Category: Technical SEO
Discuss site health, structure, and other technical SEO strategies.
-

HTTP to HTTPS Transition, Large Drop in Search Traffic
My URL is: https://www.seattlecoffeegear.comWe implemented https across the site on Friday. Saturday and Sunday search traffic was normal/slightly higher than normal (in analytics) and slightly down in GWT. Today, it has dropped significantly in both, to about half of normal search traffic. From everything we can see, we implemented this correctly. 301 redirected all http requests to https (and yes, they go to the correct page and not to the homepage 😉 ) Rewrote hardcoded internal links Registered/submitted sitemaps from https in Bing and GWT Used fetch and render to ensure Google could reach the site and also was redirected appropriately from http to https versions Ensured robots.txt does not block https or secure We also use a CDN (though I don't think that impacts anything) and have had no customer issues with accessing or using the website since the transition.Is there anything else I might be missing that could correlate to a drop in search impressions or is this just a waiting game of a few days to let Google sort through the change we've made and reindex everything (it dropped to 0 indexed for a day and is now up to 1744 of our 2180 pages indexed)?Thank you so much for any input!Kaylie
| Marketing.SCG0 -

No descripton on Google/Yahoo/Bing, updated robots.txt - what is the turnaround time or next step for visible results?
Hello, New to the MOZ community and thrilled to be learning alongside all of you! One of our clients' sites is currently showing a 'blocked' meta description due to an old robots.txt file (eg: A description for this result is not available because of this site's robots.txt) We have updated the site's robots.txt to allow all bots. The meta tag has also been updated in WordPress (via the SEO Yoast plugin) See image here of Google listing and site URL: http://imgur.com/46wajJw I have also ensured that the most recent robots.txt has been submitted via Google Webmaster Tools. When can we expect these results to update? Is there a step I may have overlooked? Thank you,
| adamhdrb
Adam 46wajJw0 -

Recovering from disaster
Short Question: What's the best way to get Google to re-index duplicate URLs? Long Story: We have a long ago (1997) established website with a proprietary CMS. Never paid much attention to SEO (other than creating a sitemap) until four months ago. After learning some we started modifying the engine to provide better site to google (proper HTTP codes, consistent URLs to eliminate duplicates - we had something like 15,000 duplicates - etc...) Things went great for three and half months and we reached the first page on google for our main keyword (very, very competitive keyword). Before the SEO we were getting around 25,000 impressions and 3000 clicks on google. After our SEO efforts, we reached 70,000 daily impressions and more than 7000 daily clicks. On Aug 30th, 2014, one of our programmers committed a change to the live server by mistake. This small change effectively changed every article's URL by adding either a dash at its end or a dash and a keyword '-test-keyword' (literally). Nobody noticed anything until two days later as the site worked perfectly for humans. The result of this small code change is that within five days our site practically disappeared from Google's results pages except when one searched for our site's name. Our rank dropped from 8 and 10 to 80 and 100 for our main keywords. We reverted the change as soon as we noticed the problem, but during those two days, Google's bots went on a binge crawling five times the usual number of page crawled per day. We've been trying to recover and nothing seems to be working so far. Google's bots aren't crawling the repaired URLs to get the 301 headers back to the original URL and now we still have over 2300 duplicates as reported by the webmaster tools. Our Google impressions and clicks dropped to way below what we had before we did any SEO, down to 5000 impressions and 1200 clicks (inclusive of our direct domain name search). During the last 15 days (after we fixed the problem), our duplicate count went from a maximum of 3200, down to 1200, then back up to 2300 without any changes on our end. we've redone our sitemap and resubmitted it on day 3. So, what do we do? Do we go through the URLs with 'fetch as Google' function? (that's a bit tedious for 2300 URLs) or we wait for the bots to come around whenever they feel like it? if we do this, should we submit the bad URL, have google fetch it, get the redirect, follow it and then submit the followed URL to the index? Or is there a better solution that I'm unaware of? Second question: Is this something to be expected when something like this happens knowing that our inbound link rarely link to the actual articles?
| Lazeez0 -

Hreflang and canonical for multi-language website
Hi all, We're about to have a new website in different languages and locations, which will replace the existing one. Lets say the domain name is example.com. the US version will be example.com/en-us/ and the UK version will be example.com/en-uk/. Some of the pages on both version share the same content. So in order to solve it, we're about to use hreflang on each page + a canonical tag which will always use the US address as canonical address. My question is - since we are using canonical tag along with hreflang, is there a possibility that a user who is searching with Google.co.uk will get the canonical US address instead of the UK address? Or maybe the search engine will know to display the right localized address since (UK) i've been using hreflang? It is really important for me to know, because i'm afraid we will lose the high rankings that we have right now on google.co.uk. Thanks in Advance
| Operad-LTD0 -

