After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Should I "no-index" two exact pages on Google results?
-
Hello everyone,
I recently started a new wordpress website and created a static homepage.
I noticed that on Google search results, there are two different URLs landing on same content page.
I've attached an image to explain what I saw.
Should I "no-index" the page url?
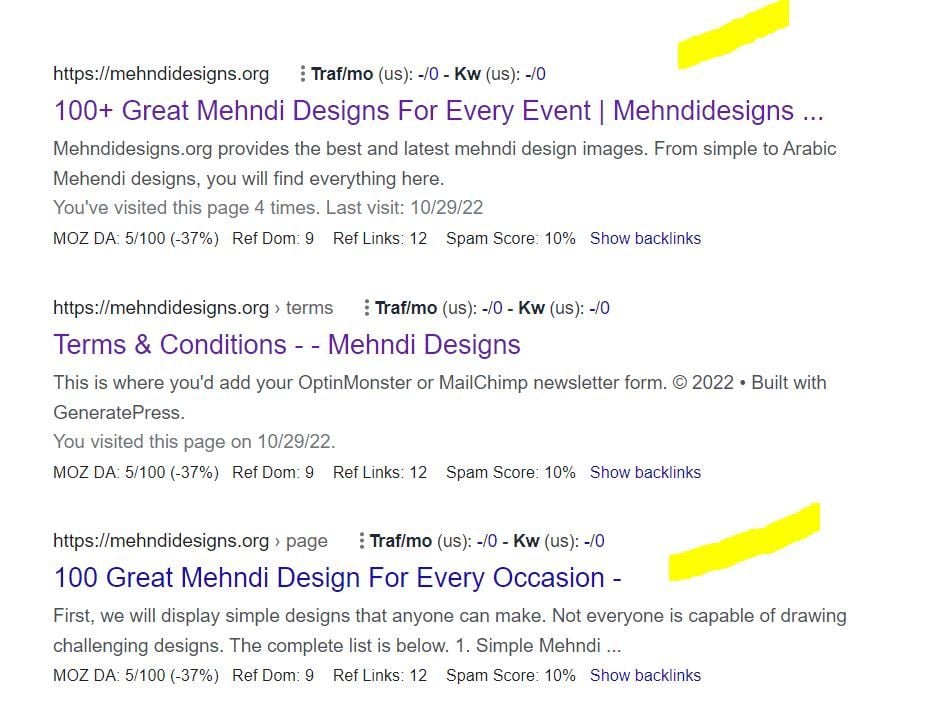
In this picture, the first result is the homepage and I try to rank for that page. The last result is landing on same content with different URL.
So, should I no-index last result as shown in image?
-
In any SEO plugin, you can go to edit the secondary article and in canonical URL you put the link to the home page.
-
@amanda5964 You can use canonical meta tag to tell google that those are the exact same pages. Google will index one of them which google choose best for the SERP.
-
Hi @amanda5964 actually could I ask if there is a reason for having these identical pages? You might want to consider simply combining the pages - i.e. deleting your sub page and redirecting to home if the content is identical.
-
I would not no-index. Typically it is more effective to use a canonical link from the secondary content to the main page you want the traffic directed to.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 141.1k
141.1k
-
 0102.6k
0102.6k
-
 031.4k
031.4k
-
 031.4k
031.4k
-
 031.5k
031.5k
-
 0104.7k
0104.7k
-
 092.1k
092.1k
-
 02310.3k
02310.3k