After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Schema Markup Validator vs. Rich Results Test
-
I am working on a schema markup project. When I test the schema code in the Schema Markup Validator, everything looks fine, no errors detected. However, when I test it in the Rich Results Test, a few errors come back.
What is the difference between these two tests? Should I trust one over the other? -
@Collegis_Education
Step-1
The Schema Markup Validator and the Rich Results Test are two distinct tools that serve different purposes in the context of schema markup. The Schema Markup Validator primarily focuses on validating the syntactical correctness of your schema code. It checks if your markup follows the structured data guidelines and is free from any syntax errors. This tool is useful during the initial stages of schema implementation to ensure that your code aligns with the schema.org specifications.Step-2
The Role of Rich Results Test
On the other hand, the Rich Results Test is designed to provide insights into how Google interprets your schema markup and whether it generates rich results in the search engine. It simulates Google's search results and displays how your content may appear as a rich result. This tool not only checks for syntactical correctness but also evaluates how well your schema markup aligns with Google's guidelines for generating enhanced search results. Therefore, it focuses more on the practical impact of your schema markup on search engine results.Step-3
Trusting the Results
Both tools are valuable in their own right. During the implementation phase, it's crucial to use the Schema Markup Validator to ensure your code's correctness. However, for a comprehensive understanding of how your schema markup will perform in search results, the Rich Results Test provides a more dynamic analysis. Trusting one over the other depends on your specific goals – the Schema Markup Validator for code validation and the Rich Results Test for evaluating the potential impact on search results. To illustrate, in my recent post I utilized schema markup, and both tools played a role in ensuring its accuracy and potential visibility in rich results. -
@Collegis_Education said in Schema Markup Validator vs. Rich Results Test:
I am working on a schema markup project. When I test the schema code in the Schema Markup Validator, everything looks fine, no errors detected. However, when I test it in the Rich Results Test, a few errors come back.
What is the difference between these two tests? Should I trust one over the other?When working with schema markup, it's important to understand the purpose of different testing tools and what aspects of your markup they're evaluating.
Schema Markup Validator (formerly known as Structured Data Testing Tool):
This tool focuses on checking the syntax and vocabulary of your schema markup against Schema.org standards.
It ensures that your markup is logically structured and semantically correct.
It does not necessarily check for compliance with Google's guidelines for rich snippets or rich results.
Rich Results Test:This tool is provided by Google and specifically checks for compatibility with Google Search's rich results.
It not only checks the validity of the schema markup but also whether it meets the specific guidelines and requirements set by Google to display rich results in its search engine.
It simulates how your page might be processed by Google Search and whether your schema can generate rich results.
The difference between the two tests lies in their scope. The Schema Markup Validator checks for general correctness according to Schema.org, which is broader and platform-agnostic. The Rich Results Test is more specific and checks for compatibility with Google's search features. I have used schema for internet packaging website and I found usful.Should you trust one over the other? It depends on your goals:
If you want to ensure your markup is correct according to Schema.org and potentially useful for a variety of search engines and platforms, the Schema Markup Validator is the way to go.
If your primary concern is how your markup will perform on Google Search and you're looking to leverage Google's rich results, then the Rich Results Test is more pertinent.
Ideally, your markup should pass both tests. It should be correctly structured according to Schema.org standards (which you can ensure using the Schema Markup Validator), and it should also be optimized for Google's rich results (which you can check using the Rich Results Test). If you're encountering errors in the Rich Results Test, it's likely because your schema markup doesn't meet some of Google's rich result guidelines, and you should adjust your markup accordingly. -
The Schema Markup Validator checks the syntax and structure of your schema code, ensuring it aligns with schema.org specifications. It's crucial for catching initial errors. On the other hand, the Rich Results Test specifically focuses on how your schema markup qualifies for rich results in Google Search, providing insights into how it appears in search results. For Google integration and visual representation, prefer the Rich Results Test. Use both tools together to ensure technical correctness and effective integration with Google's search algorithms.
-
The Schema Markup Validator primarily checks the technical correctness and adherence to schema.org standards of your structured data markup. It ensures that your markup is syntactically correct and follows the specified schema guidelines.