Should I be concerned about Google indexing an old domain if the listings redirect to the new domain?
I noticed this about Moz's old domain SEOMoz.org. If the URLs from the old domain are redirecting, is there any reason to be concerned about an old domain still appearing to be indexed by Google? See here: https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=site%3Aseomoz.org Links to seomoz.org are listed, but if you click them they redirect to moz.com. Is this anything to be concerned about or is everything operating as expected?
| 352inc0 -

High DA url rewrite to your url...would it increase the Ranking of a website?
Hi, my client use a recruiting management tool called njoyn.com. The url of his site look like: www.example.njoyn.com. Would it increase his ranking if I use this Url above that point to njoyn domain wich has a high DA, and rewrite it to his site www.example.com? If yes how? Thanks
| bigrat950 -

What is updowner-verification?
Every page of my website has these codes, what is updowner-verification and it's content code? (I bought a HTML template from a guy) <title>Title is here..</title>
| nopsts0 -

Big Increase in 404 Errors after Google Custom Search Engine Install on Website
My URL is: http://www.furniturefashion.comHi forum.I recently installed a Custom Google Search Engine (https://www.google.com/cse/) on my blog about ten days ago. Since then my 404 errors in Webmaster Tools has skyrocketed by several thousand. I had not had an issue before. Once it was installed the 404 errors started appearing. What's interesting is that all the errors have the URL then the word "undefined" at the end. I have attached a screen shot from my Webmaster Tools dashboard. Also, there are a few examples below of what the URLs are that have the 404 errors.wood_closet_organizer_to_improve_space_utilization/undefinedsmall-sweet-10-inspiring-small-kitchen-designs/undefined Has anyone had this issue? I very much want the search engine on my site, but not at the expense of several thousand 404 errors. My site queries has been going down since the installation of the custom search engine. Here is some of the code that I have below that I took off my site doing a "view source". Any help would be greatly appreciated.href='http://cdn.furniturefashion.com/wp-content/plugins/google-custom-search/css/smoothness/jquery-ui-1.7.3.custom.css?ver=3.9.2' type='text/css' media='all' />rel='stylesheet' id='gsc_style_search_bar-css' href='http://www.google.com/cse/style/look/minimalist.css?ver=3.9.2' type='text/css' media='all' />rel='stylesheet' id='gsc_style_search_bar_more-css' href='http://cdn.furniturefashion.com/wp-content/plugins/google-custom-search/css/gsc.css?ver=3.9.2' type='text/css' media='all' />< uXRSEkC
| will21120 -

Sitemap international websites
Hey Mozzers,Here is the case that I would appreciate your reply for: I will build a sitemap for .com domain which has multiple domains for other countries (like Italy, Germany etc.). The question is can I put the hreflang annotations in sitemap1 only and have a sitemap 2 with all URLs for EN/default version of the website .COM. Then put 2 sitemaps in a sitemap index. The issue is that there are pages that go away quickly (like in 1-2 days), they are localised, but I prefer not to give annotations for them, I want to keep clear lang annotations in sitemap 1. In this way, I will replace only sitemap 2 and keep sitemap 1 intact. Would it work? Or I better put everything in one sitemap?The second question is whether you recommend to do the same exercise for all subdomains and other domains? I have read much on the topic, but not sure whether it worth the effort.The third question is if I have www.example.it and it.example.com, should I include both in my sitemap with hreflang annotations (the sitemap on www.example.com) and put there it for subdomain and it-it for the .it domain (to specify lang and lang + country).Thanks a lot for your time and have a great day,Ani
| SBTech0 -

Hreflang tag implentation
Hi, We've had hreflang tags implemented on our site for a few weeks now, and while we are seeing some improvements for the regional subfolders I wanted to double check I had the tags implemented correctly (a couple of examples are below). However while the regional subfolder sites are now ranking instead of the US site for some keywords, some key search terms are still returning the US site. Could this be due to incorrect implementation for that specific page? Due to complications with using Magento we're implementing the tags in the site maps. Also magento appears to be inserting a rel canonical tag automatically for each page and self referencing e.g. On www.example.com/uk/security-cameras (one of the pages we're having issues with) the canonical tag is http://www.example.com/uk/security-cameras" />. Is this an issue? Any advice would be appreciated. Thanks. <url><loc>http://www.example.com/uk/dvrs-kits</loc>
| ahyde
<lastmod>2014-07-23</lastmod>
<changefreq>daily</changefreq>
<priority>0.5</priority></url>
<url><loc>http://www.example.com/uk/dvrs-kits/1080p</loc>
<lastmod>2014-07-23</lastmod>
<changefreq>daily</changefreq>
<priority>0.5</priority></url>0 -

