Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
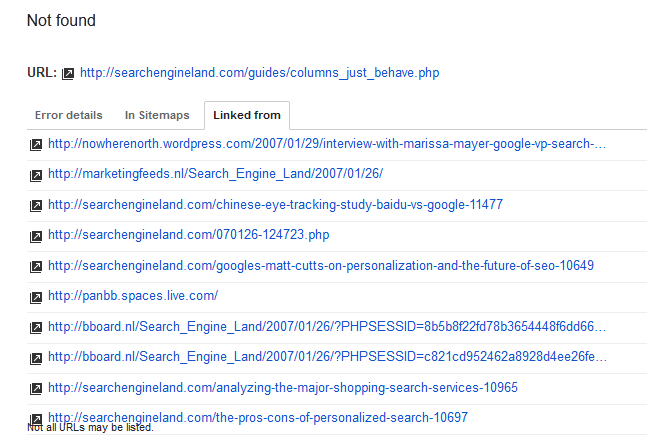
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Any crawl issues with TLS 1.3?
Not a techie here...maybe this is to be expected, but ever since one of my client sites has switched to TLS 1.3, I've had a couple of crawl issues and other hiccups. First, I noticed that I can't use HTTPSTATUS.io any more...it renders an error message for URLs on the site in question. I wrote to their support desk and they said they haven't updated to 1.3 yet. Bummer, because I loved httpstatus.io's functionality, esp. getting bulk reports. Also, my Moz campaign crawls were failing. We are setting up a robots.txt directive to allow rogerbot (and the other bot), and will see if that works. These fails are consistent with the date we switched to 1.3, and some testing confirmed it. Anyone else seeing these types of issues, and can suggest any workarounds, solves, hacks to make my life easier? (including an alternative to httpstatus.io...I have and use screaming frog...not as slick, I'm afraid!) Do you think there was a configuration error with the client's TLS 1.3 upgrade, or maybe they're using a problematic/older version of 1.3?? Thanks -
Technical SEO | | TimDickey0 -

Google only crawling a small percentage of the sitemap
Hi, The company which I work for have developed a new website for a customer, there URL is https://www.wideformatsolutions.co.uk I've created a sitemap which has 25,555 URL's. I submitted this to Google around 4 weeks ago and the most crawls that have ever occurred has been 2,379. I've checked everything I can think of, including; Speed of website Canonical Links 404 errors Setting a preferred domain Duplicate content Robots Txt .htaccess Meta Tags I did read that Matt Cutts revealed in an interview with Eric Enge that the number of pages Google crawls is roughly proportional to your pagerank. But I'm sure it should crawl more than 2000 pages. The website is based on Opencart, if anyone has experienced anything like this I would love hear from you.
Technical SEO | | chrissmithps0 -

Lots of backs links from Woorank reported by GWT
Hello We just sow a lots of links from woorank website ( 138 ) reported in our "Links to your site" at google webmaster tools, do you think we should consider add to submit that website for disavow in google webmaster tools ? Rgds
Technical SEO | | helpgoabroad0 -

Does bing accept meta name="fragment" for AJAX crawling?
I have a case in which the whole site is AJAX, the method to appease to crawlers used is <meta< span="">name="fragment" content="!"> Which is the new HTML5 PushState that Bing said it supports (At least I think it is that) This approach works for Google, but Bing isn't showing anything. Does anyone know if Bing supports this and we have to alter something or if not is there a known work around? The only other logic we have is to recognize the bing user agent and redirect to the rendered page, but we were worried that could cause some kind of cloaking penalty</meta<>
Technical SEO | | MarloSchneider0 -

Rip Off Report.com?
Who has had dealing with Rip Off Report.com They posted a "rip off report" about my client. At the top of the site it has a banner to hire an SEO that can get rid of this "negative online reputation." Black Hat?
Technical SEO | | JML11790 -

Http VS https and google crawl and indexing ?
Is it true that https pages are not crawled and indexed by Google and other search engines as well as http pages?
Technical SEO | | sherohass0 -

Having a massive amount of duplicate crawl errors
Im having over 400 crawl errors over duplicate content looking like this: http://www.mydomain.com/index.php?task=login&prevpage=http%3A%2F%2Fwww.mydomain.com%2Ftag%2Fmahjon http://www.mydomain.com/index.php?task=login&prevpage=http%3A%2F%2Fwww.mydomain.com%2Findex.php%3F etc.. etc... So there seems to be something with my login script that is not working, Anyone knows how to fix this? Thanks
Technical SEO | | stanken0 -

Page that has no link is being crawled
http://www.povada.com/category/filters/metal:Silver/nstart/1/start/1.htm I have no idea how the above page was even found by google but it seems that it is being crawled and Im not sure where its being found from. Can anyone offer a solution?
Technical SEO | | 13375auc30