On the other hand, the Rich Results Test goes beyond syntax validation. It assesses how well your page qualifies for rich results (enhanced search results) in Google's search listings. This includes checking if your markup meets the specific requirements for generating rich snippets, knowledge panels, or other enhanced search features.
In essence, while the Schema Markup Validator focuses on the technical aspects of your markup, the Rich Results Test evaluates its potential impact on search results appearance. Both tools are valuable, and it's recommended to use them in conjunction to ensure comprehensive testing of your schema markup. If the Rich Results Test identifies errors, addressing them can enhance your chances of achieving rich results in Google's search listings.
-
@Hazellucy I will create the different Schemas for my movies related website. I will use the Rich result test tool that is work for me. But that is depend on you which one you want to use for creating schema code. Rich result is google official tool. So I recommend you to use this one.
-
I will create schemas for my movie related website. I will create different type of schema like FAQs and content schema and I will use more rich result test tool that is work for me.
-
This post is deleted! -
The primary difference between the Schema Markup Validator and the Rich Results Test from Google is that the Rich Result test is restricted to testing only the markup of structured data that's used in Google's results for the search. However, the Schema.org markup validation is more intended for "general purposes" and is geared towards debugging various other types of structured data in addition to the ones that Google supports.
Currently Google supports only a limited number of Schema Markups that includes:
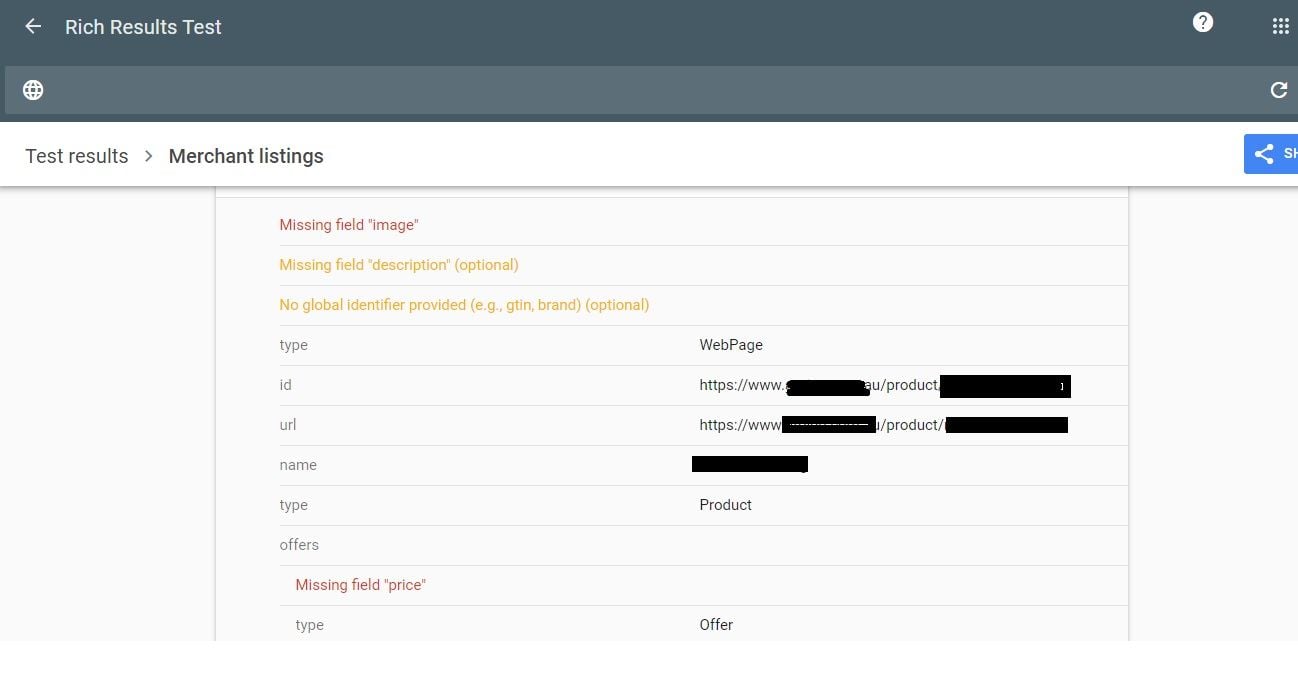
Article, Breadcrumb, Carousel, Course, COVID-19 Announcements, Dataset, Employer, Aggregate Rating, Estimated Salary, Event, Fast Check, FAQ, Home Activities, How-To, Image License, Job Posting, Job Training, Local Business, Logo, Math Solvers, Movie, Practice Problems, Product, Q&A, Recipe, Review Snippet, Sitelinks, Search Box, Software App, Speakable, Video, Subscription and Paywalled Content, Article / Blog Posting, etc.This means that the markup validator may be showing that there are no issues with the way your schema is written syntactically, but Google may still have an issue generating a particular type of search result based on that schema.