How to stop google from indexing specific sections of a page?
I'm currently trying to find a way to stop googlebot from indexing specific areas of a page, long ago Yahoo search created this tag class=”robots-nocontent” and I'm trying to see if there is a similar manner for google or if they have adopted the same tag? Any help would be much appreciated.
| Iamfaramon0 -
PA & DA High But Serp results are not so higher.
Keyword is "iPhone Service" , URL is youtube.com/iPhoneServiceJoo , meta is revenant again contains "iPhone Service" PA: 33
| nopsts
DA:96 this is youtube channel. This page is on second page of google, (24th) Why other PA and DA lower pages/sites are showing first? (my competitors) So this is not about PA & DA right?0 -

Too Many Links?
Search Term is Indianapolis Wedding Photographers. Site is http://www.tallandsmallphotography.com/ Their metrics are through the roof compared to everyone else's. They've dropped from 27 in May to 40 Now. 'A' Grade on-site optimization. Either there's too many links, or there's some bad links involved... I don't know which it is...
| WilliamBay0 -

Pagination Help
Hi Moz Community, I've recently started helping a new site with their overall health and I have some pagination issues. It's an ecommerce site and they currently don't have any pagination in place except for these tags: Prev 1 2 3 ... 66 Next I understand what these are doing (leading visitors to the previous, next or last page, but do these do anything for search crawlers or does the site need to have an option of:
| IceIcebaby
1.rel=next/rel=prev
2.canonical leading to the view all page (the view all page takes a long time to load) Thanks for your help. -Reed0 -

Redirects on multi language site and language detection
Hello! I have a multi language site in German and English. The site ranked well for the brand name and for German keywords. But after switching to a contend delivery network and changing the language detection method from browser language to IP location the site had indexing and ranking problems. Also in SERP the English homepage is shown for German keywords. On the other hand the language detection method is more accurate now. Current setup: The languages are separated via a folder structure for the languages: www.site.com/**en **and www.site.com/de. If the users IP is in Germany he is redirected via 302 from .com to .com/de. The rest of the world is redirected via 302 to .com/en. So the root www.site.com/ doesn't exist but has the most of the backlinks. Each folder has one sitemap under /de/sitemap.xml and /en/sitemap.xml. Each site and the root (.com, .com/de, .com/en) was added to WMT (no geo targeting) and the sitemaps were added (on the root domain both sitemaps and on the language specific sites just one). The sitemaps have no hreflang tag. Each page has an hreflang tag in the header pointing to itself and the alternate language. hreflang="x-default" is not set anywhere. Also on each page is a link to change language. Goals: From an SEO point of view we primarily target German speaking people. But a lot of international people (US, South America, Europe) search for our brand name so we want to serve them the English site. Therefore we want to: Get all the link juice when someone links to www.site.com to the German site Show Germans the German site in SERP and all others the English one Still serve the language automatically based on the location Do you have any idea how to achieve this? I think our main problem is that we want to push the German site the most but still serve the English site for most people (and therefore the Google Bot). Also does submitting the same sitemap twice (on the domain site and folders) do any harm? Any help oder links to ressources are greatly appreciated. I read a ton of articles but they are mostly for the case that english is the default language. Thanks for you help Moz community! Alex
| AlexBLN1 -

Google Cache showing a different URL
Hi all, very weird things happening to us. For the 3 URLs below, Google cache is rendering content from a different URL (sister site) even though there are no redirects between the 2 & live page shows the 'right content' - see: http://webcache.googleusercontent.com/search?q=cache:http://giltedgeafrica.com/tours/ http://webcache.googleusercontent.com/search?q=cache:http://giltedgeafrica.com/about/ http://webcache.googleusercontent.com/search?q=cache:http://giltedgeafrica.com/about/team/ We also have the exact same issue with another domain we owned (but not anymore), only difference is that we 301 redirected those URLs before it changed ownership: http://webcache.googleusercontent.com/search?q=cache:http://www.preferredsafaris.com/Kenya/2 http://webcache.googleusercontent.com/search?q=cache:http://www.preferredsafaris.com/accommodation/Namibia/5 I have gone ahead into the URL removal Tool and got denied for the first case above ("") and it is still pending for the second lists. We are worried that this might be a sign of duplicate content & could be penalising us. Thanks! ps: I went through most questions & the closest one I found was this one (http://moz.com/community/q/page-disappeared-from-google-index-google-cache-shows-page-is-being-redirected) but it didn't provide a clear answer on my question above
| SouthernAfricaTravel0 -

