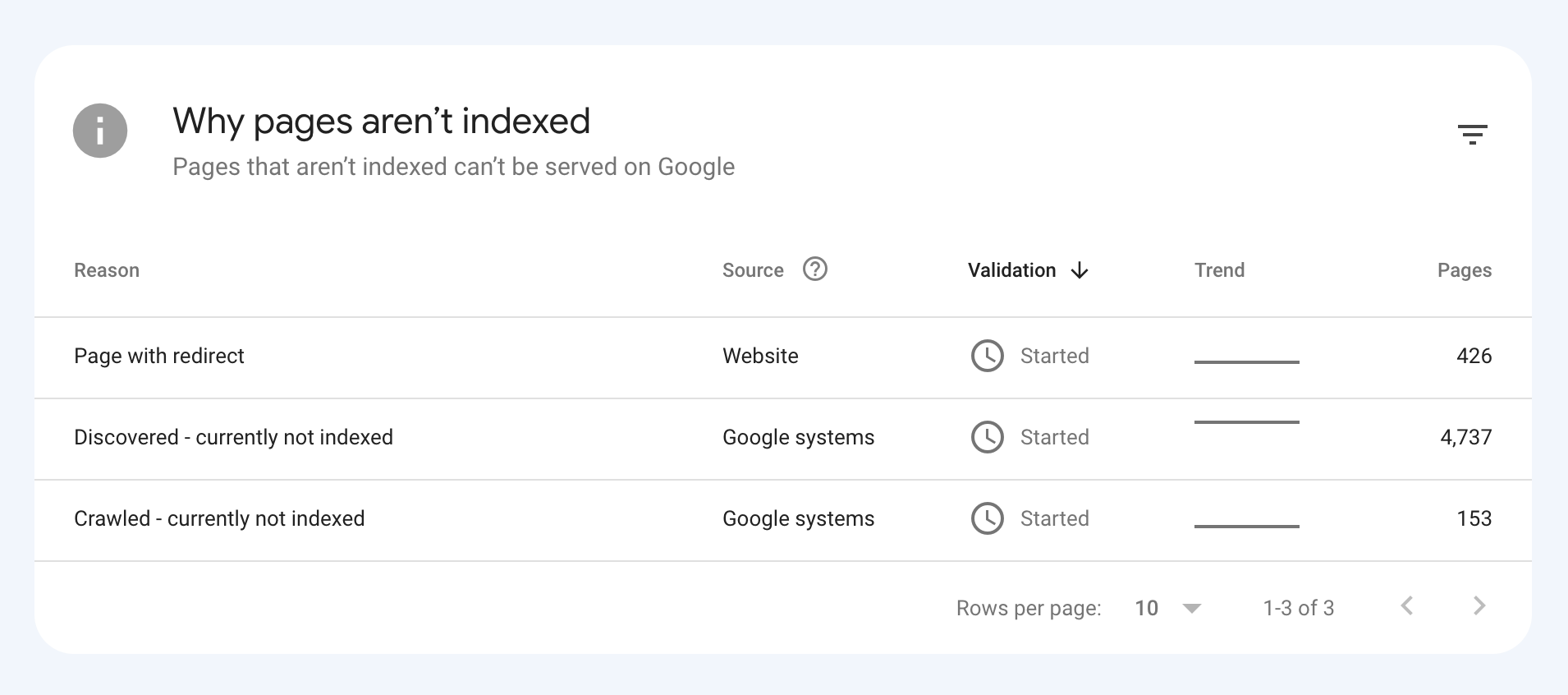
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Unsolved Capturing Source Dynamically for UTM Parameters
-
Does anyone have a tutorial on how to dynamically capture the referring source to be populated in UTM parameters for Google Analytics?
We want to syndicate content and be able to see all of the websites that provided referral traffic for this specific objective. We want to set a specific utm_medium and utm_campaign but have the utm_source be dynamic and capture the referring website.
If we set a permanent utm_source, it would appear the same for all incoming traffic.
Thanks in advance!
-
@peteboyd said in Capturing Source Dynamically for UTM Parameters:
Thanks in advance!
UTM (Urchin Tracking Module) parameters are tags that you can add to the end of a URL in order to track the effectiveness of your marketing campaigns. These parameters are used by Google Analytics to help you understand how users are interacting with your website and where they are coming from.
There are five different UTM parameters that you can use:
utm_source: This parameter specifies the source of the traffic, such as "google" or "Facebook".
utm_medium: This parameter specifies the medium of the traffic, such as "cpc" (cost-per-click) or "social".
utm_campaign: This parameter specifies the name of the campaign, such as "spring_sale" or "promotion".
utm_term: This parameter specifies the term or keywords used in the campaign, such as "shoes" or "dress".
utm_content: This parameter specifies the content of the ad, such as the headline or the call-to-action.
To capture the source dynamically for UTM parameters, you can use JavaScript to get the value of the document. referrer property. This property returns the URL of the page that is linked to the current page. You can then use this value to set the utm_source parameter dynamically.
For example, you might use the following code to set the utm_source parameter based on the referring URL:
Copy code
var utmSource = '';if (document.referrer.indexOf('google') !== -1) {
utmSource = 'google';
} else if (document.referrer.indexOf('facebook') !== -1) {
utmSource = 'facebook';
}// Add the utm_source parameter to the URL
var url = 'http://www.example.com?utm_source=' + utmSource;
This code will set the utm_source parameter to "google" if the user came to the page from a Google search or to "Facebook" if the user came to the page from Facebook. If the user came to the page from another source, the utm_source parameter will be left empty.You can then use this modified URL in your marketing campaigns to track the effectiveness of your campaigns and understand where your traffic is coming from.
-
@peteboyd you can refer to this tutorial: https://www.growwithom.com/2020/06/16/track-dynamic-traffic-google-tag-manager/
Should meet your requirements perfectly - using GTM to replace a static value with the url in your UTM Source.
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Explore more categories
-
Chat with the community about the Moz tools.
-
Discuss the SEO process with fellow marketers
-
Discuss industry events, jobs, and news!
-
Chat about tactics outside of SEO
-
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
-
-
 18539
18539
-
 091.3k
091.3k
-
 1152.7k
1152.7k
-
 021.3k
021.3k
-
 062.5k
062.5k
-
 021.7k
021.7k
-
 011.8k
011.8k
-
 033.6k
033.6k