Both of the tools can still be used for better SEO and achieving featured results in the SERPs. The Rich Result Testing tool doesn’t offer the code editing option though, so the Schema Markup Validator tool can come in handy for troubleshooting any Schema markup issues.
There are a number of Data Types supported by the Google Rich Result Testing Tool for existing Schema Libraries supported by Google and those Data Types can be used when testing different types of the Schema markup through Schema Markup validator tool.
-
@kavikardos thank you, that's helpful!
-
Hey @collegis_education! The primary difference between the two tools is that the Rich Results Test shows what types of Google results can be generated from your markup, whereas the schema markup validator offers generic schema validation. So the markup validator may be showing that there are no issues with the way your schema is written syntactically, but Google may still have an issue generating a particular type of search result based on that schema.
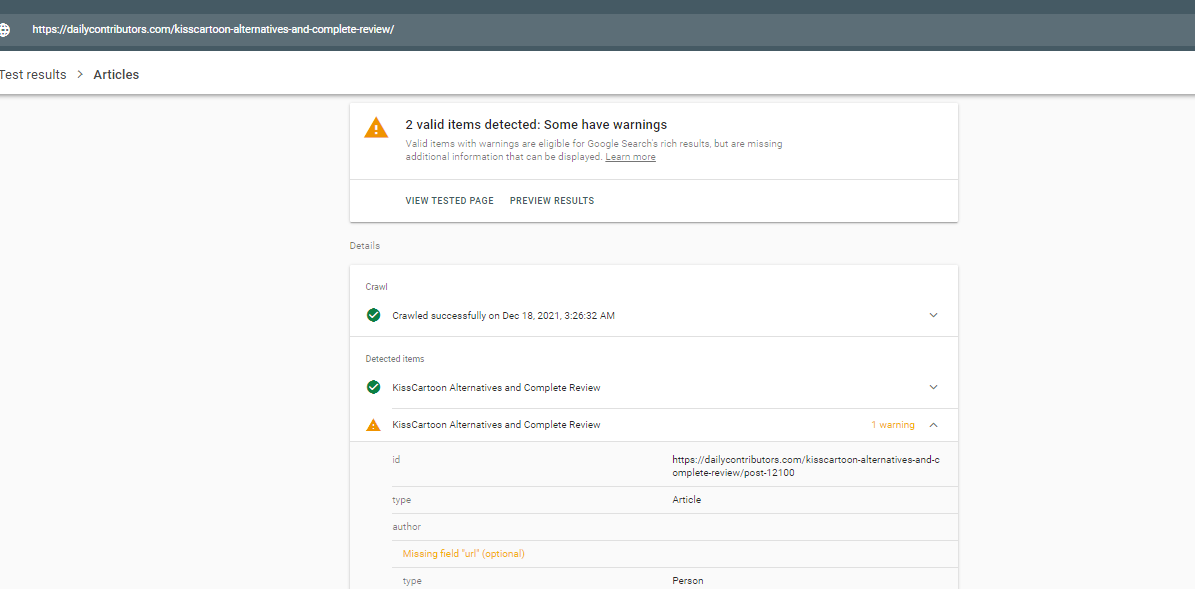
Be sure to take a close look at the errors the Rich Results Test is throwing, as some are more like warnings - not every aspect of the schema is necessary in order for Google to generate a rich result, but obviously if there's a particular piece of the markup that's missing (i.e. In-Stock status), it won't be included in that result.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 052.0k
052.0k
-
 072.0k
072.0k
-
 012.9k
012.9k
-
 624.3k
624.3k
-
 02885
02885
-
 344.1k
344.1k
-
 021.3k
021.3k