Multiple H1 tags on same page
Hi Mozers I have a doubt regarding H1 tags. I know H1 tags will not give some special SEO value. But is there any issue if we are using multiple H1 tags on a same page? For example on the seomoz.org blog home page I saw 16 H1 tags (seomoz.org/blog). Is that ok to use like that? Can I completely ignore all my worries about H1 tags?
| riyas_heych0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
| Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
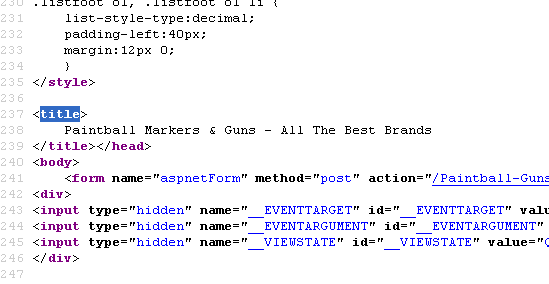 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Meta keywords shown in Google SERPS as site description
I'm seeing Google display meta-keywords in the SERP description for some sites (at least a half dozen that I've checked). I BELIEVE IT IS AN AJAX ISSUE BECAUSE: The sites all use AJAX to display content. So the meta-keywords are in the header, and the javascript that displays the content. Non-AJAX parts of the site display properly in Google SERPS The meta-keywords don't visibly appear anywhere on the page. When I turn off images and Javascript in Chrome I don't see any hidden keyword text. I BELIEVE IT IS A GOOGLE-SPECIFIC ISSUE BECAUSE: Each site displays properly in Bing and Yahoo SERPS - the meta-description is the description. However, (as expected) I see the same strange meta-keyword activity in Aol search In Screaming Frog's SERP preview I see the meta-description as the description. Google has been ignoring met-keywords for years. Any idea why it's appearing in the SERPS for these AJAX powered sites? I found one other person who saw that Google may be reading and displaying their content in AJAX even though that content is meant to appear on a different "page". No one on that Google Forum seemed to understand the person's problem. The only reason I get it is because now I'm seeing it with my own eyes. I know the Moz community can do better, so i'm posting about it here.
| AlexCobb0 -
Why are these internal pages not showing any internal links?
If you look at Author profile pages like this one, http://experts.allbusiness.com/author/denise-oberry (THE top contributor on the site with over 82 posts under her belt), or any Author profile page, they show zero internal links or Page Authority. The same goes for most posts for each author on the site. Author pages should show internal links from every post the author has on the site. And specific posts should also have internal links from categories, etc. Yet they show zero. The only posts that show internal links and PA are ones that were either syndicated to the root domain's homepage, or syndicated to Fox Small Business. ZERO internal links. Does anyone know why this is? The root domain does not act this way with Author pages and posts. And I see nothing blocking links or indexing via the robots.txt file or page level nofollow tags. A real head scratcher for this SEO nerd, that I'm sure someone here will have a really simple answer to.
| MiguelSalcido0 -

Does Anyone Know How Linstant Works??
I recently installed Linkstant after reading lots of great reviews. I'm eager to use the new tool, but I would like to know HOW it works. Does it send Google queries?? Just to give you some background info, I was recently burned by Rank Tracker...after using the tool it killed any access to Google and ruined a Google+ event that our company had planned. I do not want this to happen again, so I'd like to know how exactly it works. Thanks!
| TMI.com0 -

Migrating domains from a domain that will have new content.
We have a new url. The old url is being taken over by someone else. Is it possible to still have a successful redirect/migration strategy if we are redirect from our old domain, which is now being used by someone else. I see a big mess, but I'm being told we can redirect all the links to our old content (which is now used by someone else) to our new url. Thoughts? craziness? insanity? Or I'm just not getting it:)
| CC_Dallas0 -

