I like to do a little more than the standard here's a blog link response. This is especially the case when I have an actual site to work with, not a vague question. A portion of the secure version of the site can be crawled, while obeying robots/nofollow which can lead to duplicate content concerns.
Send me a message with your email and I can send you the crawl. At least you'll be able sort out that issue. Your main concern may be a non-concern.
-
Hi Travis. and thx for your response. a little confused by what you mean. http and https "can" be crawled in a limited fashion??? did you mean "can't"? and if so, what then? how does that relate to my question. Generating duplicate content? please elaborate. You seem to raise more questions here
") I need answers... lol. thx.
I need answers... lol. thx.btw this is my robot txt file. I've been blocking the directories that keep coming up as 302 redirects. is this good or bad? I noticed alot of these are from customer reiviews.
Disallow: /cgi-bin/
Disallow: /mobile/category.aspx
Disallow: /myaccount.asp
Disallow: /shoppingcart.asp
Disallow: /orders.asp
Disallow: /AccountSettings.asp
Disallow: /net/FreeShipping.aspx
Disallow: /net/AuthenticateSession.aspx
Disallow: /affiliate_signup.asp
Disallow: /GiftCert_default.asp
Disallow: /redeem/
Disallow: /MyAccount_ApplyGift.asp
Disallow: /help_answer.asp
Disallow: /login.asp
Disallow: /login_sendpass.asp
Disallow: /SearchResults.asp?Cat=1956
Disallow: /category-s/1960.htm
Disallow: /MailingList_subscribe.asp
Disallow: /reviewhelpful.asp -
You have bigger problems. The HTTP and the HTTPS version of the site can be crawled in a limited fashion. Long story short, the site is generating it's own duplicate content.
My question is; "If they are paying to drive traffic to this URL, then why is it doing this?"
This isn't deadly, it's just not good.
{kind=link}
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Redirection Problem
I have a site that has 2,50,000 pages and I want to redirect to another domain. Is it good practice for SEO and google?
Intermediate & Advanced SEO | | MuhammadQasimAttari0 -

After 301 redirect
hello i do after 301 redirect from old domain to new since 3 month ago my qa : should i replace the backlinks links to new doamin Or the he backlinks in the old link will works
Intermediate & Advanced SEO | | cristophare790 -

Have You 301 Redirected Domain A to Domain B ?
I only have two questions.... Approximately when did you do it (year is close enough)? Did the rankings of Domain B go up? Any other information that you care to share will be appreciated. Thank you!
Intermediate & Advanced SEO | | EGOL0 -

Redirect to url with parameter
I have a wiki (wiki 1) where many of the pages are well index in google. Because of a product change I had to create a new wiki (wiki 2) for the new version of my product. Now that most of my customers are using the new version of my product I like to redirect the user from wiki 1 to wiki 2. An example of a redirect could be from wiki1.website.com/how_to_build_kitchen to wiki2.website.com/how_to_build_kitchen. Because of a technical issue the url I redirect to, needs to have a parameter like "?" so the example will be wiki2.website.com/how_to_build_kitchen? Will the search engines see it as I have two pages with same content?
Intermediate & Advanced SEO | | Debitoor
wiki2.website.com/how_to_build_kitchen
and
wiki2.website.com/how_to_build_kitchen? And will the SEO juice from wiki1.website.com/how_to_build_kitchen be transfered to wiki2.website.com/how_to_build_kitchen?0 -

Best Approach to Redirect One Domain to Another
So I'm about to migrate one domain to another. Lets say I'm migrating boo.com to foo.com. Boo.com has good organic traffic & has some really well ranked pages. For this reason (I think) I want to send that traffic to some where other than the foo.com homepage. Perhaps a catered landing page. My question is can I redirect some of the specific pages on boo.com to a landing page on foo.com & then redirect the delta to foo.com's homepage? Or am a risking not fully transferring the full credit of one domain to another if I take that approach & therefore I should just redirect one domain to the other in its entirety? Thanks, Rich
Intermediate & Advanced SEO | | RPD0 -

Redirect multiple domains to a primary domain
Hello that such I make the following query imagine we have three domains on the same thematic or category primary domain: domain-antiguo1.com (3 years) (200 Backlink), domain-antiguo2.net (10 years) (1000 Backlinks) and domain-antiguo3.com (6 years) (500 Backlinks) and decide to redirect all these domains favorite one: domain-principal.com The three domains registered refeccionar this google webmaster, has its respective income sitemap and google webmaster area change of address to the main domain the three domains are my property It would have a penalty for doing this practice?
Intermediate & Advanced SEO | | globotec0 -

301 redirect every pages?
Good evening, my question might sound stupid but please forgive me, I am still learning SEO. If I build a new site that will replace an existing site. Is there any point to do a 301 redirect for pages that had no inbound link so, no juice to pass? I kind of think that it would be a better practice to 301 redirect each pages to a page that make sense on the new web site .... but here is why I think that. Why I say that If I am lucky, many of my old web site pages will be indexed, many of them having no inbound links. So once the new web site online, until all my new web sites pages are indexed, I could imagine Google would send people to the index pages (the old ones that do not exist anymore)... I am right? So in that case, if I do a 301 redirect only for pages that have inbound links, the user would end up on a 404 page. Could you tell me if it make sense how I think? Thanks a lot !! Nancy P.S. I would not redirect if it make no sense to the user. I fully understand that we must always keep the user experience in mind in any 404 and 301 redirect decisions. But to simplify the question, just suppose it is ok from a user perspective to map every old site pages to a page in new web site.
Intermediate & Advanced SEO | | EnigmaSolution0 -

How to 301 redirect ASP.net URLS
I have a situation where a site that was ASP.net has been replaced with a WordPress site. I've performed a Open Site Explorer analysis and found that most of the old pages, ie www.i3bus.com/ProductCategorySummary.aspx?ProductCategoryId=63 are returning a HTTP Status = NO DATA ... when followed ends up at the 404 catch-all page. Can I code the standard 301 Redirects in the .htaccess file for these ASP URLs? If not, I'm open to suggestions.... Thanks Bill
Intermediate & Advanced SEO | | Marvo0