Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
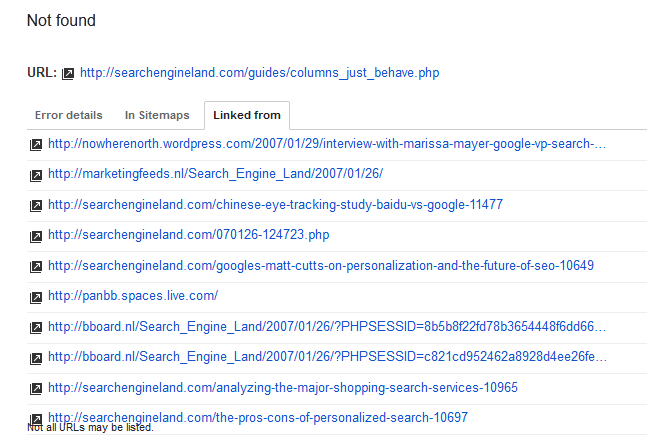
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Please Help! Crawl & Site Errors - Will This Impact My SEO?
Hello Moz, I need urgent help. I remove a tonne of product pages and put everything into one product page to deal with duplicate content. I thought this was a good thing to do until I got an email from Google saying: "Googlebot identified a significant increase in the number of URLs on ****.com that return a 404 (not found) error. " I checked it out and found the problem: 4 Soft 404's
Technical SEO | | crocman
41 Not Found's What do I need to do to fix this? Is it a problem or should I just ignore? I removed all the pages on WordPress but I need to do it somehow manually through Google? I have worked so hard on my SERP's that this will destroy me if I'm penalised. Please can someone advise?0 -

Lots of backs links from Woorank reported by GWT
Hello We just sow a lots of links from woorank website ( 138 ) reported in our "Links to your site" at google webmaster tools, do you think we should consider add to submit that website for disavow in google webmaster tools ? Rgds
Technical SEO | | helpgoabroad0 -

Help Crawl friendliness for large site
After watching Rand's video I am trying to think of the best way to make my large site more crawl friendly. Background I have a large site with over 100k product skus and so when you get to a particular page of products there are tons of different refinements and options that help you sort the products. Most of these are noindex followed, but I was wondering if I should be nofollowing the internal links as well in order to keep bots out of those pages and going to the pages that I want them to go too. Is this a good way to handle it? Also, does anyone have good recommendations of links to posts that deal with helping the crawl friendliness of a large site? Thanks!
Technical SEO | | Gordian0 -

Moz Crawl Diagnostic shows lots of duplicate content issues
Hi my client's website uses URL with www and without www. In page/title both website shows up. The one with www has page authority of 51 and the one without 45. In Moz diagnostic I can see that the website shows over 200 duplicate content which are not found in , e.g. Webmaster. When I check each page and add/remove www then the website shows the same content for both www and no www. It is not redirect - in search tab it actually shows www and then if you use no www it doesn't show www. Is the www issue to blame? or could it be something else? and what do I do since both www URL and no-www URL have high authority, just set up redirect from lower authority URL to higher authority URL?
Technical SEO | | GardenPet0 -

Duplicate content on report
Hi, I just had my Moz Campaign scan 10K pages out of which 2K were duplicate content and URL's are http://www.Somesite.com/modal/register?destination=question%2F37201 http://www.Somesite.com/modal/register?destination=question%2F37490 And the title for all 2K is "Register" How can i deal with this as all my pages have the register link and login and when done it comes back to the same page where we left and that it actually not duplicate but we need to deal with it propely thanks
Technical SEO | | mtthompsons0 -
My website pages are not crawled, what to do?
Hi all. I have made some changes on the website so i like to crawled them by the search engines Google especially. I have made these changes around 2 weeks ago. I have submitted my website on good bookmarking websites. Also i used a tool available in Google webmasters "Fetch as Google", Resubmitted a sitemap.xml. Still my pages are not crawled your opinion please. Thanks
Technical SEO | | lucidsoftech0 -

Google Crawler Error / restricting crawling
Hi On a Magento Instance we manage there is an advanced search. As part of the ongoing enhancement of the instance we altered the advance search options so there are less and more relevant. The issue is Google has crawled and catalogued the advanced search with the now removed options in the query string. Google keeps crawling these out of date advanced searches. These stale searches now create a 500 error. Currently Google is attempting to crawl these pages twice a day. I have implemented the following to stop this:- 1. Submitted requested the url be removed via Webmaster tools, selecting the directory option using uri: http://www.domian.com/catalogsearch/advanced/result/ 2. Added Disallow to robots.txt Disallow: /catalogsearch/advanced/result/* Disallow: /catalogsearch/advanced/result/ 3. Add rel="nofollow" to the links in the site linking to the advanced search. Below is a list of the links it is crawling or attempting to crawl, 12 links crawled twice a day each resulting in a 500 status. Can anything else be done? http://www.domain.com/catalogsearch/advanced/result/?bust_line=94&category=55&color_layered=128&csize[0]=0&fabric=92&inventry_status=97&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=115&category=55&color_layered=130&csize[0]=0&fabric=0&inventry_status=97&length=116&price=3%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=94&category=55&color_layered=126&csize[0]=0&fabric=92&inventry_status=97&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=137&csize[0]=0&fabric=93&inventry_status=96&length=0&price=8%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=142&csize[0]=0&fabric=93&inventry_status=96&length=0&price=4%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=137&csize[0]=0&fabric=93&inventry_status=96&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=142&csize[0]=0&fabric=93&inventry_status=96&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=135&csize[0]=0&fabric=93&inventry_status=96&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=128&csize[0]=0&fabric=93&inventry_status=96&length=0&price=5%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=127&csize[0]=0&fabric=93&inventry_status=96&length=0&price=4%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=127&csize[0]=0&fabric=93&inventry_status=96&length=0&price=3%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=128&csize[0]=0&fabric=93&inventry_status=96&length=0&price=10%2C10http://www.domain.com/catalogsearch/advanced/result/?bust_line=0&category=55&color_layered=122&csize[0]=0&fabric=93&inventry_status=96&length=0&price=8%2C10
Technical SEO | | Flipmedia1120 -

How to stop Search Bot from crawling through a submit button
On our website http://www.thefutureminders.com/, we have three form fields that have three pull downs for Month, Day, and year. This is creating duplicate pages while indexing. How do we tell the search Bot to index the page but not crawl through the submit button? Thanks Naren
Technical SEO | | NarenBansal0