Problems with to many indexed pages
A client of our have not been able to rank very well the last few years. They are a big brand in our country, have more than 100+ offline stores and have plenty of inbound links. Our main issue has been that they have to many indexed pages. Before we started we they had around 750.000 pages in the Google index. After a bit of work we got it down to 400-450.000. During our latest push we used the robots meta tag with "noindex, nofollow" on all pages we wanted to get out of the index, along with canonical to correct URL - nothing was done to robots.txt to block the crawlers from entering the pages we wanted out. Our aim is to get it down to roughly 5000+ pages. They just passed 5000 products + 100 categories. I added this about 10 days ago, but nothing has happened yet. Is there anything I can to do speed up the process of getting all the pages out of index? The page is vita.no if you want to have a look!
| Inevo0 -

Off-site company blog linking to company site or blog incorporated into the company site?
Kind of a SEO newbie, so be gentle. I'm a beginner content strategist at a small design firm. Currently, I'm working with a client on a website redesign. Their current website is a single page dud with a page authority of 5. The client has a word press blog with a solid URL name, a domain authority of 100 and page authority of 30. My question is this: would it be better for my client from an SEO perspective to: Re-skin their existing blog and link to the new company website with it, hopefully passing on some of its "Google Juice,"or... Create a new blog on their new website (and maybe do a 301 redirect from the old blog)? Or are there better options that I'm not thinking of? Thanks for whatever help you can give a newbie. I just want to take good care of my client.
| TheKatzMeow0 -

Why is Google replacing our title tags with URLs in SERP?
Hey guys, We've noticed that Google is replacing a lot of our title tags with URLs in SERP. As far as we know, this has been happening for the last month or so and we can't seem to figure out why. I've attached a screenshot for your reference. What we know: depending on the search query, the title tag may or may not be replaced. this doesn't seem to have any connection to the relevance of the title tag vs the url. results are persistent on desktop and mobile. the length of the title tag doesn't seem to correlate with the replacement. the replacement is happening at mass, to dozens of pages. Any ideas as to why this may be happening? Thanks in advance,
| Mobify
Peter mobify-site-www.mobify.com---Google-Search.png0 -

URL Path to Store Article Library for SEO
What is the best URL structure for a domain to start adding a main directory for educational articles under? We want to find the best URL structure to keep articles under as a main, then category, then subcategory: For example, if my client is going after TWO SPECIFIC KEYWORD PHRASES as their primary (let's say they are KIDNEY DIALYSIS and CKD DIALYSIS, should they start building up their article library (for educational purposes as well as ranking/SEO), should they list it under which structure for the best SEO ranking opportunities: domain.com/KIDNEY-DIALYSIS/article1, article2, article3 domain.com/CKD-DIALYSIS/article1, article2, article3 domain.com/ARTICLES/article1, article2, article3 Both KIDNEY DIALYSIS and CKD DIALYSIS are critical phrases for them. Is it a waste of URL space to just have a home of domain.com/ARTICLES then build off that URL structure like: domain.com/articles/kidney-dialysis domain.com/articles/ckd-dialysis Thoughts? Ideas? Thank you!
| ErnieB0 -

Last Part Breadcrumb Trail Active or Non-Active
Breadcrumbs have been debated quite a bit in the past. Some claim that the last part of the breadcrumb trail should be non-active to inform users they have reached the end. In other words, Do not link the current page to itself. On the other hand, that portion of the breadcrumb would won't be displayed in the SERPS and if it was may lead to a higher CTR. Foe example: www.website.com/fans/panasonic-modelnumber panasonic-modelnumber would not be active as part of the breadcrumb. What is your take?
| CallMeNicholi0 -

Keyword rich domain name and page title
Hi guys, First of all, I must say I love this community, and that SEO is great and at time fascinating :d Ok my question now is, I have this domain which is keyword rich, later I noticed Google changed my pages title into something else but similar, also added my domain name (mysite.com) in the titles. Google had taken some of his auto-title-suggestions from inside my pages, later i changed them and saw google changed the titles too accordingly, nice work google ) So I figured this tile name changing is because my domain is already keyword rich, right? so the best practice is, I create a more unique descriptive title + my domain name at the end of the title. (And for homepage, domain name .com at the beginning in the title. What do you think? Thanks for your thoughts!
| mdmoz0 -

Sudden drop in Rankings after 301 redirect
Greetings to Moz Community. Couple of months back, I have redirected my old blog to a new URL with 301 redirect because of spammy links pointed to my old blog. I have transfer all the posts manually, changed the permalink structure and 301 redirected every individual URL. All the ranking were boosted within couple of weeks and regained the traffic. After a month I have observed, the links pointed to old site are showing up in Webmaster Tools for the new domain. I was shocked (no previous experience) and again Disavowed all links. Today, all the positions went down for new domain. My questions are: 1. Did the Disavow tool worked this time with new domain? All the links pointed to old domain were devaluated? Is this the reason for ranking drop? Or 2. 301 Old domain with Unnatural links causes the issue? 3. Removing 301 will help to regain few keyword positions? I'm taking this as a case study. Already removed the 301 redirect. Looking for solid discussion.Thanks.
| praveen4390 -

Has anyone tested or knows whether it makes a difference to upload a disavow file to both www. and non-www. versions of your site in GWMT?
Although Google treats both as separate sites, I always assumed that uploading the disavow file to the canonical version of your site would solve the problem. Is this the case, or has anyone seen better results uploading to both versions?
| CustardOnlineMarketing0 -

Parked Domains
I have a client who has a somewhat odd situation for their domains. They've been really inconsistent with how they've used them over the years, which makes for a slightly sticky situation. The client has two domains: compname.com and fullcompanyname.com. Right now, their website is just HTML (no CMS) and all of the URLs are relative, so both domains work. Since the new website will be in WordPress, they need to commit to one domain as the primary. Right now, it looks like compname.com is the one they've used the most in ads and such, so I'm going to recommend they go with that. However, the client has also used fullcompanyname.com a lot. They don't want to have to setup individual 301 redirects for everything. I think it's ridiculous, but you can lead a horse to water... Our developer has done some research and he may have found a solution that will satisfy the client. I just want to find out if there are any SEO implications. The possible plan is to us compname.com as the primary domain and to park fullcompanyname.com. That way, if someone visits fullcompanyname.com/products/my-favorite-product, it will still work without having to setup 301 redirects. Since the domain is parked, Google won't recognize it as duplicate content, correct? Just to be clear on the whole situation, I'm insisting that all of the website URLs need 301 redirects, regardless of the domain. The primary concern is with a lot of other stuff on the server that isn't related to the site (email campaign landing pages, image files, assets that are pulled in by the client's software, etc.). The client's concern is about redirecting all that other stuff (and there is a lot of it--thousands of files). The parked domain would seem to fix that, but I want to make sure that the client won't get Google slapped.
| BopDesign0 -

Manual Action - When requesting links be removed, how important to Google is the address you're sending the requests from?
We're starting a campaign to get rid of a bunch of links, and then submitting a disavow report to Google, to get rid of a manual action. My SEO vendor said he needs an @email domain from the website in question @travelexinsurance.com, to send and receive emails from vendors. He said Google won't consider the correspondence to and from webmasters if sent from a domain that is not the one with the manual action penalty. Due to company/compliance rules, I can't allow a vendor not in our building to have an email address like that. I've seen other people mention they just used a GMAIL.com account. Or we could use a similar domain such as @travelexinsurancefyi.com. My question, how critical is it that the domain the correspondence with the webmasters be from the exact website domain?
| Patrick_G0 -

I am having an issue with my rankings
I am having an issue with my rankings. I am not sure if there are issues with onpage dup content or with the way wordpress is behaving but there is no reason based upon the sites back link profile that the site shouldn't be ranking well. The site is mesocare.org. If anyone can help it would be appreciated.
| weitzluxenberg0 -

Best Joomla SEO Extensions?
My website is a Joomla based website. My designer is good, but I don't think he knows that much about SEO . . . so I doubt if he added any extensions that can assist with SEO. I assume there are some good ones that can help my site. Does anyone know what/which Joomla extensions are must haves?
| damon12120 -

Image Impression Drop
On August 8th we started to see our Image Impressions in Google Webmaster Tools start to plummet. Has anyone else run into this issue? I have not been able to find any news on Google Algos which my have caused this. Any other ideas what could have caused this? jxPmLwO
| joebuilder0 -

Script for Schema
Does any one know of any script that can be written to generate schema on my product pages. I need something that would be compatible with a custom php website. Here is an example of what I am looking for, it's for Magento so I can't use it: http://www.magentocommerce.com/magento-connect/schema-org.html. Or, if you have any idea on how to do implement schema without doing it manually please let me know here! Thanks!
| WSteven0 -

SSl and SEO
Does the type of SSL used on a site have any significance to trust and seo ranking?
| unikey0 -

Lots of backs links from Woorank reported by GWT
Hello We just sow a lots of links from woorank website ( 138 ) reported in our "Links to your site" at google webmaster tools, do you think we should consider add to submit that website for disavow in google webmaster tools ? Rgds
| helpgoabroad0 -

Site structure headache
Hello all, I'm struggling to get to grips with a websites site structure. I appreciate that quality content is key etc, and the more content the better, but then I have issues with regards to doorway pages. For example im now starting to develop a lot of ecommerce websites and want to promote this service. should we have pages that detail all of the ins and outs of ecommerce - or should we simplify it to a couple of pages. what is best practice? Also isn't a content hub similar to having doorway pages? let me know what you think! William
| wseabrook0 -

Search Term not appearing in On-Page Grader but is in code?
Hi, I have never had this issue in the past, but I am working on a website currently which is - http://hrfoundations.co.uk I didn't develop this website and the pages are in separate folders on the FTP which I have never come across before but hey ho. Anyway I have added the search term (HR Consultancy West Midlands) to the about us page in the h1, title and description however when I run the On-Page Grader it only says that I have entered it within the body which I haven't even done yet. When I view the page source it has defiantly been uploaded and the search terms are there, I have tried checking the spelling incase I spelt it incorrectly and I still can't seem to find the issue. Has anyone else experience this in the past, I'm going to go away now and check the code for any unclosed divs etc to see if that may be causing any issue's. Thanks Chris
| chrissmithps0 -

Will links be counted?
We are considering a redesign of our website and one of the options we are considering is to come up with something along the lines of http://www.tesco.com/, with rotating top offers. The question I am wondering is whether or not the links (ie. the blue links on the left side of the main graphic) will be visible to the spiders, and if not, whether there is a way to code it so they are?
| simonukss0 -

Added 301 redirects, pages still earning duplicate content warning
We recently added a number of 301 redirects for duplicate content pages, but even with this addition they are still showing up as duplicate content. Am I missing something here? Or is this a duplicate content warning I should ignore?
| cglife0 -

How Many Words To Make Content 'unique?'
Hi All, I'm currently working on creating a variety of new pages for my website. These pages are based upon different keyword searches for cars, for example used BMW in London, Used BMW in Edinburgh and many many more similar kinds of variations. I'm writing some content for each page so that they're completely unique to each other (the cars displayed on each page will also be different so this would not be duplicated either). My question is really, how much content do you think that I'll need on each page? or what is optimal? What would be the minimum you might need? Thank for your help!
| Sandicliffe0 -

Best Practice - Disavow tool for non-canonical domain, 301 Redirect
The Situation: We submitted to the Disavow tool for a client who (we think) had an algorithmic penalty because of their backlink profile. However, their domain is non-canonical. We only had access to http://clientswebsite.com in Webmaster Tools, so we only submitted the disavow.txt for that domain. Also, we have been recommending (for months - pre disavow) they redirect from http://clientswebsite.com to http://www.clientswebsite.com, but aren't sure how to move forward because of the already submitted disavow for the non-www site. 1.) If we redirect to www. will the submitted disavow transfer or follow the redirect? 2.) If not, can we simply re-submit the disavow for the www. domain before or after we redirect? Any thoughts would be appreciated. Thanks!
| thebenro0 -

Rel="canonical" What if there is no header??
Hi Everyone! Thanks to moz.com, I just found out that we have a duplicate content issue: mywebsite.com and mywebsite.com/index.php have the same content. I would like to make mywebsite.com the main one because it already has a few links and a better page rank. I know how to do a 301 redirect (already have one for www.mywebsite.com) but I am aware that a 301 redirect for my index file would create a loop issue. I have read the article about redirecting without creating a loop (http://moz.com/blog/apache-redirect-an-index-file-to-your-domain-without-looping) but quite frankly I don't even have a clue what he's trying to tell me (e.g. "Create an apache DirectoryIndex directive for your document root." What????!)… So I figured a rel="canonical" tag for my index file would be easier and fix the problem, too (right??) In every "How to" description they always say you have to put the rel="canonical" tag in the header of your duplicate content file. But: My index.php has no header (or nothing that looks like a header to me)! This is what it looks like: foreach($_GET as $key => $value)
| momof4
{
$$key = $value;
}
foreach($_POST as $key => $value)
{
$$key = $value;
}
$page_title="my title";
$page_description="my description";
$page_keywords="keywords";
//echo $link;
//exit;
if (!isset($link)):
$page_content="homepage.php";
else:
if ($link=="services"):
$page_content="services.php";
$page_title=" my title for services page";
$page_description="description for services.";
endif;
… ect. for the other pages So where do I put the rel=canonical tag? Or is there another solution for the whole problem? Like delete the whole index file (lol) Thanks in advance for any answers!0 -

Fake Links indexing in google
Hello everyone, I have an interesting situation occurring here, and hoping maybe someone here has seen something of this nature or be able to offer some sort of advice. So, we recently installed a wordpress to a subdomain for our business and have been blogging through it. We added the google webmaster tools meta tag and I've noticed an increase in 404 links. I brought this up to or server admin, and he verified that there were a lot of ip's pinging our server looking for these links that don't exist. We've combed through our server files and nothing seems to be compromised. Today, we noticed that when you do site:ourdomain.com into google the subdomain with wordpress shows hundreds of these fake links, that when you visit them, return a 404 page. Just curious if anyone has seen anything like this, what it may be, how we can stop it, could it negatively impact us in anyway? Should we even worry about it? Here's the link to the google results. https://www.google.com/search?q=site%3Amshowells.com&oq=site%3A&aqs=chrome.0.69i59j69i57j69i58.1905j0j1&sourceid=chrome&es_sm=91&ie=UTF-8 (odd links show up on pages 2-3+)
| mshowells0 -

Do I need to verify my site on webmaster both with and without the "www." at the start?
As per title, is it necessary to verify a site on webmaster twice, with and without the "www"? I only ask as I'm about to submit a disavow request, and have just read this: NB: Make sure you verify both the http:website.com and http://www.website.com versions of your site and submit the links disavow file for each. Google has said that they view these as completely different sites so it’s important not to forget this step. (here) Is there anything in this? It strikes me as more than a bit odd that you need to submit a site twice.
| mgane0 -

Can I use high ranking sites to push my competitors out of the first page of search results?
I'm looking at a bunch of long tail low traffic keywords that aren't difficult to rank for. As I was idly doing a boring task my mind wandered and I thought.... Why don't I ask lots of questions about these keywords on sites such as Moz, Quora, Reddit etc where the high DA will get them to rank for the search term? The results on a SEO site or Q&A site won't be relevant and so I'd starve my competitors of some of their leads. Of course I'm not sure the effort would be worth it but would it work? (and no, none of my long tail keywords are included in this post)
| Zippy-Bungle3 -

Which way round to 301 redirect?
Hi We have just added a new layered navigation menu to our website. so for example we had Before : www.tidy-books.co.uk/chidlrens-bookcases (this has the seo juice) And Now: http://www.tidy-books.co.uk/childrens-bookcases-book-storage/childrens-bookcases Might be a stupid question but do I redirect the 'now' url to the 'before' url or the the other way round I look forward to hearing your thoughts Thanks
| tidybooks0 -

Google dropping pages from SERPs even though indexed and cached. (Shift over to https suspected.)
Anybody know why pages that have previously been indexed - and that are still present in Google's cache - are now not appearing in Google SERPs? All the usual suspects - noindex, robots, duplication filter, 301s - have been ruled out. We shifted our site over from http to https last week and it appears to have started then, although we have also been playing around with our navigation structure a bit too. Here are a few examples... Example 1: Live URL: https://www.normanrecords.com/records/149002-memory-drawings-there-is-no-perfect-place Cached copy: http://webcache.googleusercontent.com/search?q=cache:https://www.normanrecords.com/records/149002-memory-drawings-there-is-no-perfect-place SERP (1): https://www.google.co.uk/search?q=memory+drawings+there+is+no+perfect+place SERP (2): https://www.google.co.uk/search?q=memory+drawings+there+is+no+perfect+place+site%3Awww.normanrecords.com Example 2: SERP: https://www.google.co.uk/search?q=deaf+center+recount+site%3Awww.normanrecords.com Live URL: https://www.normanrecords.com/records/149001-deaf-center-recount- Cached copy: http://webcache.googleusercontent.com/search?q=cache:https://www.normanrecords.com/records/149001-deaf-center-recount- These are pages that have been linked to from our homepage (Moz PA of 68) prominently for days, are present and correct in our sitemap (https://www.normanrecords.com/catalogue_sitemap.xml), have unique content, have decent on-page optimisation, etc. etc. We moved over to https on 11 Aug. There were some initial wobbles (e.g. 301s from normanrecords.com to www.normanrecords.com got caught up in a nasty loop due to the conflicting 301 from http to https) but these were quickly sorted (i.e. spotted and resolved within minutes). There have been some other changes made to the structure of the site (e.g. a reduction in the navigation options) but nothing I know of that would cause pages to drop like this. For the first example (Memory Drawings) we were ranking on the first page right up until this morning and have been receiving Google traffic for it ever since it was added to the site on 4 Aug. Any help very much appreciated! At the very end of my tether / understanding here... Cheers, Nathon
| nathonraine0
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.